向下滑动滚动条,可以看到openssh,如图所示:
Hadoop src="/uploads/allimg/200607/061I4Mc_0.png">
在Cirrent下如果显示版本号,说明该包已经被此次安装选择上了,否则的话会显示一个Skip,意思是跳过该包,并不会安装该包的。
最后就等着下载安装了,这个过程可能会花费一点时间的。
Cygwin的配置
安装完成之后,例如我的Cygwin安装在G:\Cygwin\目录下面,进行配置如下:
设置环境变量:
在系统变量中新建变量【变量名:CYGWIN,变量值:ntsec tty】;编辑添加变量【变量名:Path,变量值:G:\Cygwin\bin;其它的保留】。
OK,基本配置好了,可以配置Hadoop了。
Hadoop目前的有几个版本:hadoop-0.16.4、hadoop-0.18.0,到Apache下载一个并解压缩即可。
将解压缩的Hadoop放到G盘下,例如我的是:G:\hadoop-0.16.4。
配置Hadoop只需要修改G:\hadoop-0.16.4\conf目录下的hadoop-env.sh文件即可,打开它你可以看到:
# The java implementation to use. Required.
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
将第二行的注释符号去掉,同时指定在你的机器上JAVA_HOME的值,如下为我修改的内容:
# The java implementation to use. Required.
export JAVA_HOME="D:\Program Files\Java\jdk1.6.0_07"
这里要注意,如果你的JDK安装目录中存在空格,需要使用双引号引起来,否则就会报错。
启动Cygwin,当前它是在home/yourname目录下的,如图所示:

切换到根目录下,从而进入G:\hadoop-0.16.4目录,并创建一个数据输入目录input-dir,如图所示:
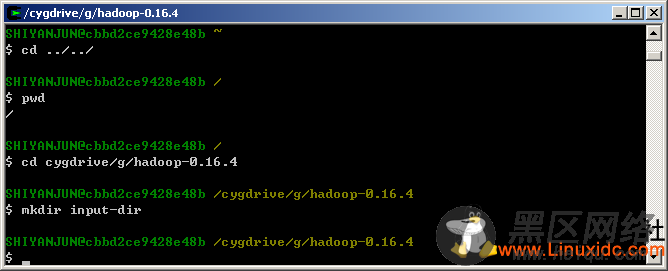
下面,打开G:\hadoop-0.16.4\input-dir,在该目录下新建几个记事本文件,例如我创建了3个:input-a.txt、input-b.txt、input-c.txt。三个文件的内容如下所示:
input-a.txt:as after append actor as as add as apache as after add as
input-b.txt:bench be bench believe background bench be block
input-c.txt:cafe cat communications connection cat cat cat cust cafe
接着就可以执行Hadoop自带的一个统计英文单词出现频率的例子了,直接输入命令bin/hadoop jar hadoop-0.16.4-examples.jar wordcount input-dir output-dir,其中hadoop-0.16.4-examples.jar是G:\hadoop-0.16.4包中的例子,input-dir是数据输入目录,在里面已经存在我们创建的三个文件了,output-dir是经过Hadoop处理后的输出结果的目录,这里,你需要对Google的MapReduce算法有一个简单的了解,主要就是在处理数据的时候是怎样的一个流程,引用IBM上的一片技术文章片段了解一下: