
`HDFS(hadoop distributed filesystem)由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。HDFS是一个主/从(Mater/Slave)体系结构,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。
HDFS客户端:就是客户端。
1、提供一些命令来管理、访问 HDFS,比如启动或者关闭HDFS。
2、与 DataNode 交互,读取或者写入数据;读取时,要与 NameNode 交互,获取文件的位置信息;写入 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
NameNode:即Master,
1、管理 HDFS 的名称空间。
2、管理数据块(Block)映射信息
3、配置副本策略
4、处理客户端读写请求。
DataNode:
就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
1、存储实际的数据块。
2、执行数据块的读/写操作。
Secondary NameNode:
并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
1、辅助 NameNode,分担其工作量。
2、定期合并 fsimage和fsedits,并推送给NameNode。
3、在紧急情况下,可辅助恢复 NameNode。
hdfs的架构详细剖析HDFS分布式文件系统也是一个主从架构,主节点是我们的namenode,负责管理整个集群以及维护集群的元数据信息,从节点datanode,主要负责文件数据存储:
1)HDFS集群包括,NameNode和DataNode以及Secondary Namenode。
2)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
3)DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。
4)Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。最主要作用是辅助namenode管理元数据信息
heartbeats是心跳的意思,每次启动hdfs,datanode都会通过心跳向namenode汇报自己的存储情况,
balancing是平衡的意思,表示namenode合适分配块的存储位置,使每个节点负载均衡
namenode与datanodeNamenode与Datanode的关系图示:
NameNode与Datanode的总结概述
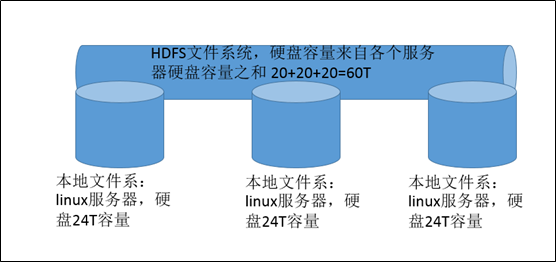
hdfs文件系统容量大小约等于各个服务器的容量大小之和得到,为什么是约等于?因为每个服务器都要留部分空间给自身系统等东西,不能全部用来做hdfs的容量。
 hdfs存储方式---blockhdfs的数据以block块的形式进统一存储管理,每个block块默认最多可以存储128M的文件,如果有一个文件大小为1KB,也是要占用一个block块,但是实际占用磁盘空间还是1KB大小,类似于有一个水桶可以装128斤的水,但是我只装了1斤的水,那么我的水桶里面水的重量就是1斤,而不是128斤。除了些用不可分割算法进行压缩的文件不可被切分外,几乎所有文件都可以被切割。
每个block块的元数据大小大概为150字节
所有的文件都是以block块的方式存放在HDFS文件系统当中,block块的大小可以通过hdfs-site.xml当中的配置文件进行指定:
<property> <name>dfs.block.size</name> <value>块大小 以字节为单位</value> <!--只写数值就可以--> </property>抽象成数据块的好处:
一个文件有可能大于集群中任意一个磁盘
10T*3/128 = xxx块 2T,2T,2T 文件方式存—–>多个block块,这些block块属于一个文件
使用块抽象而不是文件可以简化存储子系统
块非常适合用于数据备份进而提供数据容错能力和可用性
hdfs的副本因子