
6)查看集群是否是成功运行的状态:
node2:6380> CLUSTER INFO cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:12 cluster_my_epoch:12 cluster_stats_messages_ping_sent:4406 cluster_stats_messages_pong_sent:4225 cluster_stats_messages_meet_sent:1 cluster_stats_messages_sent:8632 cluster_stats_messages_ping_received:4225 cluster_stats_messages_pong_received:4413 cluster_stats_messages_auth-req_received:4 cluster_stats_messages_received:8642 7)检查各个节点关系之间是否正常:
node2:6380> CLUSTER NODES d645d06708e1eddb126a6c3c4e38810c188d0906 192.168.0.120:6380@16380 slave 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 0 1617335179000 3 connected 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 192.168.0.130:6379@16379 master - 0 1617335177627 3 connected 10923-16383 ff53e43f9404981a51d4e744de38004a5c22b090 192.168.0.130:6380@16380 myself,slave 7a7392cb66bea30da401d2cb9768a42bbdefc5db 0 1617335178000 12 connected 7a7392cb66bea30da401d2cb9768a42bbdefc5db 192.168.0.140:6379@16379 master - 0 1617335180649 12 connected 5461-10922 c71b52f728ab58fedb6e05a525ce00b453fd2f6b 192.168.0.120:6379@16379 master - 0 1617335179000 12 connected 0-5460 6a627cedaa4576b1580806ae0094be59c32fa391 192.168.0.140:6380@16380 slave 7a7392cb66bea30da401d2cb9768a42bbdefc5db 0 1617335179644 12 connected
下面可能是我上面操作时输错了node-id导致的,一般按正确步骤来说不用产生这种情况。
*8)发现节点关系还是不正常,node3:6380也对应了node3:6379,更改一下就好了,让其对应node1的6379:
$ redis-cli -h node3 -p 6380 node3:6380> CLUSTER REPLICATE c71b52f728ab58fedb6e05a525ce00b453fd2f6b *9)再次检查,节点关系正常:
node3:6380> CLUSTER NODES c71b52f728ab58fedb6e05a525ce00b453fd2f6b 192.168.0.120:6379@16379 master - 0 1617335489929 12 connected 0-5460 6a627cedaa4576b1580806ae0094be59c32fa391 192.168.0.140:6380@16380 myself,slave c71b52f728ab58fedb6e05a525ce00b453fd2f6b 0 1617335490000 12 connected 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 192.168.0.130:6379@16379 master - 0 1617335487913 3 connected 10923-16383 d645d06708e1eddb126a6c3c4e38810c188d0906 192.168.0.120:6380@16380 slave 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 0 1617335488000 3 connected 7a7392cb66bea30da401d2cb9768a42bbdefc5db 192.168.0.140:6379@16379 master - 0 1617335489000 12 connected 5461-10922 ff53e43f9404981a51d4e744de38004a5c22b090 192.168.0.130:6380@16380 slave 7a7392cb66bea30da401d2cb9768a42bbdefc5db 0 1617335490931 12 connected node3:6380> 集群扩容 发现节点 现在我们的node4还没有添加进集群,所以将node4进行添加:
$ redis-cli -h node1 -p 6379 CLUSTER MEET 192.168.0.150 6379 $ redis-cli -h node1 -p 6379 CLUSTER MEET 192.168.0.150 6380 查看节点信息,对内容进行部分截取:
$ redis-cli -h node1 -p 6379 node3:6380> cluster nodes # 这里 f3dec547054791b01cfa9431a4c7a94e62f81db3 192.168.0.150:6380@16380 master - 0 1617337335000 0 connected d1ca7e72126934ef569c4f4d34ba75562d36068f 192.168.0.150:6379@16379 master - 0 1617337337289 14 connected 目前node4的6379和6380并未建立槽位,也没有和其他节点建立联系,所以不能进行任何读写操作。
进行扩容 使用redis-trib.rb工具对新节点进行扩容,大体流程是每个节点拿出一部分槽位分配给node4:6379。
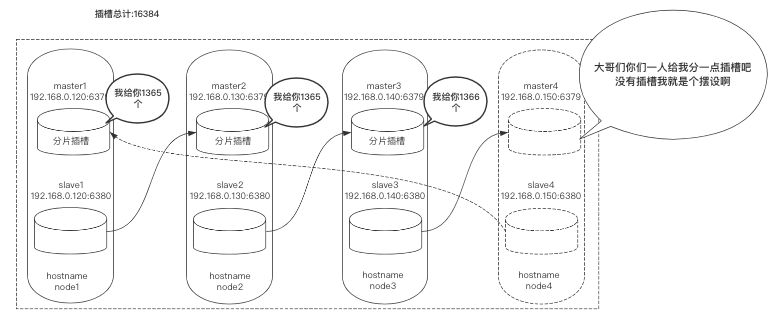
在槽位迁徙时会带着数据一起迁徙,这并不会影响正常业务,属于热扩容。
首先要做4分片的规划,每个节点共分4096个槽位:
$ python3 >>> divmod(16384,4) (4096, 0) 接下来开始进行扩容,由于我们只在node1上装了ruby环境,所以在node1上执行:
$ cd /usr/local/redis_cluster/redis-6.2.1/src/ # 旧版Redis这里以脚本名开头 redis-trib.rb,并且不需要添加--cluster参数 $ redis-cli --cluster reshard 192.168.0.120 6379 # 你需要分配多少? How many slots do you want to move (from 1 to 16384)? 4096 # 你要给哪一个集群节点分配插槽?我是给node4节点的6379 what is the receiving node ID? d1ca7e72126934ef569c4f4d34ba75562d36068f # 你要从哪些集群节点给node4节点6379分配插槽呢?可以输入all代表所有节点平均分配 # 也可以输入所有节点node-ID以done结束,我这里是所有节点,需要node1:6379、node2:6379、node3:6379 # 共拿出4096的槽位分配给node4:6379 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1: all