
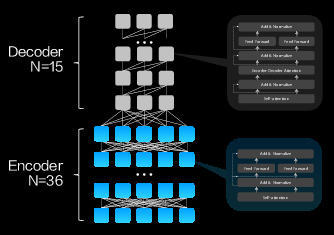
盘古NLP大模型架构
另外,在模型结构上面,跟传统其他企业训练的NLP大模型的方式不同,盘古看重的不仅是大模型有生成能力,还要有更强的理解能力。华为采用了Encode和Decode的架构,来保证盘古大模型的在生成和理解上面的两个性能。
盘古CV大模型针对盘古CV大模型,谢凌曦同样先举了一个例子:如何区分白色猫和白色狗的图片?人类看到这两张图片能一眼识别出来哪只是猫,哪只是狗,那么大模型面对这些是如何处理的呢?
“我们需要让模型在训练的过程中,了解这些样例之间真正强关联性的东西。” 谢凌曦强调图像中非常重要的一个东西就是层次化的信息。“在判断图像的过程中,首先要把握好图片中层次化的信息,能够快速的定位到图片中哪部分信息是起决定作用的,让算法以自适应的方式去关注比较重要的地方或内容,这样就容易捕捉样本之间的关系。在这两张图片中,很明显白色不是最重要的信息,动物才是图片中起决定性的信息。”
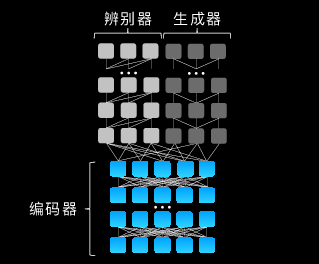
盘古CV大模型架构
基于此,盘古CV大模型首次兼顾了图像判别与生成能力,能同时满足底层图像处理与高层语义的理解需求,同时能够融合行业知识的微调,快速适配各种下游任务。
另外,为了解决模型大,数据多带来的学习效率低,表征性能弱的问题,盘古CV大模型在预训练阶段主要集中在数据处理、架构设计和模型优化三个阶段进行优化。目前盘古CV大模型在Image Net 1%、10%数据集上的小样本分类精度上均达到目前业界最高水平。
在CV大模型中,除了应用一些业界通用的算法,其中也有华为自研的算法,比如在视觉中强行给模型注入一些层次化的信息,让模型能够学的更好。
而每个自研算法的的背后,其实都是团队解决每一个困难之后的宝贵经验总结。
大模型研发很难,还好有他们在整个盘古大模型的研发过程中,难点很多,比如上文提到的独创算法,因为除了架构和数据,算法是非常核心的技术。
谢凌曦详细谈了谈其中的一个技术难点:无论是文本信息,还是图像信息,表征上看起来相似的东西,语义理解上却截然不同。
“我们从问题出发,发现视觉特征是一个层次化的捕捉过程,表征的一些特征更多的是集中在浅层特征里面,但到了语义就更多体现在深层特征里面。所以,需要我们在不同层面上把这些特征对齐,这样才能学的更好。同样,在NLP上需要将模型的注意力放在一个最合适的地方。这个关键点也是通过复杂的神经网络寻找到的,而并非随便在一段文字中利用算法去找到关键点。”
这是一个很通俗的解释,技术细节相对会更复杂和难以抽象化描述。但这个问题也只是冰山上的一角,整个大模型的研发中,谢凌曦和团队要不断去挖掘表象问题的本质,解决类似的技术难题。
另一个比较棘手的问题是模型的调试运行。为了从预训练获取更多的知识,盘古大模型的数据肯定会越来越大,对底层的硬件平台性能要求更高。此时,预训练的效果,看的也已经不是模型本身,而是基础设施构建得是否足够优秀。
比如运行大模型需要足够的机器提供充足的算力,但一台机器最多只能安装8个GPU卡。NLP大模型需要上千个GPU卡,即使是较小的CV大模型,也需要128块GPU同时运行,所以必须有一个非常好的机制去合理调配资源。
巧妇难为无米之炊,最开始的时候谢凌曦也很苦恼,谁来支撑大模型的运行呢?实践证明,华为云为盘古提供的可多机多卡并行的云道平台起了大作用。云道平台能够轻松分配资源,避免因基础设施问题导致的盘古研发进度受阻,它同时可以将数据,以最合适的格式存储在服务器上,以便在使用过程中更有效的读取。
不仅如此,大模型的困难也难在工程上,华为CANN、MindSpore框架、ModelArts平台协同优化,充分释放算力,为盘古大模型提供了强大的背后支撑:
针对底层算子性能,基于华为CANN采用了算子量化、算子融合优化等技术,将单算子性能提升30%以上。