
TCP并不是把应用层传输过来的数据直接加上首部然后发送给目标,而是把数据看成一个字节 流,给他们标上序号之后分部分发送。这就是TCP的 面向字节流 特性:
TCP会以流的形式从应用层读取数据并存放在自己的发送缓存区中,同时为这些字节标上序号
TCP会从发送方缓冲区选择适量的字节组成TCP报文,通过网络层发送给目标
目标会读取字节并存放在自己的接收方缓冲区中,并在合适的时候交付给应用层
面向字节流的好处是无需一次存储过大的数据占用太多内存,坏处是无法知道这些字节代表的意义,例如应用层发送一个音频文件和一个文本文件,对于TCP来说就是一串字节流,没有意义可言,这会导致粘包以及拆包问题,后面讲。
可靠传输原理前面讲到,TCP是可靠传输协议,也就是,一个数据交给他,他肯定可以完整无误地发送到目标地址,除非网络炸了。他实现的网络模型如下:
对于应用层来说,他就是一个可靠传输的底层支持服务;而运输层底层采用了网络层的不可靠传输。虽然在网络层甚至数据链路层就可以使用协议来保证数据传输的可靠性,但这样网络的设计会更加复杂、效率会随之降低。把数据传输的可靠性保证放在运输层,会更加合适。
可靠传输原理的重点总结一下有:滑动窗口、超时重传、累积确认、选择确认、连续ARQ 。
停止等待协议要实现可靠传输,最简便的方法就是:我发送一个数据包给你,然后你跟我回复收到,我继续发送下一个数据包。传输模型如下:
这种“一来一去”的方法来保证传输可靠就是停止等待协议(stop-and-wait)。不知道还记不记得前面TCP首部有一个ack字段,当他设置为1的时候,表示这个报文是一个确认收到报文。
然后再来考虑一种情况:丢包。网络环境不可靠,导致每一次发送的数据包可能会丢失,如果机器A发送了数据包丢失了,那么机器B永远接收不到数据,机器A永远在等待。解决这个问题的方法是:超时重传 。当机器A发出一个数据包时便开始计时,时间到还没收到确认回复,就可以认为是发生了丢包,便再次发送,也就是重传。
但重传会导致另一种问题:如果原先的数据包并没有丢失,只是在网络中待的时间比较久,这个时候机器B会受到两个数据包,那么机器B是如何辨别这两个数据包是属于同一份数据还是不同的数据?这就需要前面讲过的方法:给数据字节进行编号。这样接收方就可以根据数据的字节编号,得出这些数据是接下来的数据,还是重传的数据。
在TCP首部有两个字段:序号和确认号,他们表示发送方数据第一个字节的编号,和接收方期待的下一份数据的第一个字节的编号。前面讲到TCP是面向字节流,但是他并不是一个字节一个字节地发送,而是一次截取一整段。截取的长度受多种因素影响,如缓存区的数据大小、数据链路层限制的帧大小等。
连续ARQ协议停止等待协议已经可以满足可靠传输了,但有一个致命缺点:效率太低。发送方发送一个数据包之后便进入等待,这个期间并没有干任何事,浪费了资源。解决的方法是:连续发送数据包。模型如下:
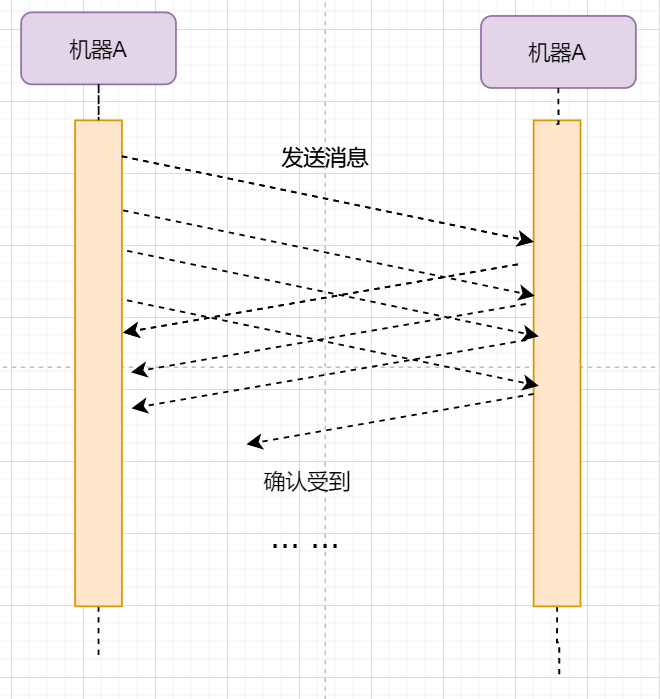
和停止等待最大的不同就是,他会源源不断地发送,接收方源源不断收到数据之后,逐一进行确认回复。这样便极大地提高了效率。但同样,带来了一些额外的问题:
发送是否可以无限发送直到把缓冲区所有数据发送完?不可以。因为需要考虑接收方缓冲区以及读取数据的能力。如果发送太快导致接收方无法接受,那么只是会频繁进行重传,浪费了网络资源。所以发送方发送数据的范围,需要考虑到接收方缓冲区的情况。这就是TCP的流量控制 。解决方法是:滑动窗口 。基本模型如下:
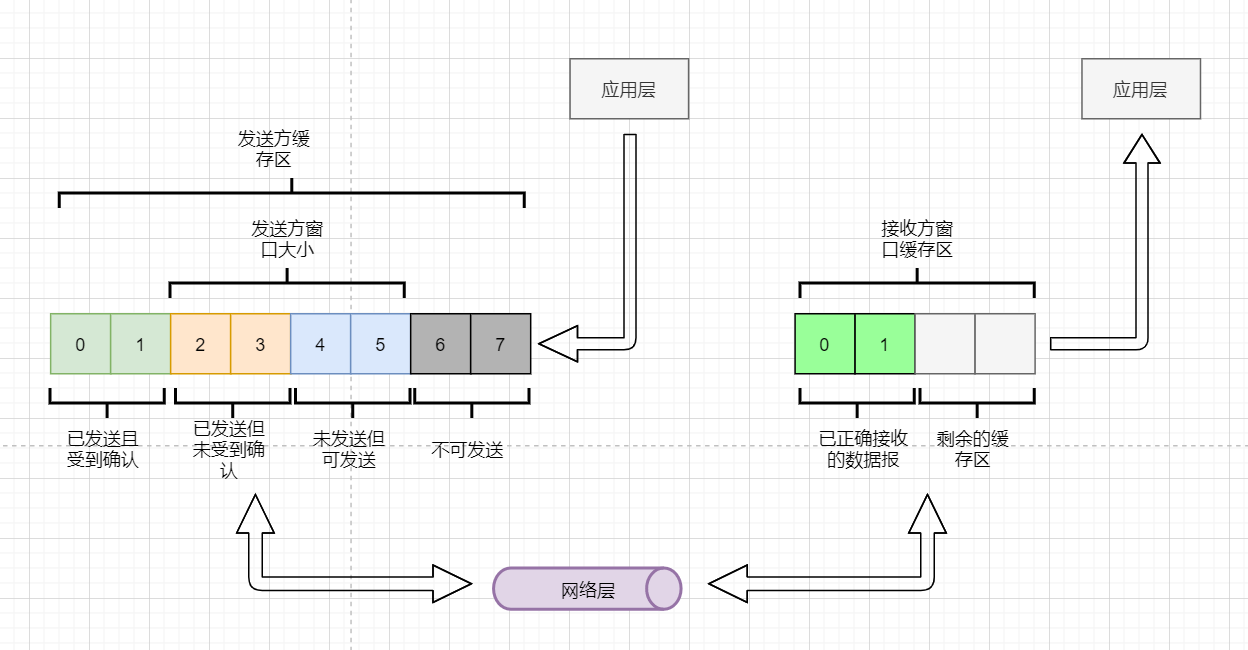
发送方需要根据接收方的缓冲区大小,设置自己的可发送窗口大小,处于窗口内的数据表示可发送,之外的数据不可发送。
当窗口内的数据接收到确认回复时,整个窗口会往前移动,直到发送完成所有的数据