
至此我们知晓了引用计数的优点就是实现简单,并且内存清理及时,缺点就是无法处理循环引用,不过可以结合标记-清除等方案来兜底,保证垃圾回收的完整性。
所以 Python 没有解决引用计数的循环引用问题,只是结合了非传统的标记-清除方案来兜底,算是曲线救国。

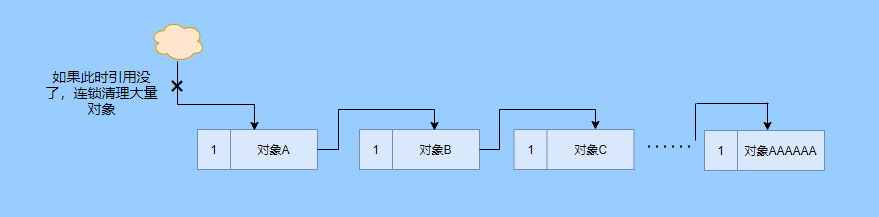
其实极端情况下引用计数也不会那么及时,你想假如现在有一个对象引用了另一个对象,而另一个对象又引用了另一个,依次引用下去。
那么当第一个对象要被回收的时候,就会引发连锁回收反应,对象很多的话这个延时就凸显出来了。
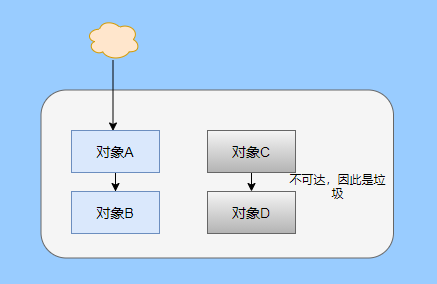
可达性分析其实就是利用标记-清除(mark-sweep),就是标记可达对象,清除不可达对象。至于用什么方式清,清了之后要不要整理这都是后话。
标记-清除具体的做法是定期或者内存不足时进行垃圾回收,从根引用(GC Roots)开始遍历扫描,将所有扫描到的对象标记为可达,然后将所有不可达的对象回收了。
所谓的根引用包括全局变量、栈上引用、寄存器上的等。
看到这里大家不知道是否有点感觉,我们会在内存不足的时候进行 GC,而内存不足时也是对象最多时,对象最多因此需要扫描标记的时间也长。
所以标记-清除等于把垃圾积累起来,然后再一次性清除,这样就会在垃圾回收时消耗大量资源,影响应用的正常运行。
所以才会有分代式垃圾回收和仅先标记根节点直达的对象再并发 tracing 的手段。
但这也只能减轻无法根除。
我认为这是标记-清除和引用计数的思想上最大的差别,一个攒着处理,一个把这种消耗平摊在应用的日常运行中。
而不论标记-清楚还是引用计数,其实都只关心引用类型,像一些整型啥的就不需要管。
所以 JVM 还需要判断栈上的数据是什么类型,这里又可以分为保守式 GC、半保守式 GC、和准确式 GC。
保守式 GC保守式 GC 指的是 JVM 不会记录数据的类型,也就是无法区分内存上的某个位置的数据到底是引用类型还是非引用类型。