
通常处理线上问题的三板斧是重启-回滚-扩容,能够快速有效的解决问题,但是根据我多年的线上经验,这三个操作略微有些简单粗暴,解决问题的概率也非常随机,并不总是有效。这边总结下通常我处理应用中遇到的故障的解决方案。
原则处理故障的时候必须遵循的一些原则
提早发现问题,避免故障扩散
故障的出现链路一般如下图所示
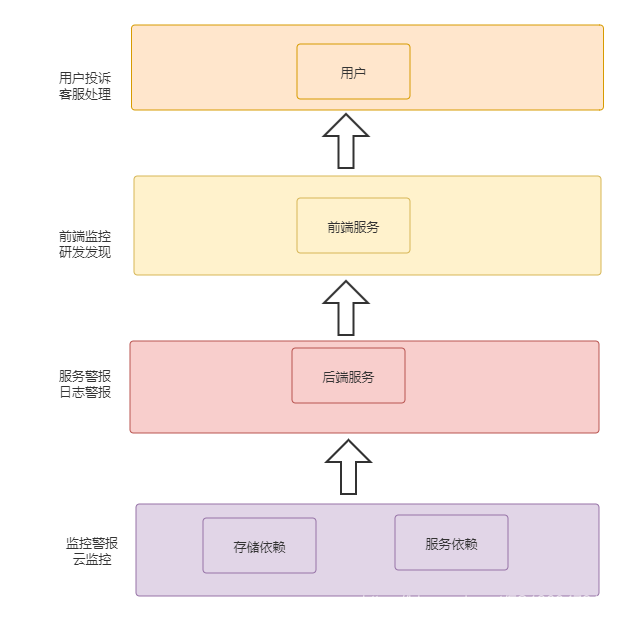
每一层都有可能出现问题,越底层出现问题,影响面越大。所以每一个层次都需要有相应的问题监控机制,这样越早发现问题,越能尽早解决故障,避免问题的扩散。比如服务依赖的一个数据库主库有问题了,如果等到用户报过来,这时候可能服务已经挂了几分钟了。再等你分析问题,解决问题,切换主备什么的,可能几分钟又过去了。影响访问比较大了。如果在数据库出问题时,就已经收到警报,迅速解决,可能没等用户报过来,问题解决了。
迅速广播
当收到一个P0警报,判断应用出现问题了,第一时间在组内广播。全部人员进入一级战斗状态,发现可能和其他依赖的服务/中间件/运维/云厂商有关,立即通知相关责任人,要求进入协同作战。
快速恢复
保留现场很重要,有助于发现root cause。但是发生故障了,必须要争分夺秒,不能为了保留现场浪费几分钟的时间去干什么dump内存,jstack线程状态的事。必须第一时间内先恢复服务,之后再根据当时监控数据,去找root cause
持续观察
为了解决问题,可能需要在线上进行了重启/回滚/mock/限流等操作,一定要查看是否达到了预期效果。
需要持续观察一段时间,服务是否真的正常。 有时候可能只是短暂下去了,还会反扑。
处理手段无非是重启、扩容、回滚、限流、降级、hotfix
以下是我一般处理线上问题的流程
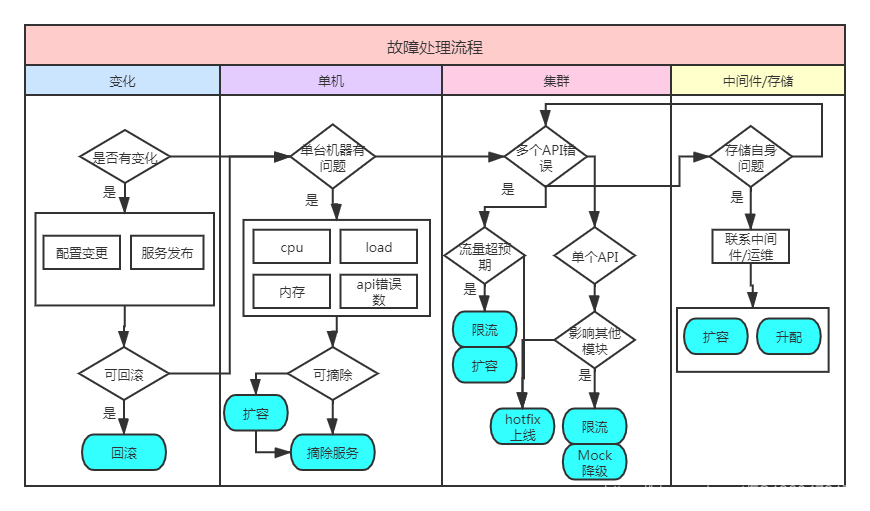
主要分为四大块 step1: 是否有变化
和造成大部分车祸的原因是由于变化导致一样,线上故障通常也是由于变化导致的。外部的变化很难感知到,但是服务自身的变化很容易感知,当有服务发布、配置变更等变化时。那么首先判断是否可回滚,可回滚的立马回滚。
step2: 是否单机现在一般是集群部署,服务高可用。如果只是一台机器有问题,在服务可摘除的情况下立即摘除。不可立即摘除的,先扩容再摘除。
step3: 是否集群整个服务集群都出问题了,问题就相对比较复杂一些了,需要分为单个API与多个API错误。
单个API错误
是否对应用内其他API,模块、下游的存储有影响。有影响的话,可降级的及时降级。由于请求量增加引起的,限流。对其他模块无影响,再排查问题,hotfix。
多个API错误
这种通常是step4出错了,可以直接到step4查看。
如果不是step4错误,如果流量超预期,限流扩容操作。如果不是,找代码问题,hotfix上线
立即找到相关团队,一起看问题。如果是自身服务不正常的请求引起的,再做相应的fix。如果是正常操作引起的,那需要紧急扩容,升级配置。
如何预防从上述操作可以看出,故障发生时需要做的判断还是很多的,如果经验不够丰富,处理不得当,很容易引发故障升级、资产损失。
所以需要提前预防。
像哲学家剖析自己一样去了解你的服务。一般包含以下内容
绘制应用系统架构图需要包含以下模块,
服务给谁用
出了问题应该通知到谁
包含哪些模块
应用了哪些功能模块。用户报问题过来的时候知道大体属于哪个服务出了问题
系统流程
模块间如何流转的
依赖的中间件
依赖了哪些中间件,对应负责人是谁
依赖的存储、消息队列
依赖了哪些存储,存储运维负责人是谁
依赖的服务
依赖了哪些服务,什么功能依赖了什么服务,出了问题,找谁。是否是弱依赖,可降级的。
系统是如何部署的,部署在什么环境。如何登陆、扩容、升配。
梳理系统故障等级哪些模块是核心的,哪些模块是没那么重要的,可以降级的。
压测演练当前系统能够支持的单机QPS是多少,可能存在的性能瓶颈是什么,需要通过压测来得出来。