
当分区字段和排序字段相同cluster by可以简化distribute by+sort by 的SQL 写法,也就是说当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'select * from ods_temperature distribute by year sort by year ;
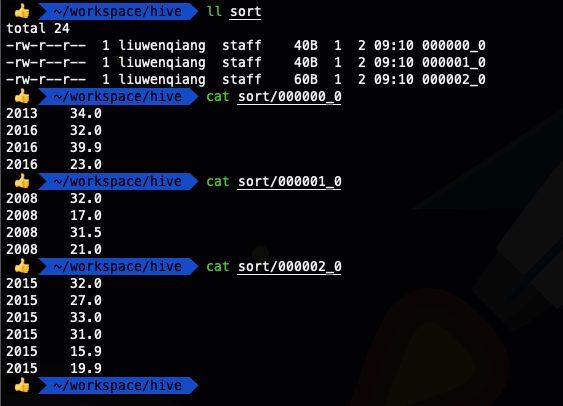
select * from ods_temperature cluster by year;
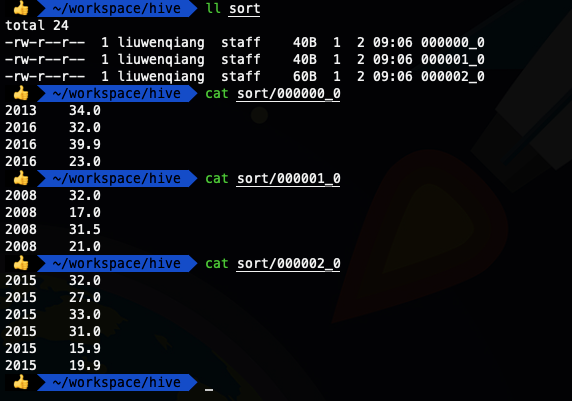
我们看到上面两种SQL写法的输出结果是一样的,这也就证明了我们的说法,当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by
当你尝试给cluster by 指定排序方向的时候,你就会得到如下错误。
Error: Error while compiling statement: FAILED: ParseException line 2:46 extraneous input 'desc' expecting EOF near '<EOF>' (state=42000,code=40000)总结
order by 是全局排序,可能性能会比较差;
sort by分区内有序,往往配合distribute by来确定该分区都有那些数据;
distribute by 确定了数据分发的规则,满足相同条件的数据被分发到一个reducer;
cluster by 当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by,但是cluster by默认是升序,不能指定排序方向;
sort by limit 相当于每个reduce 的数据limit 之后,进行order by 然后再limit ;