Kafka使用Zookeeper来维护集群成员(brokers)的信息。每个broker都有一个唯一标识broker.id,用于标识自己在集群中的身份,可以在配置文件server.properties中进行配置,或者由程序自动生成。下面是Kafka brokers集群自动创建的过程:
每一个broker启动的时候,它会在Zookeeper的/brokers/ids路径下创建一个临时节点,并将自己的broker.id写入,从而将自身注册到集群;
当有多个broker时,所有broker会竞争性地在Zookeeper上创建/controller节点,由于Zookeeper上的节点不会重复,所以必然只会有一个broker创建成功,此时该broker称为controller broker。它除了具备其他broker的功能外,还负责管理主题分区及其副本的状态。
当broker出现宕机或者主动退出从而导致其持有的Zookeeper会话超时时,会触发注册在Zookeeper上的watcher事件,此时Kafka会进行相应的容错处理;如果宕机的是controller broker时,还会触发新的controller选举。
二、副本机制为了保证高可用,kafka的分区是多副本的,如果一个副本丢失了,那么还可以从其他副本中获取分区数据。但是这要求对应副本的数据必须是完整的,这是Kafka数据一致性的基础,所以才需要使用controller broker来进行专门的管理。下面将详解介绍Kafka的副本机制。
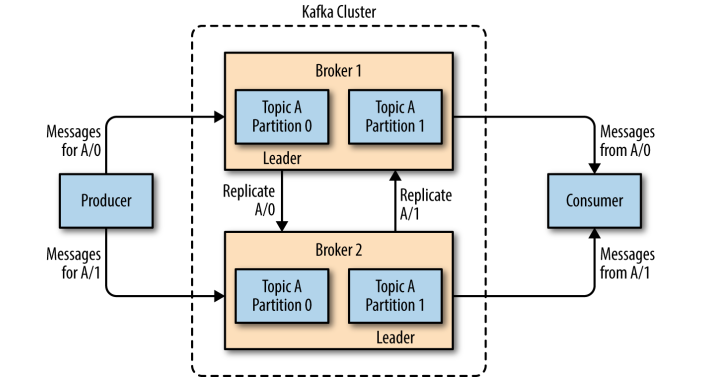
2.1 分区和副本Kafka 的主题被分为多个分区 ,分区是Kafka最基本的存储单位。每个分区可以有多个副本(可以在创建主题时使用replication-factor参数进行指定)。其中一个副本是首领副本(Leader replica),所有的事件都直接发送给首领副本;其他副本是跟随者副本(Follower replica),需要通过复制来保持与首领副本数据一致,当首领副本不可用时,其中一个跟随者副本将成为新首领。