
本文结构采用宏观着眼,微观入手,从整体到细节的方式剖析 Hive SQL 底层原理。第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程,第三节剖析 SQL 编译成 MapReduce 的具体实现原理。
HiveHive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。
Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行查询。
我们今天来聊的就是 Hive 底层是怎样将我们写的 SQL 转化为 MapReduce 等计算引擎可识别的程序。了解 Hive SQL 的底层编译过程有利于我们优化Hive SQL,提升我们对Hive的掌控力,同时有能力去定制一些需要的功能。
Hive 底层执行架构我们先来看下 Hive 的底层执行架构图, Hive 的主要组件与 Hadoop 交互的过程:
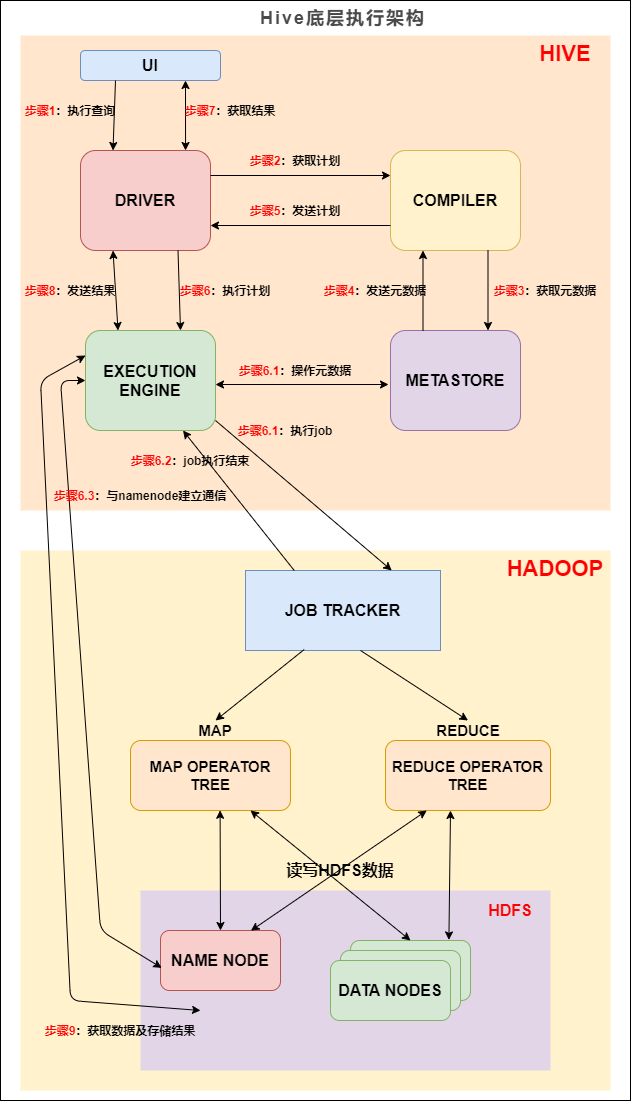
在 Hive 这一侧,总共有五个组件:
UI:用户界面。可看作我们提交SQL语句的命令行界面。
DRIVER:驱动程序。接收查询的组件。该组件实现了会话句柄的概念。
COMPILER:编译器。负责将 SQL 转化为平台可执行的执行计划。对不同的查询块和查询表达式进行语义分析,并最终借助表和从 metastore 查找的分区元数据来生成执行计划。
METASTORE:元数据库。存储 Hive 中各种表和分区的所有结构信息。
EXECUTION ENGINE:执行引擎。负责提交 COMPILER 阶段编译好的执行计划到不同的平台上。
上图的基本流程是:
步骤1:UI 调用 DRIVER 的接口;
步骤2:DRIVER 为查询创建会话句柄,并将查询发送到 COMPILER(编译器)生成执行计划;
步骤3和4:编译器从元数据存储中获取本次查询所需要的元数据,该元数据用于对查询树中的表达式进行类型检查,以及基于查询谓词修建分区;
步骤5:编译器生成的计划是分阶段的DAG,每个阶段要么是 map/reduce 作业,要么是一个元数据或者HDFS上的操作。将生成的计划发给 DRIVER。
如果是 map/reduce 作业,该计划包括 map operator trees 和一个 reduce operator tree,执行引擎将会把这些作业发送给 MapReduce :
步骤6、6.1、6.2和6.3:执行引擎将这些阶段提交给适当的组件。在每个 task(mapper/reducer) 中,从HDFS文件中读取与表或中间输出相关联的数据,并通过相关算子树传递这些数据。最终这些数据通过序列化器写入到一个临时HDFS文件中(如果不需要 reduce 阶段,则在 map 中操作)。临时文件用于向计划中后面的 map/reduce 阶段提供数据。
步骤7、8和9:最终的临时文件将移动到表的位置,确保不读取脏数据(文件重命名在HDFS中是原子操作)。对于用户的查询,临时文件的内容由执行引擎直接从HDFS读取,然后通过Driver发送到UI。
Hive SQL 编译成 MapReduce 过程编译 SQL 的任务是在上节中介绍的 COMPILER(编译器组件)中完成的。Hive将SQL转化为MapReduce任务,整个编译过程分为六个阶段:
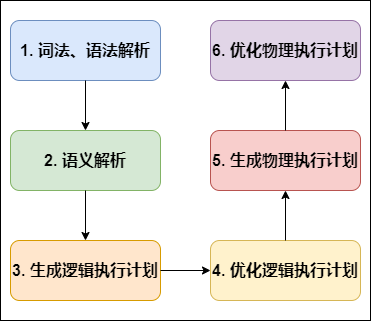
词法、语法解析: Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
Antlr是一种语言识别的工具,可以用来构造领域语言。使用Antlr构造特定的语言只需要编写一个语法文件,定义词法和语法替换规则即可,Antlr完成了词法分析、语法分析、语义分析、中间代码生成的过程。
语义解析: 遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
生成逻辑执行计划: 遍历 QueryBlock,翻译为执行操作树 OperatorTree;
优化逻辑执行计划: 逻辑层优化器进行 OperatorTree 变换,合并 Operator,达到减少 MapReduce Job,减少数据传输及 shuffle 数据量;
生成物理执行计划: 遍历 OperatorTree,翻译为 MapReduce 任务;