
压缩列表(ziplist)是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
结构如下

压缩列表的每个节点构成如下
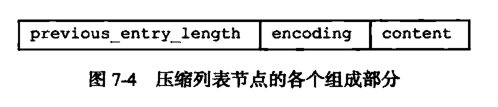
1)previous_entry_ength:以字节为单位,记录了压缩列表中前一个字节的长度。previous_entry_ength 的长度可以是1字节或者5字节:
如果前一节点的长度小于254字节,那么 previous_entry_ength 属性的长度为1字节,前一节点的长度就保存在这一个字节里面。
如果前一个节点的长度大于等于254,那么 previous_entry_ength 属性的长度为5字节,其中属性的第一字节会被设置为0xFE(十进制254),而之后的四个字节则用于保存前一节点的长度。
利用此原理即当前节点位置减去上一个节点的长度即得到上一个节点的起始位置,压缩列表可以从尾部向头部遍历,这么做很有效地减少了内存的浪费。
2)encoding:记录了节点的 content 属性所保存数据的类型以及长度。
3)content:保存节点的值,节点的值可以是一个字节数组或者整数,值的类型和长度由节点的 encoding 属性决定。
链表是一种常用的数据结构,C 语言内部是没有内置这种数据结构的实现,所以Redis自己构建了链表的实现。
链表节点定义:
多个 listNode 可以通过 prev 和 next 指针组成双端链表,结构如下

另外Redis还提供了操作链表的数据结构:
typedef struct list{ //表头节点 listNode *head; //表尾节点 listNode *tail; //链表所包含的节点数量 unsigned long len; //节点值复制函数 void (*free) (void *ptr); //节点值释放函数 void (*free) (void *ptr); //节点值对比函数 int (*match) (void *ptr,void *key); }list;list结构为链表提供了表头指针 head ,表尾指针 tail 以及链表长度计数器 len ,dup、free、match 成员则是用于实现多态链表所需的类型特定函数。
Redis链表实现的特性:
双端:链表节点带有 prev 和 next 指针,获取某个节点的前置节点和后置节点复杂度都是O(1)。
无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问以NULL为终点。
带表头指针和表尾指针:通过list结构的 head 和 tail 指针,程序获取链表的表头节点和表尾结点的复杂度都是O(1)。
带链表长度计数器:程序使用 list 结构的 len属性对 list持有的链表节点进行计数,程序获取链表中节点数量的复杂度为O(1)。
多态:链表节点使用 void* 指针来保存节点值,并且通过 list 结构的 dup、 free、match 三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。
疑问:Redis列表什么时候会使用 ziplist 编码,什么时候又会使用 linkedlist 编码呢?下节再说...