在《LINUX设备驱动程序》(第三版)有几页对免锁算法的实现进行了分析。对于作者的分析有两点我想在这里作更加细致的说明。一是作者对循环缓冲的分析,当缓冲区满时分析错了;二是作者没有对里面的实现技巧作详细的介绍。针对以上两点,本文就用2.6.11(2.6.10和2.6.11是一样的)的kfifo.h和kfifo.c代码实现的免锁算法进行较为详细的分析。
对于临界区的访问一般的做法是在访问前加锁,退出访问时解锁,在加锁的过程中可能会有漫长的等待时间,也因此可能会影响到效率。如果在安全的情况下能够进行免锁访问无疑是可以提高效率,使人振奋。当然做任何事情都受一定的环境、条件的影响和制约,免锁算法的实现也不例外。那么在什么情况下可以实现和使用免锁算法呢,其实代码的作者Stelian在kfifo.c的注释代码行115--117已明确告诉了我们,如果只有一个读者和一个写者并发访问临界区的话就可以免锁。
以下是kfifo.h中声明的循环缓冲数据结构:
29 struct kfifo {
30 unsigned char *buffer; /* the buffer holding the data */
31 unsigned int size; /* the size of the allocated buffer */
32 unsigned int in; /* data is added at offset (in % size) */
33 unsigned int out; /* data is extracted from off. (out % size) */
34 spinlock_t *lock; /* protects concurrent modifications */
35 };
缓冲区buffer是以字节为单位的循环缓冲区
size是缓冲区的大小
in是写入数据时以 (in % size) 运算取得在buffer中的写下标
out是读取数据时以 (out % size) 运算取得在buffer中的读下标

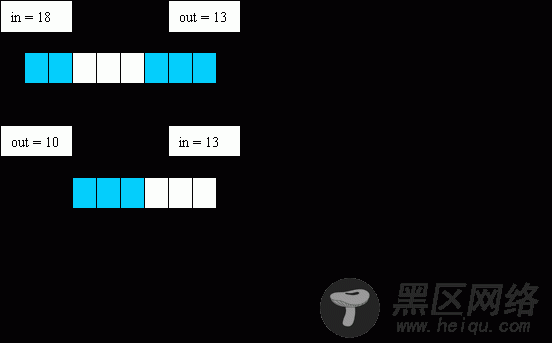
缓冲区buffer, size, in, out以一定的逻辑关系在代码中组织起来, 下面结合图A分析一下它们的特征和逻辑关系:
1. 缓冲区的特性是当缓冲区满时,不允许向缓冲区写数据,即缓冲区中的数据不会被覆盖,缓冲区的数据为空时不会读取无用的数据。
2. 在语义上in总是大于等于out,因此总会有( out + len ) <= in ,而len的取值范围是0 <= len <= size-1。注意这里是这语义上是in和out总是这样的关系,其实在实际运算时如果不会超出无符号整形的表示范围,in和out的关系无论是语义上还是逻辑上都是这种关系。
3. 当 (in == out) 时,缓冲区中的数据为空。当( (in != out) && ((in % size) == (out % size)) ) 时,也即它们的读写下标相等,而in和out不等时,表示缓冲区满。这种缓冲区满的情况是数据占满了所有的缓冲空间,并非《LINUX设备驱动程序》(第三版)描述的那样有一个字节浪费的情况。
4. 在kfifo.c代码的72--79行确保了size的值是2的n次方。
5. 循环缓冲区的数据字节数为(in - out),我们用BUF_DATA_BYTES来表示。相应地(size - (in - out))则表示循环缓冲区还有多少字节的空闲空间,我们就用BUF_FREE_SPACE来表示。
6. (size - (in % size))表示从写下标开始到循环缓冲结束有多少字节数,我们用WRETE_INDEX_TO_BUF_END_BYTES表示。相应地(size - (out % size))表示从读下标开始到循环缓冲结束有多少字节数,我们用READ_INDEX_TO_BUF_END_BYTES。