
github 地址: https://github.com/CreatorsStack/CreatorDB
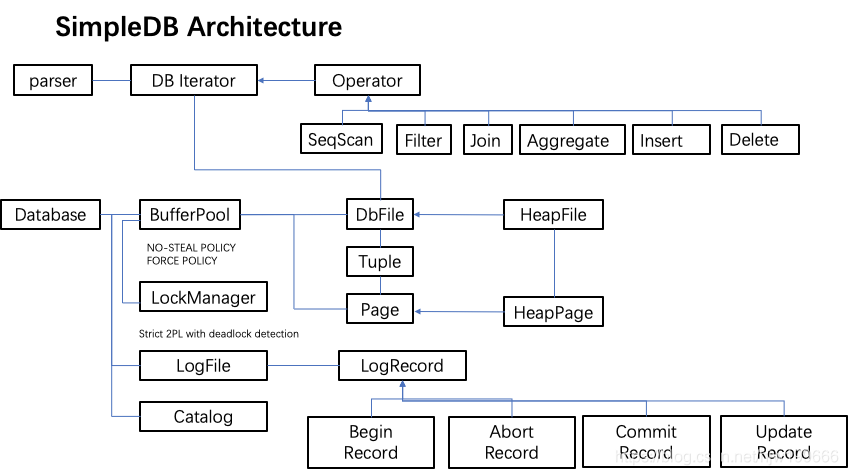
在开始 simpledb 旅途之前, 我们先从整体上来看看
SimpleDb 是一个 DBMS 数据库管理系统, 包含存储, 算子, 优化, 事务, 索引 等, 全方位介绍了如何从0实现一个 DBMS, 可以说, 这门课是学习 TIDB 等其他分布式数据库的前提.
项目文档:
lab1 - 存储模型
lab2 - 常见算子和 volcano 执行模型
lab3 - 优化器
lab4 - 基于 2pl 的事务
lab5 - b+ 树索引
lab6 - 崩溃恢复与回滚
lab1 - Storage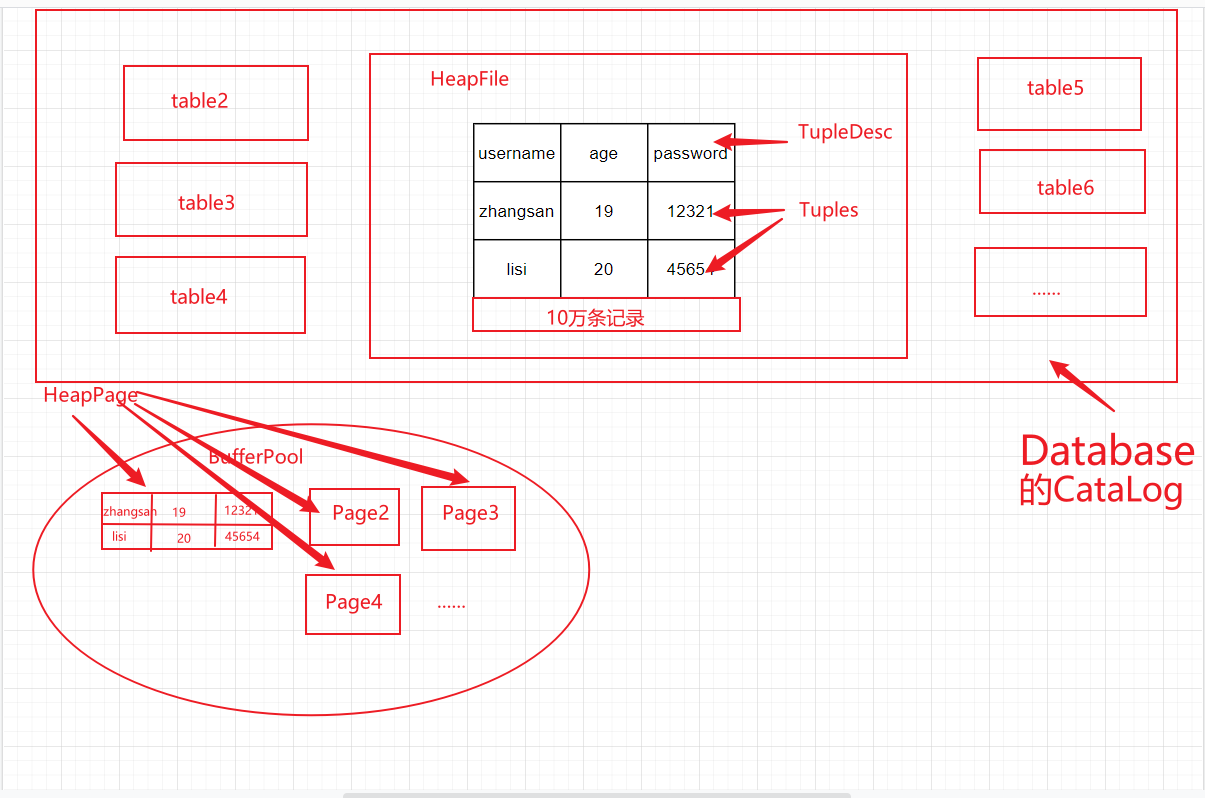
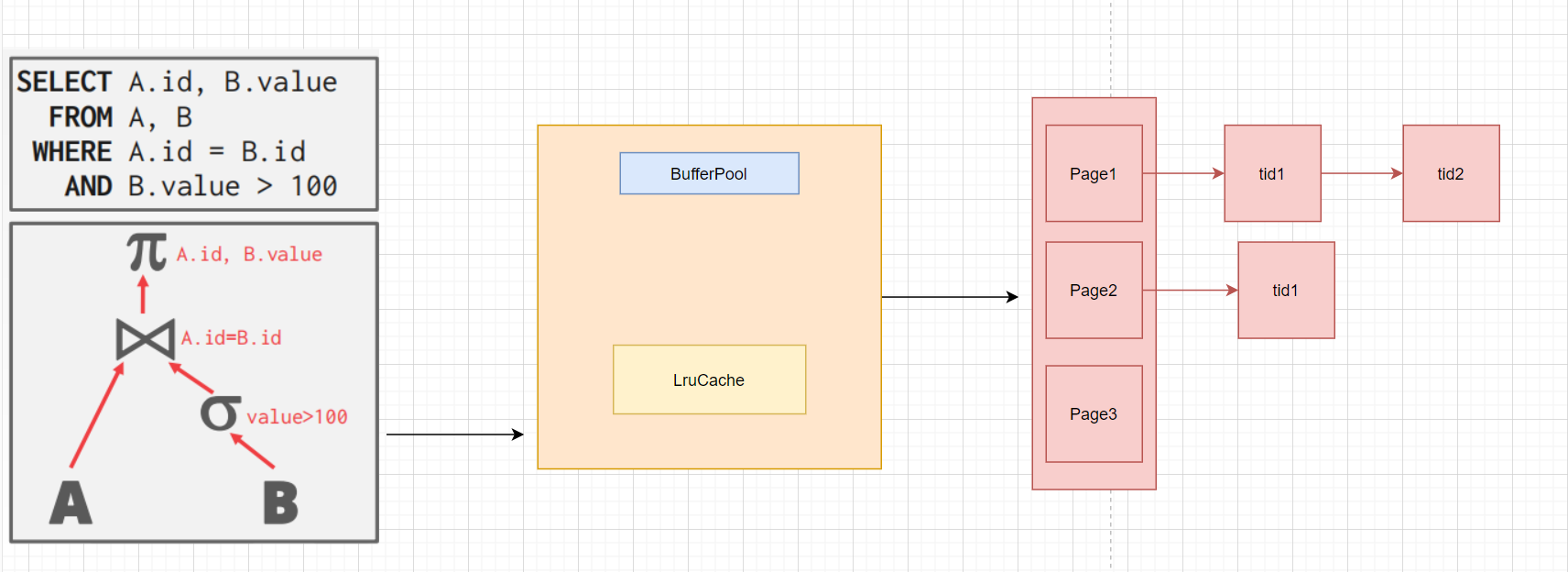
lab1 主要涉及存储 -- 也即和各种 file, page, bufferPool 等打交道
TupleDesc: td 描述了一个表每一列的元数据, 也即每个列的类型等等
Tuple: 代表了一行的数据
Page: 代表一个表的某个 page, page 由 header 和 body 组成, header 是一个 bitmap, 记录了body 中哪个位置是存在数据的. body 中存储了一个个 Tuple
DbFile: SimpleDb 中, 一个 Table 用一个 file 进行存储, 每个 file 包含了若干个 page
BufferPool: SimpleDb 的缓存组件, 可以搭配 Lru 缓存, 效果更佳. 是整个系统最核心的组件, 任何地方访问一个 page 都需要通过 bufferPool.getPage() 方法
CataLog: SimpleDb 等全局目录, 包含了tableid 和 table 的映射关系等
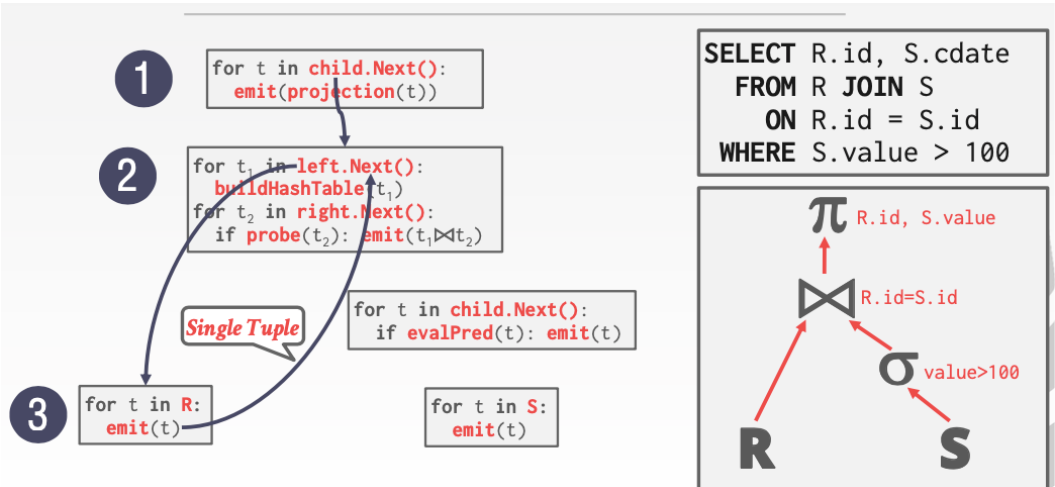
lab2 - Operators & Volcanolab2 主要涉及算子的开发: 也即各种 Operator, 如 seqScan, join, aggregation 等
需要注意的是, SimpleDb 采用了的 process model 是 volcano model, 每个算子都实现了相同的接口 --- OpIterator
SeqScan: 顺序扫描表的算子, 需要做一些缓存
Join + JoinPredicate: join 算子, 可以自己实现 简单的 nestedLoopJoin, 或者 sortMergeJoin
Filter + Predicate: filter 算子, 主要用于 where 后面的条件判断
Aggregate: aggregation 算子, 主要用于 sum() 等聚合函数
Insert / Delete: 插入/删除算子
关于 Volcano model, 举个例子, 在 lab2 中会更详细的介绍
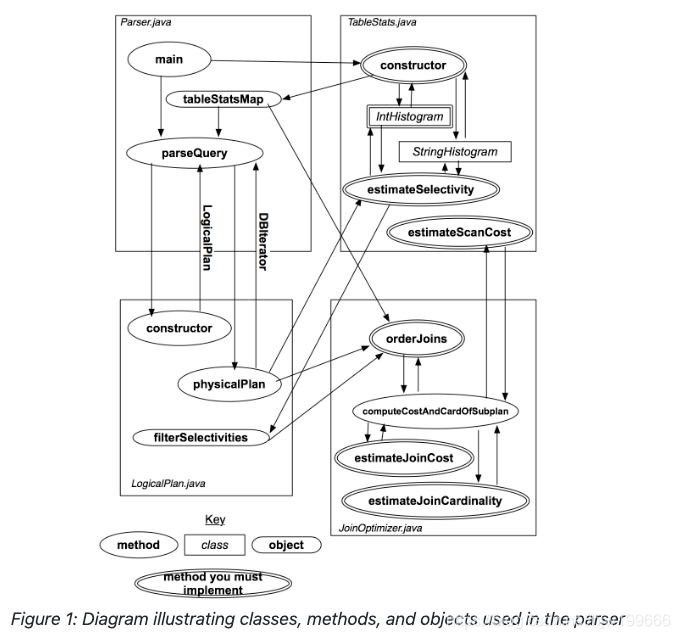
这个实验主要介绍了如何简单的进行数据估算和 join 优化
利用直方图进行谓词预估统计
利用 left-deep-tree 和动态规划算法进行 Join Optimizer
代码量较少
流程图如下:
实验四要求我们实现基于 2pl 协议的事务, 先来说一下在 simpleDB 中是如何实现事务的:
在SimpleDB中,每个事务都会有一个Transaction对象,我们用TransactionId来唯一标识一个事务,TransactionId在Transaction对象创建时自动获取。事务开始前,会创建一个Transaction对象,trasactionId 会被传入到 sql 执行树的每一个 operator 算子中,加锁时根据加锁页面、锁的类型、加锁的事务id去进行加锁。
比如, 底层的 A, B seqScan 算子, 就会给对应的 page 加读锁.
我们知道, page 是通过 bufferPool.getPage() 来统一获取的, 因此, 加锁的逻辑就在 bufferPool.getPage() 中
具体的方法就是实现一个 lockManager, lockManager 包含每个 page 和其持有其锁的事务的队列
当事务完成时,调用transactionComplete去完成最后的处理。transactionComplete会根据成功还是失败去分别处理,如果成功,会将事务id对应的脏页写到磁盘中,如果失败,会将事务id对应的脏页淘汰出bufferpool并从磁盘中获取原来的数据页。脏页处理完成后,会释放事务id在所有数据页中加的锁。
需要实现一个 LockManager, 跟踪每一个 transaction 持有的锁, 并进行锁管理.
需要实现 LifeTime lock, 也即有限等待策略
需要实现 DeadLock detect, 可以采用超时等待, 也可以通过依赖图进行检查
lab5 -- B+ tree
lab5主要是实现B+树索引,主要有查询、插入、删除等功能
查询主要根据B+树的特性去递归查找即可
插入要考虑节点的分裂(节点tuples满的时候)
删除要考虑节点内元素的重新分配(当一个页面比较空,相邻页面比较满的时候),兄弟节点的合并(当相邻两个页面的元素都比较空的时候)
lab6 -- log & rollback & recoverlab6 主要是实现一个 redo log & undo log 日志系统, 使得 simpledb 支持日志回滚和崩溃恢复
总结总的来说, 实验难度不大, 但是可以让我们快速入门数据库领域, 可以说是***的数据库课程了.