
首先我们看一个现象,一般情况下我们认为sort by 应该是比 order by 快的,因为 order by 只能使用一个reducer,进行全部排序,但是当数据量比较小的时候就不一定了,因为reducer 的启动耗时可能远远数据处理的时间长,就像下面的例子order by 是比sort by快的
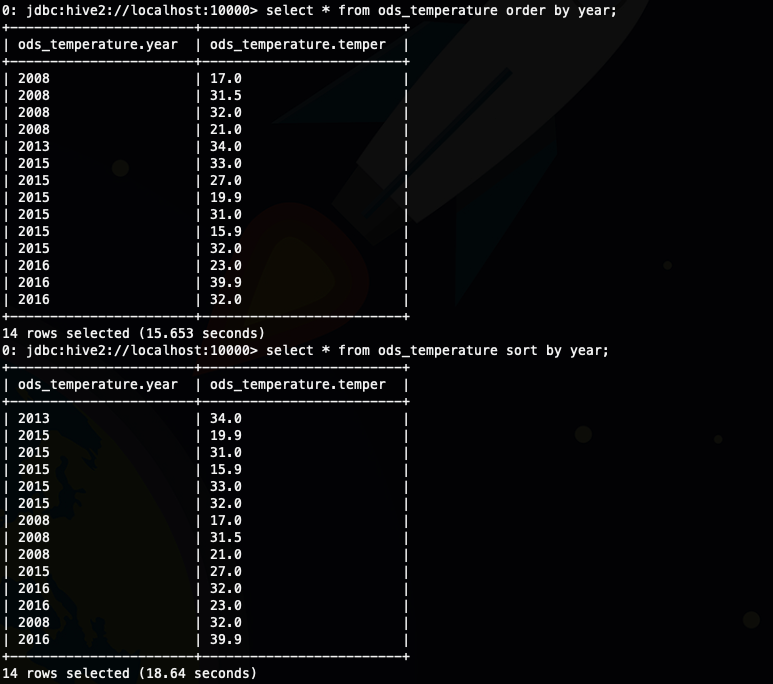
可以在sort by 用limit子句减少数据量,使用limit n 后,传输到reduce端的数据记录数就减少到 n *(map个数),也就是说我们在sort by 中使用limit 限制的实际上是每个reducer 中的数量,然后再根据sort by的排序字段进行order by,最后返回n 条数据给客户端,也就是说你在sort by 用limit子句,最后还是会使用order by 进行最后的排序
order by 中使用limit 是对排序好的结果文件去limit 然后交给reducer,可以看到sort by 中limit 子句会减少参与排序的数据量,而order by 中的不行,只会限制返回客户端数据量的多少。
从上面的执行效率,我们看到sort by limit 几乎是 order by limit 的两倍了 ,大概才出来应该是多了某个环节
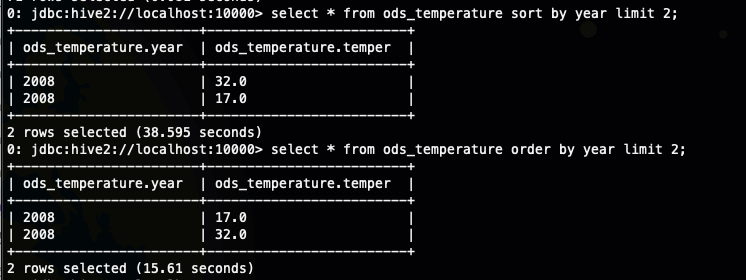
接下来我们分别看一下order by limit 和 sort by limit 的执行计划
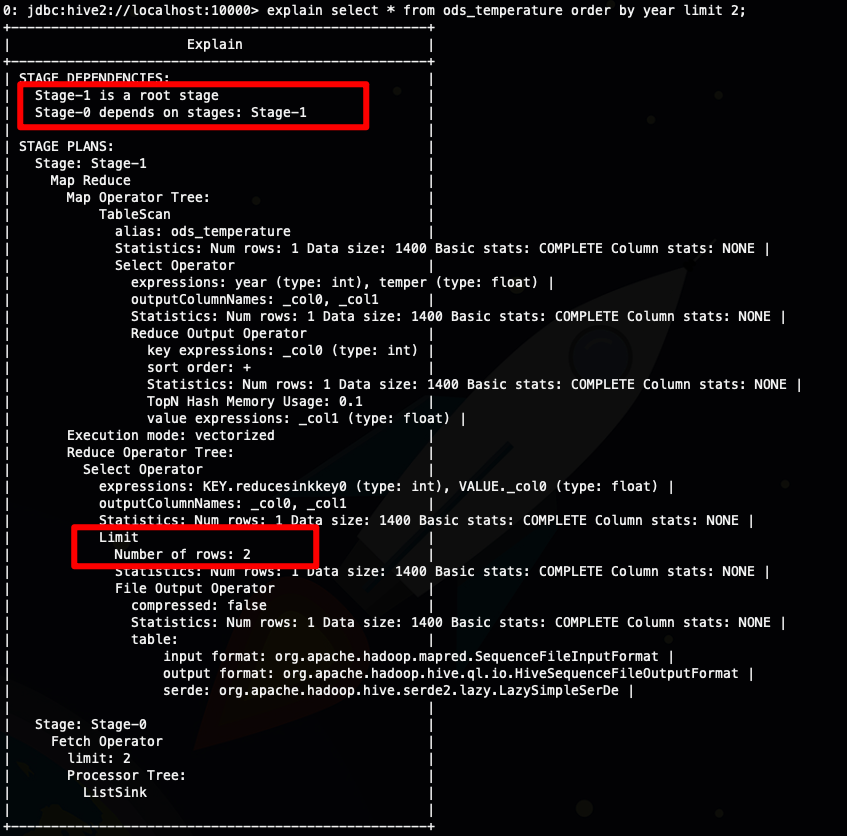
explain select * from ods_temperature order by year limit 2;
explain select * from ods_temperature sort by year limit 2;
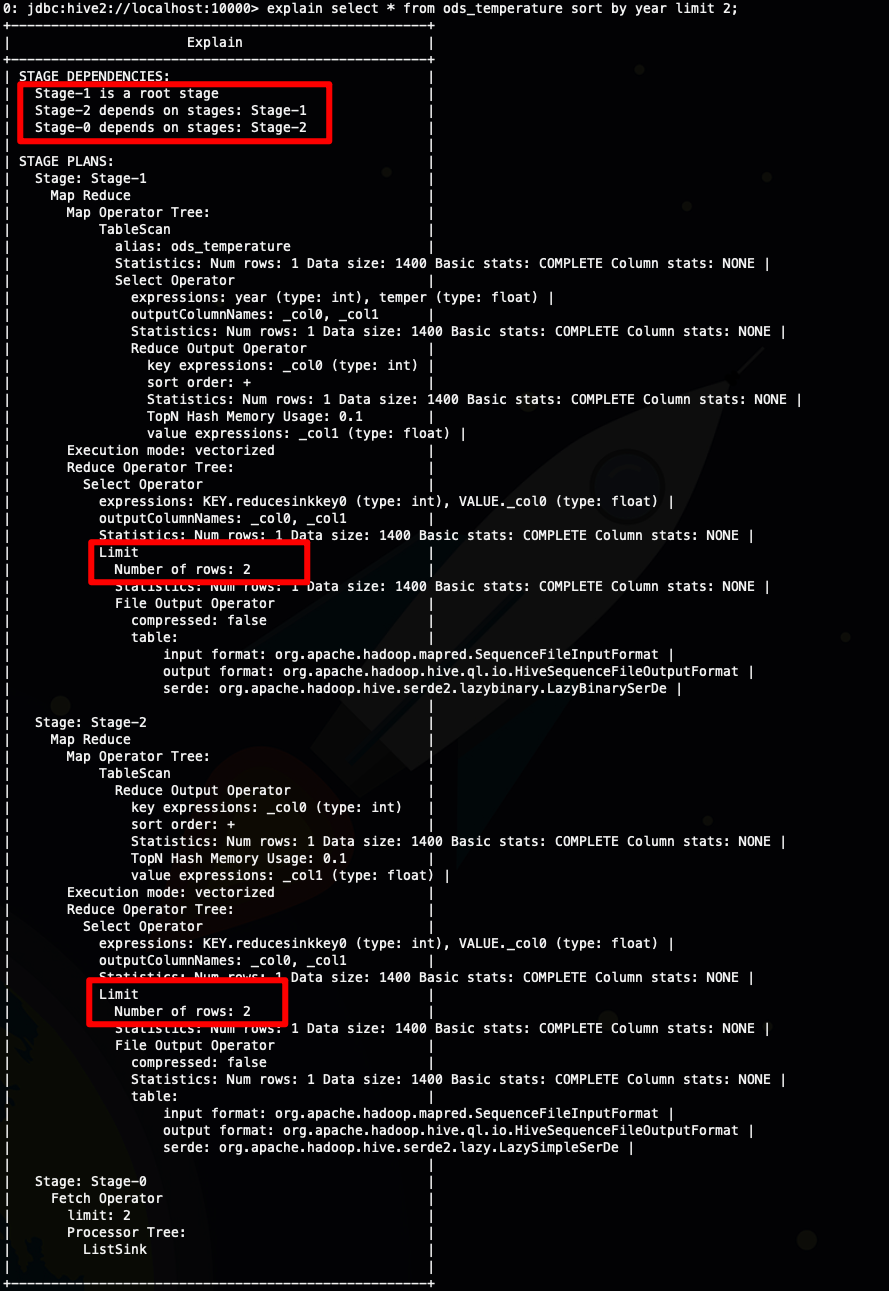
从上面截图我圈出来的地方可以看到
sort by limit 比 order by limit 多出了一个stage(order limit)
sort by limit 实际上执行了两次limit ,减少了参与排序的数据量
3. distribute by(数据分发)distribute by是控制在map端如何拆分数据给reduce端的。类似于MapReduce中分区partationer对数据进行分区
hive会根据distribute by后面列,将数据分发给对应的reducer,默认是采用hash算法+取余数的方式。
sort by为每个reduce产生一个排序文件,在有些情况下,你需要控制某写特定的行应该到哪个reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。
例如上面的sort by 的例子中,我们发现不同年份的数据并不在一个文件中,也就说不在同一个reducer 中,接下来我们看一下如何将相同的年份输出在一起,然后按照温度升序排序
首先我们尝试一下没有distribute by 的SQL的实现
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t' select * from ods_temperature sort by temper ;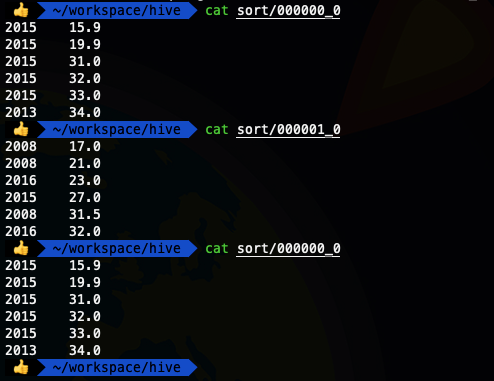
发现结果并没有把相同年份的数据分配在一起,接下来我们使用一下distribute by
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'select * from ods_temperature distribute by year sort by temper ;
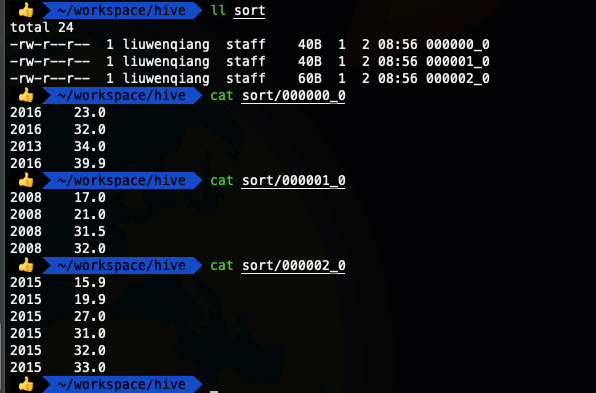
这下我们看到相同年份的都放在了一下,可以看出2013 和 2016 放在了一起,但是没有一定顺序,这个时候我们可以对 distribute by 字段再进行一下排序
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'select * from ods_temperature distribute by year sort by year,temper ;
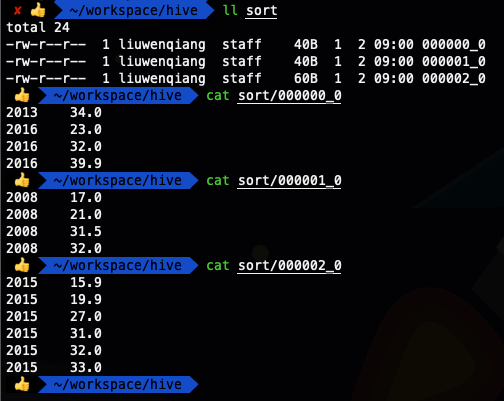
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。