This module exports the following functions:
match Match a regular expression pattern to the beginning of a string.
fullmatch Match a regular expression pattern to all of a string.
search Search a string for the presence of a pattern.
sub Substitute occurrences of a pattern found in a string.
subn Same as sub, but also return the number of substitutions made.
split Split a string by the occurrences of a pattern.
findall Find all occurrences of a pattern in a string.
finditer Return an iterator yielding a match object for each match.
compile Compile a pattern into a RegexObject.
purge Clear the regular expression cache.
escape Backslash all non-alphanumerics in a string.
Some of the functions in this module takes flags as optional parameters:
A ASCII For string patterns, make \w, \W, \b, \B, \d, \D
match the corresponding ASCII character categories
(rather than the whole Unicode categories, which is the
default).
For bytes patterns, this flag is the only available
behaviour and needn't be specified.
I IGNORECASE Perform case-insensitive matching.
L LOCALE Make \w, \W, \b, \B, dependent on the current locale.
M MULTILINE "^" matches the beginning of lines (after a newline)
as well as the string.
"$" matches the end of lines (before a newline) as well
as the end of the string.
S DOTALL "." matches any character at all, including the newline.
X VERBOSE Ignore whitespace and comments for nicer looking RE's.
U UNICODE For compatibility only. Ignored for string patterns (it
is the default), and forbidden for bytes patterns.

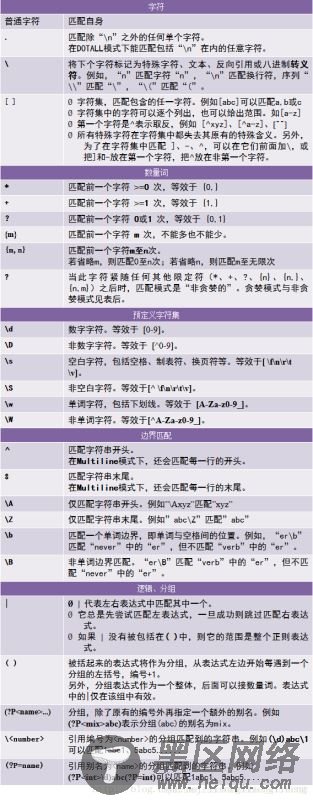
下面看下正则表达式匹配的流程:

正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,自己多使用几次就能明白。
总结
到此这篇关于python 正则表达式语法记录的文章就介绍到这了,更多相关python 正则表达式语法记录内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章: