
摘要:今天就来跟大家盘一盘,常见的 6 种会发生索引失效的场景。
本文分享自华为云社区《面试官:聊聊索引失效?失效的原因是什么?》,作者:小林coding 。
在工作中,如果我们想提高一条语句查询速度,通常都会想对字段建立索引。
但是索引并不是万能的。建立了索引,并不意味着任何查询语句都能走索引扫描。
稍不注意,可能你写的查询语句是会导致索引失效,从而走了全表扫描,虽然查询的结果没问题,但是查询的性能大大降低。
今天就来跟大家盘一盘,常见的 6 种会发生索引失效的场景。
不仅会用实验案例给大家说明,也会清楚每个索引失效的原因。
发车!
我们先来看看索引存储结构长什么样?因为只有知道索引的存储结构,才能更好的理解索引失效的问题。
索引的存储结构跟 MySQL 使用哪种存储引擎有关,因为存储引擎就是负责将数据持久化在磁盘中,而不同的存储引擎采用的索引数据结构也会不相同。
MySQL 默认的存储引擎是 InnoDB,它采用 B+Tree 作为索引的数据结构,至于为什么选择 B+ 树作为索引的数据结构 ,详细的分析可以看我这篇文章:
在创建表时,InnoDB 存储引擎默认会创建一个主键索引,也就是聚簇索引,其它索引都属于二级索引。
MySQL 的 MyISAM 存储引擎支持多种索引数据结构,比如 B+ 树索引、R 树索引、Full-Text 索引。MyISAM 存储引擎在创建表时,创建的主键索引默认使用的是 B+ 树索引。
虽然,InnoDB 和 MyISAM 都支持 B+ 树索引,但是它们数据的存储结构实现方式不同。不同之处在于:
InnoDB 存储引擎:B+ 树索引的叶子节点保存数据本身;
MyISAM 存储引擎:B+ 树索引的叶子节点保存数据的物理地址;
接下来,我举个例子,给大家展示下这两种存储引擎的索引存储结构的区别。
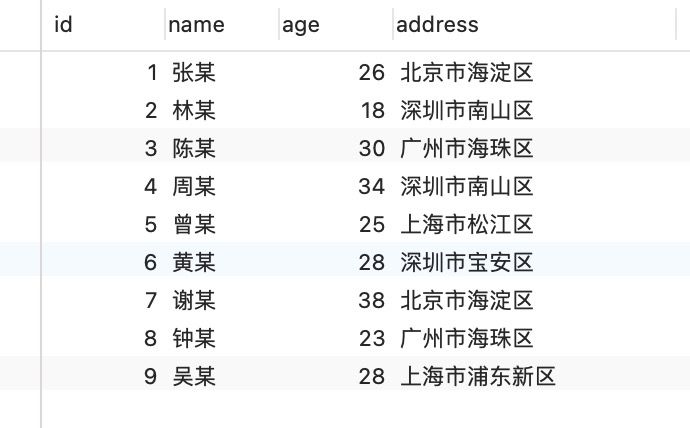
这里有一张 t_user 表,其中 id 字段为主键索引,其他都是普通字段。
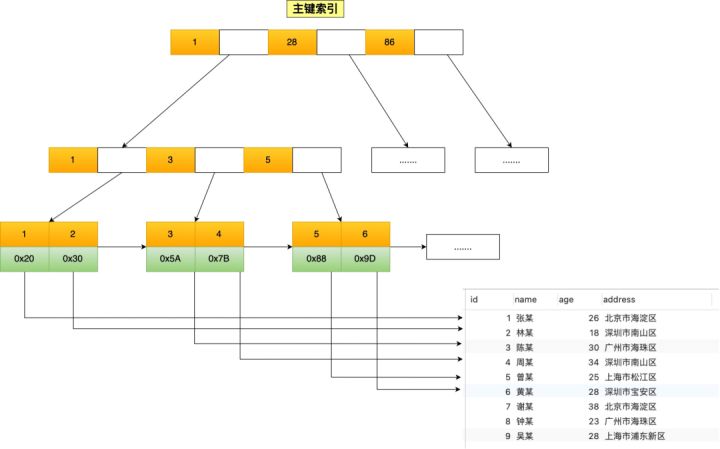
如果使用的是 MyISAM 存储引擎,B+ 树索引的叶子节点保存数据的物理地址,即用户数据的指针,如下图:
如果使用的是 InnoDB 存储引擎, B+ 树索引的叶子节点保存数据本身,如下图所示:
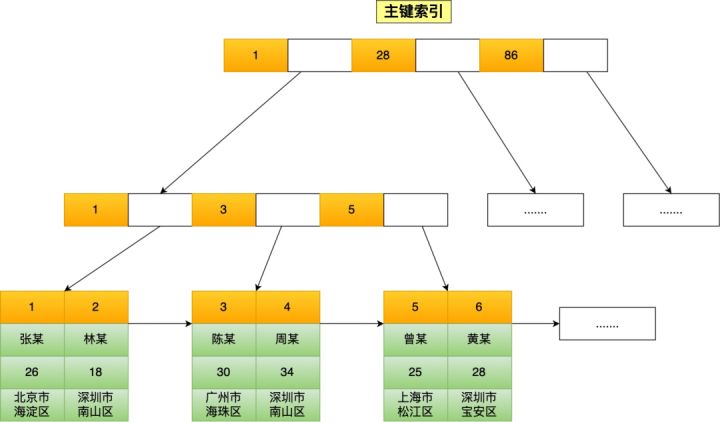
InnoDB 存储引擎根据索引类型不同,分为聚簇索引(上图就是聚簇索引)和二级索引。它们区别在于,聚簇索引的叶子节点存放的是实际数据,所有完整的用户数据都存放在聚簇索引的叶子节点,而二级索引的叶子节点存放的是主键值,而不是实际数据。
如果将 name 字段设置为普通索引,那么这个二级索引长下图这样,叶子节点仅存放主键值。
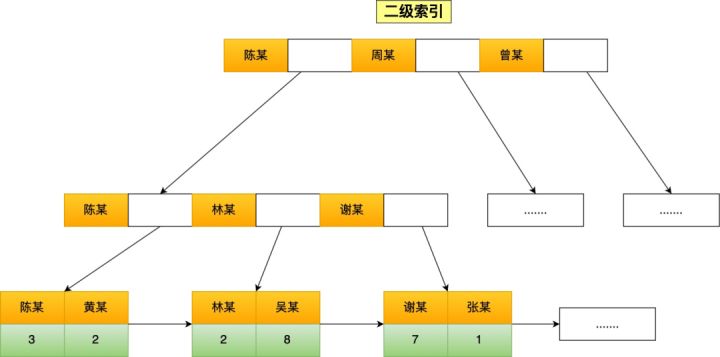
知道了 InnoDB 存储引擎的聚簇索引和二级索引的存储结构后,接下来举几个查询语句,说下查询过程是怎么选择用哪个索引类型的。
在我们使用「主键索引」字段作为条件查询的时候,如果要查询的数据都在「聚簇索引」的叶子节点里,那么就会在「聚簇索引」中的 B+ 树检索到对应的叶子节点,然后直接读取要查询的数据。如下面这条语句:
// id 字段为主键索引 select * from t_user where id=1;