
不要把鸡蛋放一个篮子的道理大家应该都知道,那分库的意义就很明显了,然后你会发现时间久了表的数据大了,就会想到去接触分表,什么TDDL、Sharding-JDBC、DRDS这些插件都会接触到。
你发现流量大的时候,或者热点数据打到数据库还是有点顶不住,压力太大了,那非关系型数据库就进场了,Redis当然是首选,但是memcache也有各自的应用场景。
Redis使用后,真香,真快,但是你会开始担心最开始提到的安全问题,这玩意快是因为在内存中操作,那断点了数据丢了怎么办?你就开始阅读官方文档,了解RDB,AOF这些持久化机制,线上用的时候还会遇到缓存雪崩击穿、穿透等等问题。
单机不满足你就用了,他的集群模式,用了集群可能也担心集群的健康状态,所以就得去了解哨兵,他的主从同步,时间久了Key多了,就得了解内存淘汰机制......
老板让你最最小的代价去设计每日签到和UV、PV统计你就会接触到:位图和HyperLogLog,高速的过滤你就会考虑到:布隆过滤器 (Bloom Filter) ,附近的人就会使用到:GeoHash 他的大容量存储有问题,你可能需要去了解Pika....
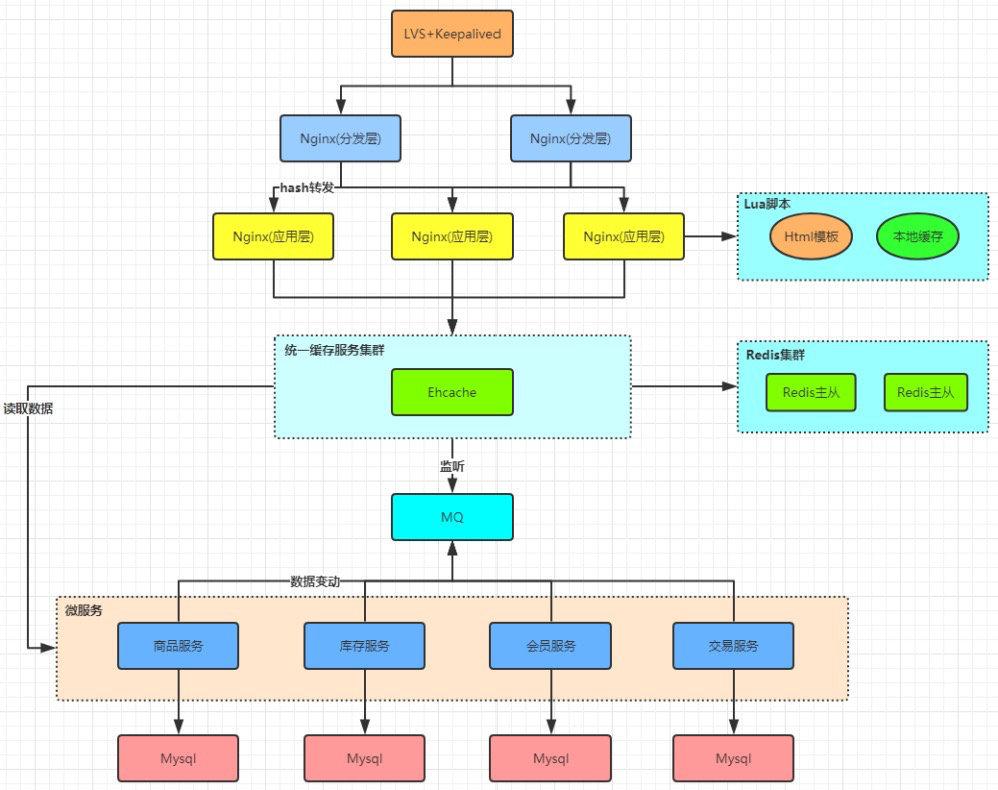

其实远远没完,每个的点我都点到为止,但是其实要深究每个点都要学很久,我们接着往下看。
实时/离线数仓/大数据等你把几种关系型非关系型数据库的知识点,整理清楚后,你会发现数据还是大啊,而且数据的场景越来越多多样化了,那大数据的各种中间件你就得了解了。
你会发现很多场景,不需要实时的数据,比如你查你的支付宝去年的,上个月的账单,这些都是不会变化的数据,没必要实时,那你可能会接触像ODPS这样的中间件去做数据的离线分析。
然后你可能会接触Hadoop系列相关的东西,比如于Hadoop(HDFS)的一个数据仓库工具Hive,是建立在 Hadoop 文件系统之上的分布式面向列的数据库HBase 。
写多的场景,适合做一些简单查询,用他们又有点大材小用,那Cassandra就再合适不过了。
离线的数据分析没办法满足一些实时的常见,类似风控,那Flink你也得略知一二,他的窗口思想还是很有意思。
数据接触完了,计算引擎Spark你是不是也不能放过......
