接下来是群集安装,这一步点选使用Parcel(建议),将网络地址全部删除,退出来后要能看到可以选择本地包才说明本地配置对了,如果没看到,可能有以下几个原因
未将CDH-5.8.0-1.cdh5.8.0.p0.42-el6.parcel.sha1,重命名为CDH-5.8.0-1.cdh5.8.0.p0.42-el6.parcel.sha
cloudera,parcel-repo和parcels三个文件夹的权限设置没有设置好。

安装完成后如上图。
5.3.检查主机正确性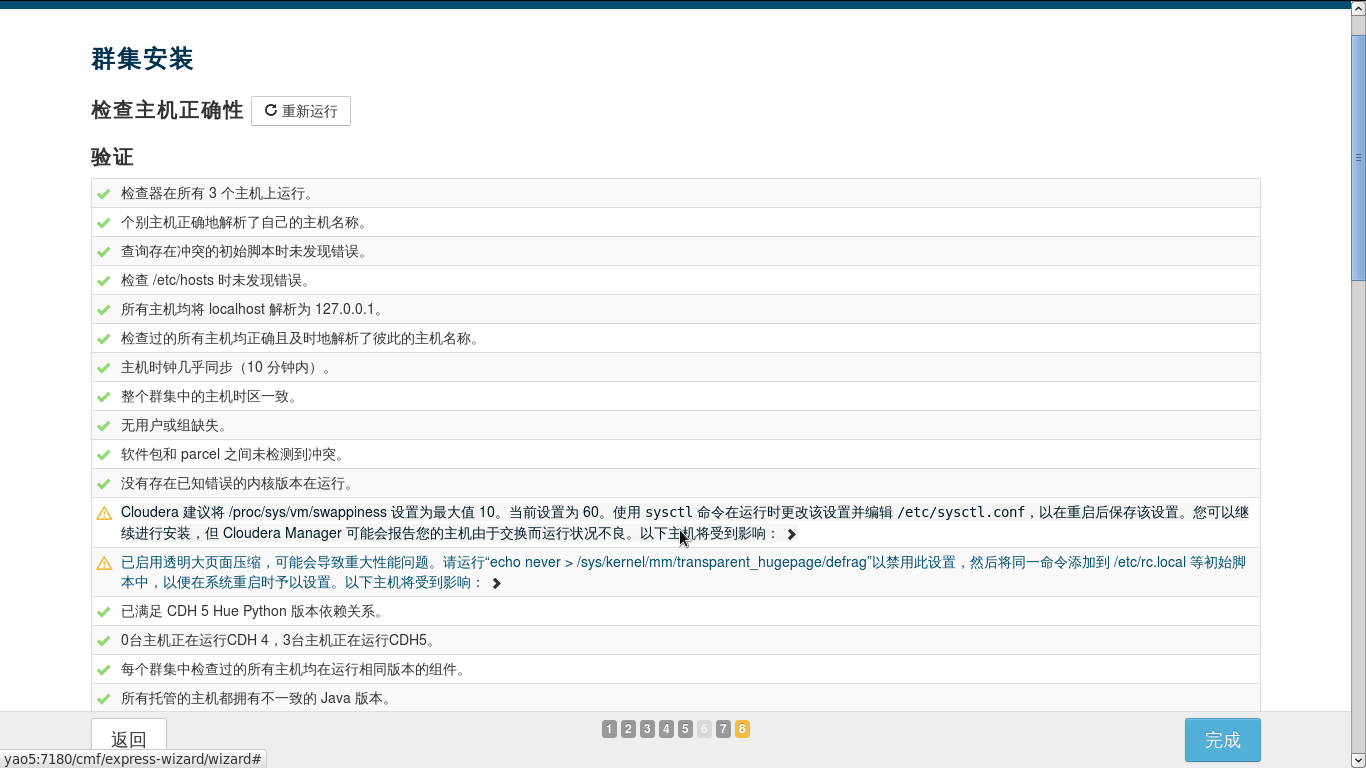
如果出现和上图一样,就说明离成功又近了一步,如果出现了其他错误,比如出现JAVA版本不一致,想想你是不是自己安JDK了,这个地方会导致后面Spark安装失败,没有例外,因为这里我们起码重装了5次,才发现必须用官方给的JDK。
按照给出的方式修改,输入
echo 10 > /proc/sys/vm/swappiness
echo never > /sys/kernel/mm/transparent_hugepage/defrag
如果你想重启后不出问题,可以按上面的修改其他那些文件。
修改完后点击重新运行,得到以下样子

是不是看起来很舒服。
5.4.选择在集群上安装的服务
我们选择安装含Spark的内核
5.5.自定义角色分配
注意将DataNode选成所有主机,还有下面的Zookeeper选成所有主机,其他默认就可以了。
5.6.数据库设置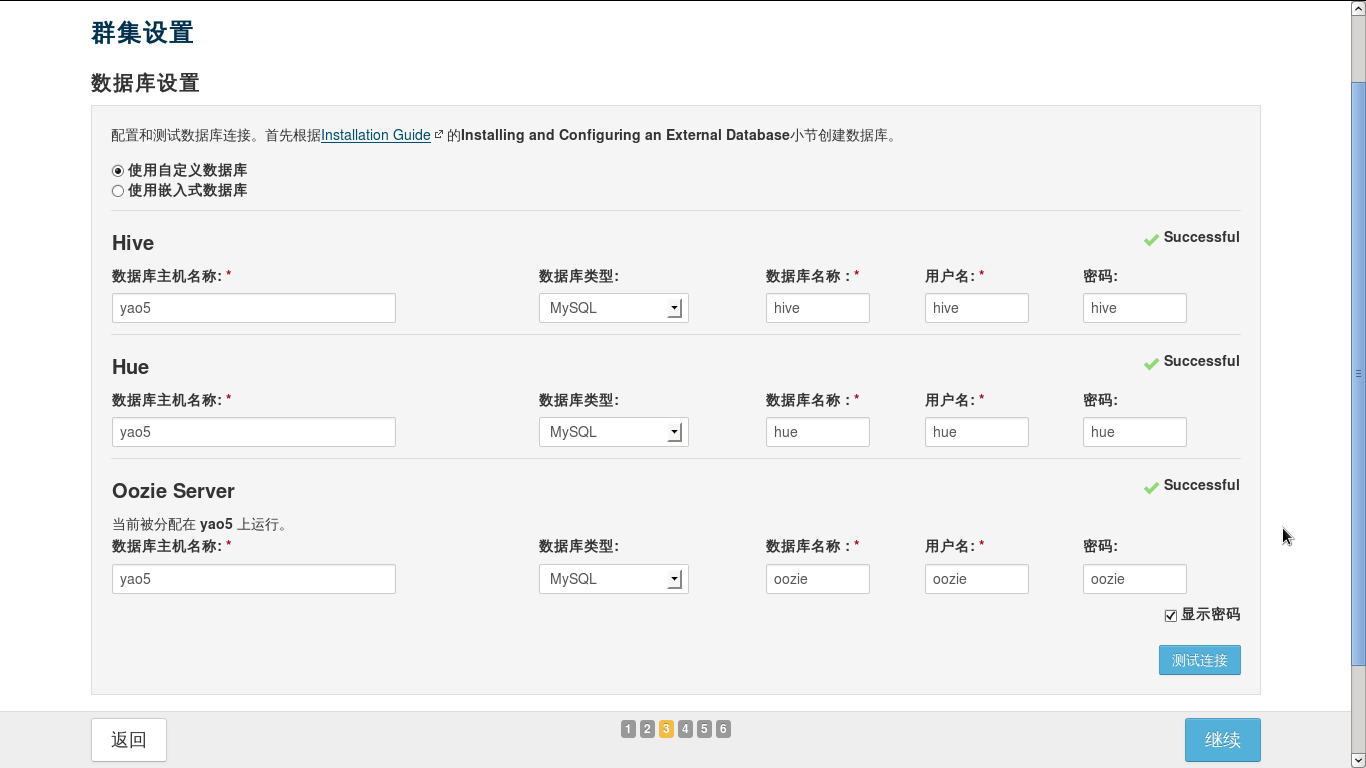
之前已经配置过数据库,直接像上面那样填即可,可能会在Hue测试连接的时候失败,那就是你没有安装完MySQL包里share,最好全部安装,防止报各种奇怪的错。
5.7.所需目录结构
默认即可,不用改动什么。
5.8.等待初始化和启动服务这个地方初始化可能会出各种问题
1.Spark报错,一般都是JDK未使用官方版本。
2.Hive,Hbase,Hue等报错,类似于下图
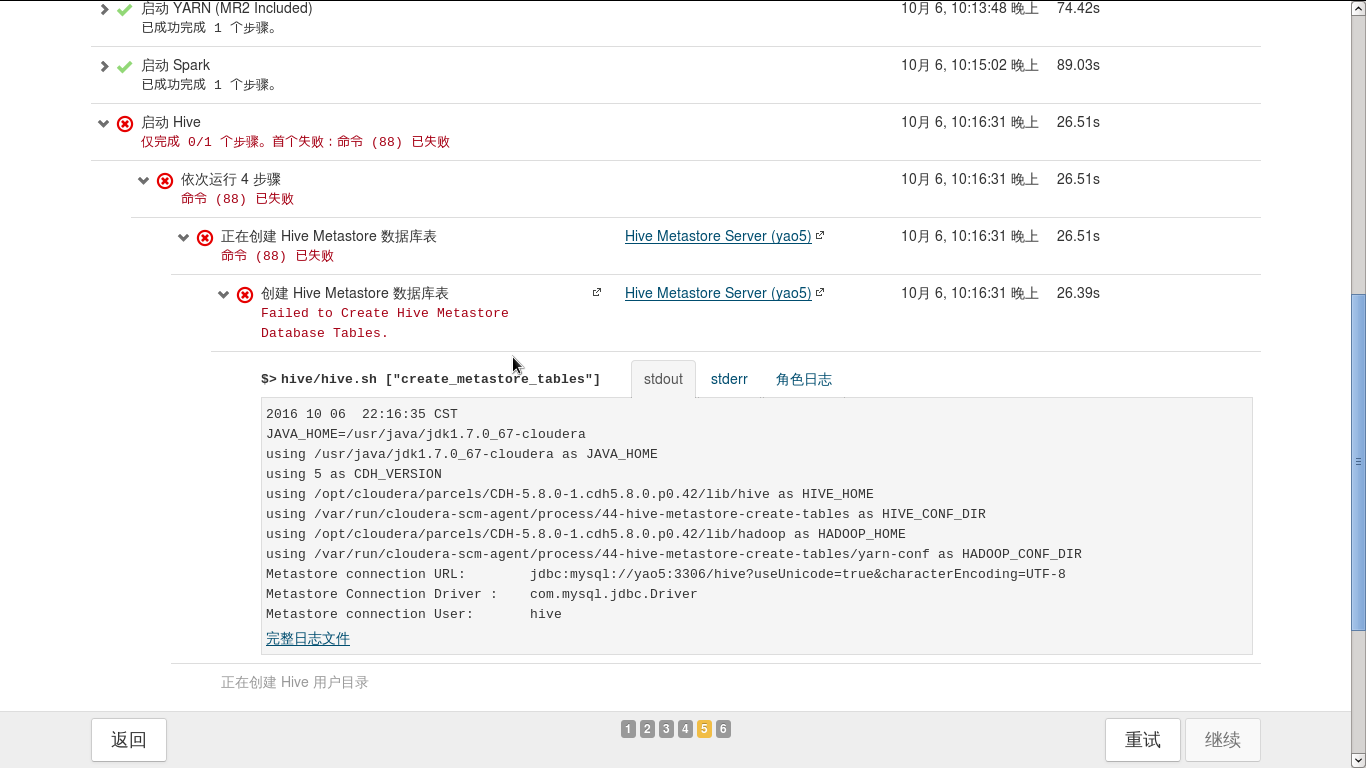
解决办法也就是将mysql-connector-java-5.1.6-bin.jar拷贝到hive存放jar文件的目录重试即可。
cp mysql-connector-java-5.1.6-bin.jar /opt/cloudera/parcels/CDH-5.8.0-1.cdh5.8.0.p0.42/lib/hive/lib/
3.Oozie报错,显示timeout,这里是因为网络环境太差,传输很慢,所以要把超时时间设置久一点,我们将超时时间调到了300s。
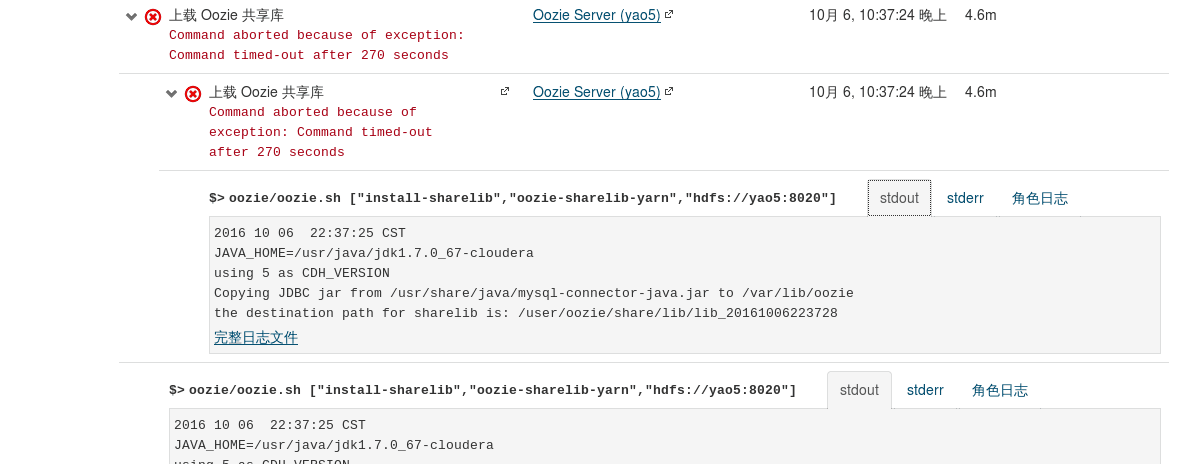
如上图出现报错,浏览器打开另一个标签页,进入:7180,点击oozie组件,搜索oozie_upload_sharelib_cmd_timeout parameter 和 change it to something bigger 然后将270改为600即可解决。
最后安装成功
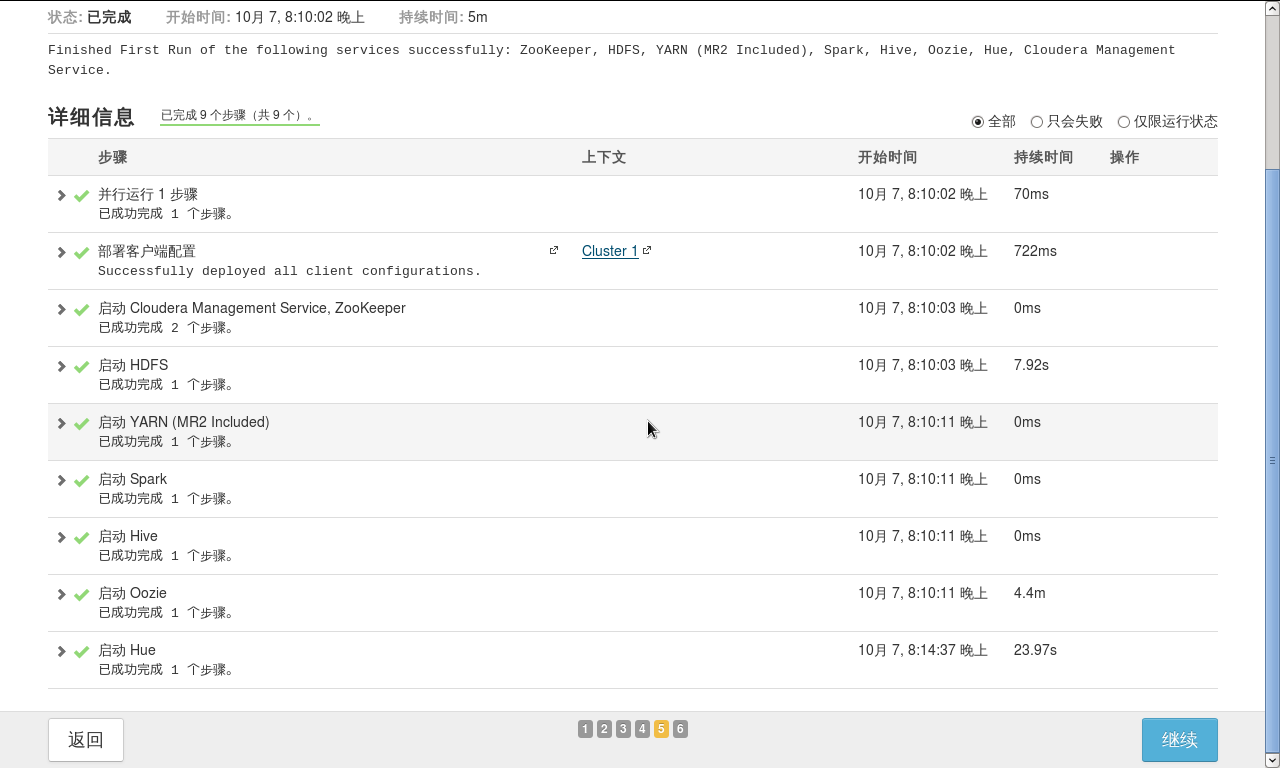
安装完成后会因为电脑过卡,内存过小,硬盘空间不够等等问题导致会有很多运行状态不佳的主机
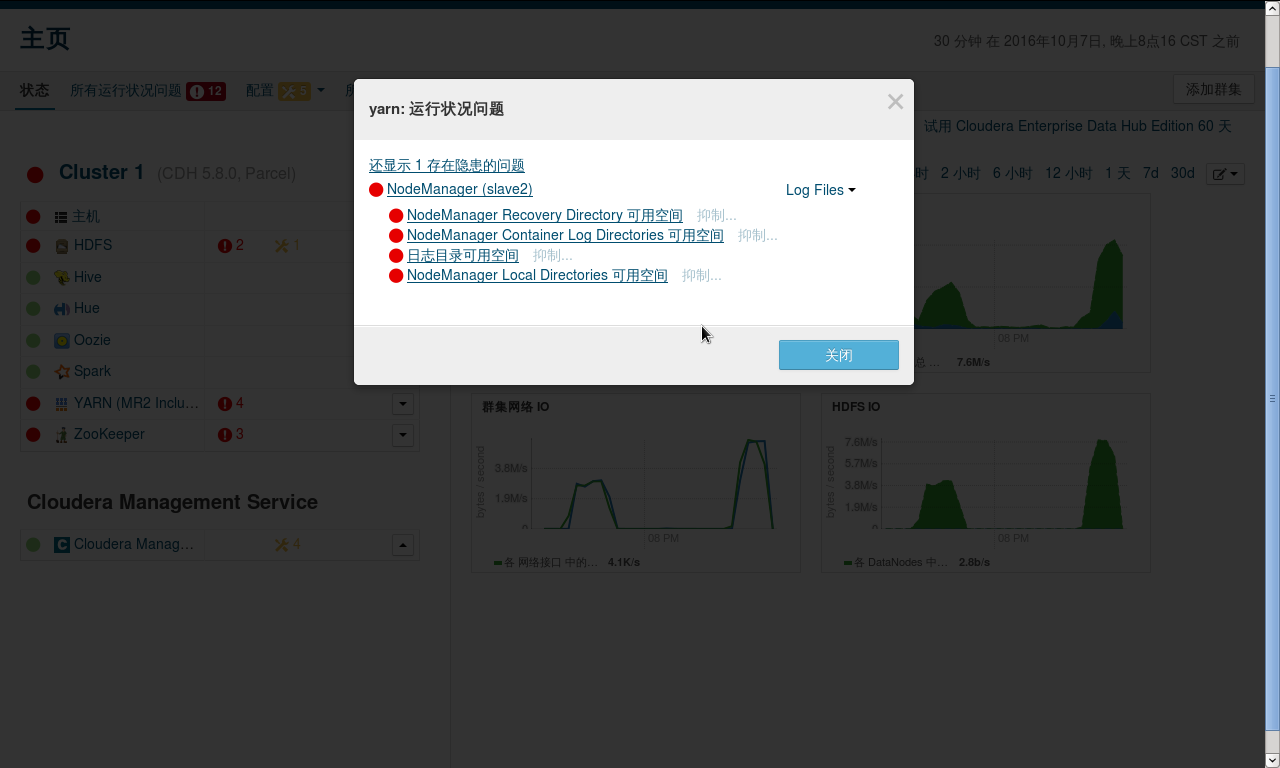
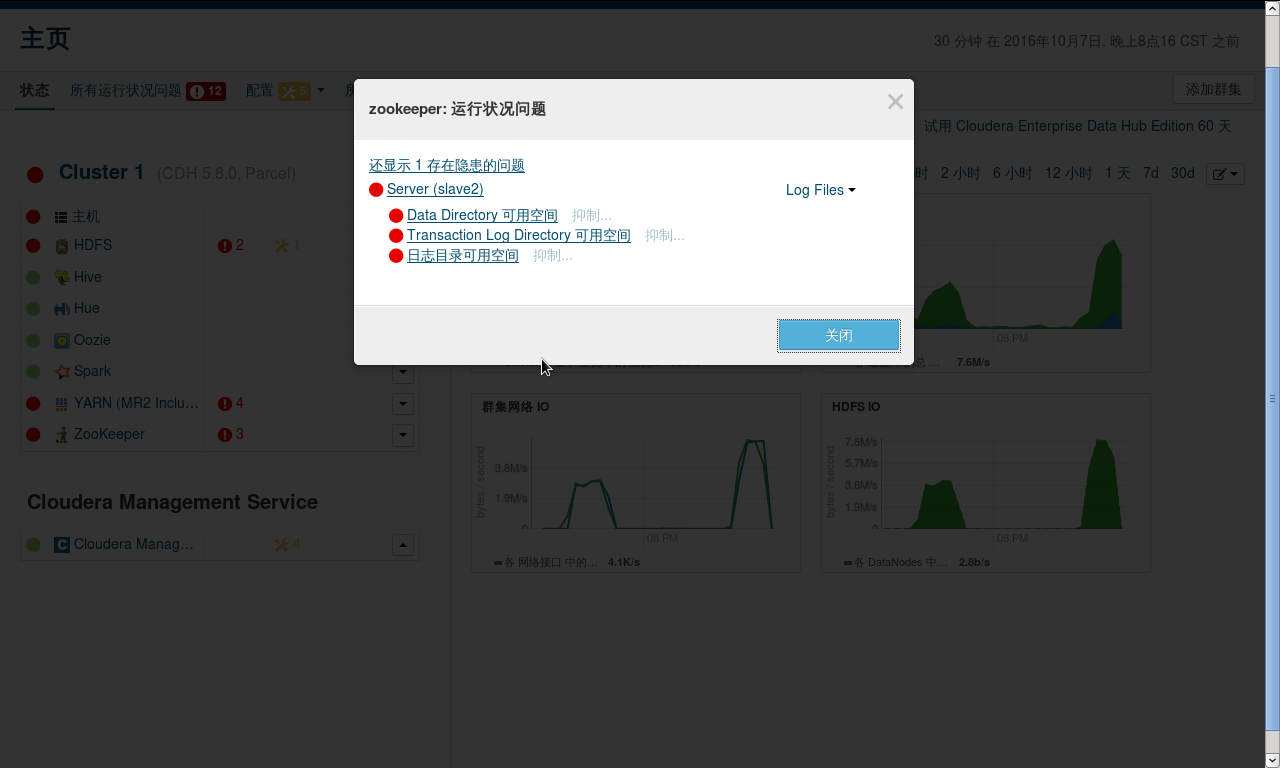
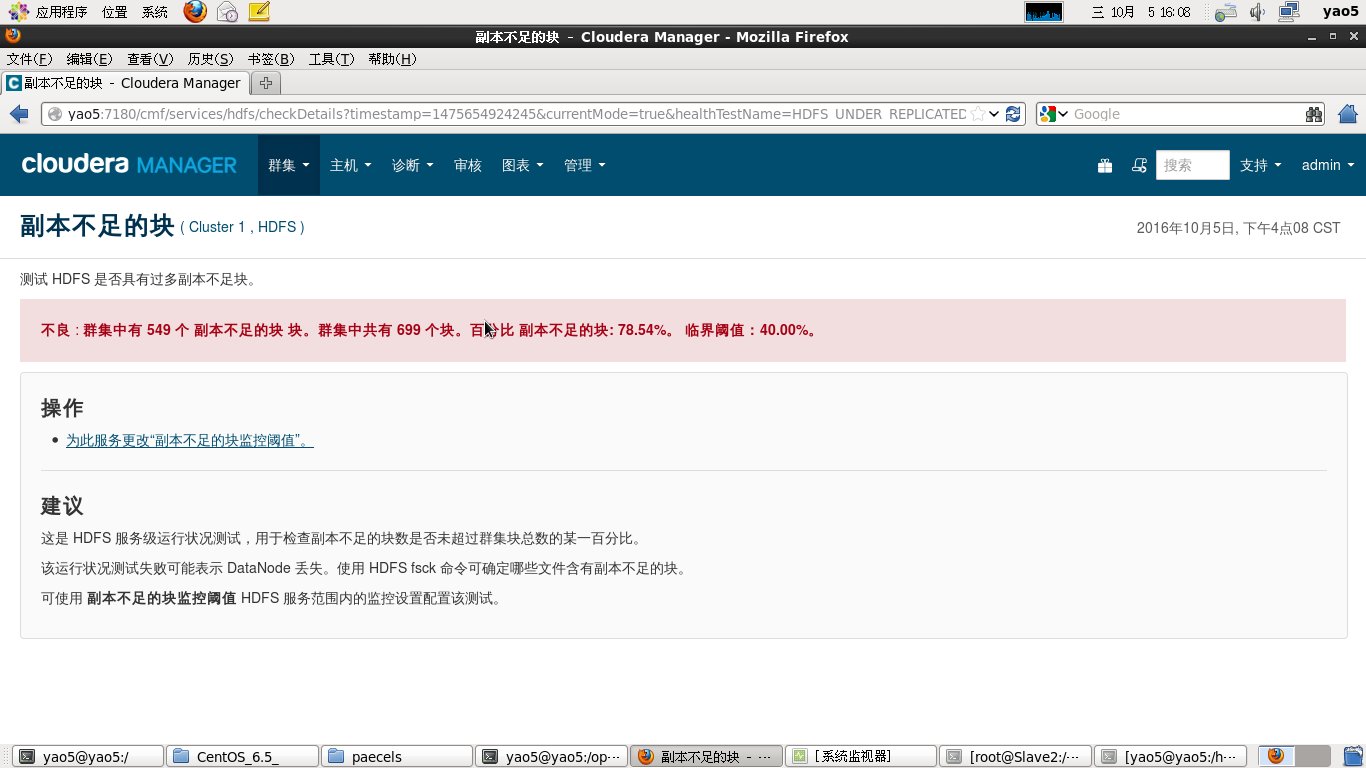
经过将内存阈值,分配空间阈值,报警阈值调小后即可解决,最后等待一会便可以达到全绿,满足强迫症的你。
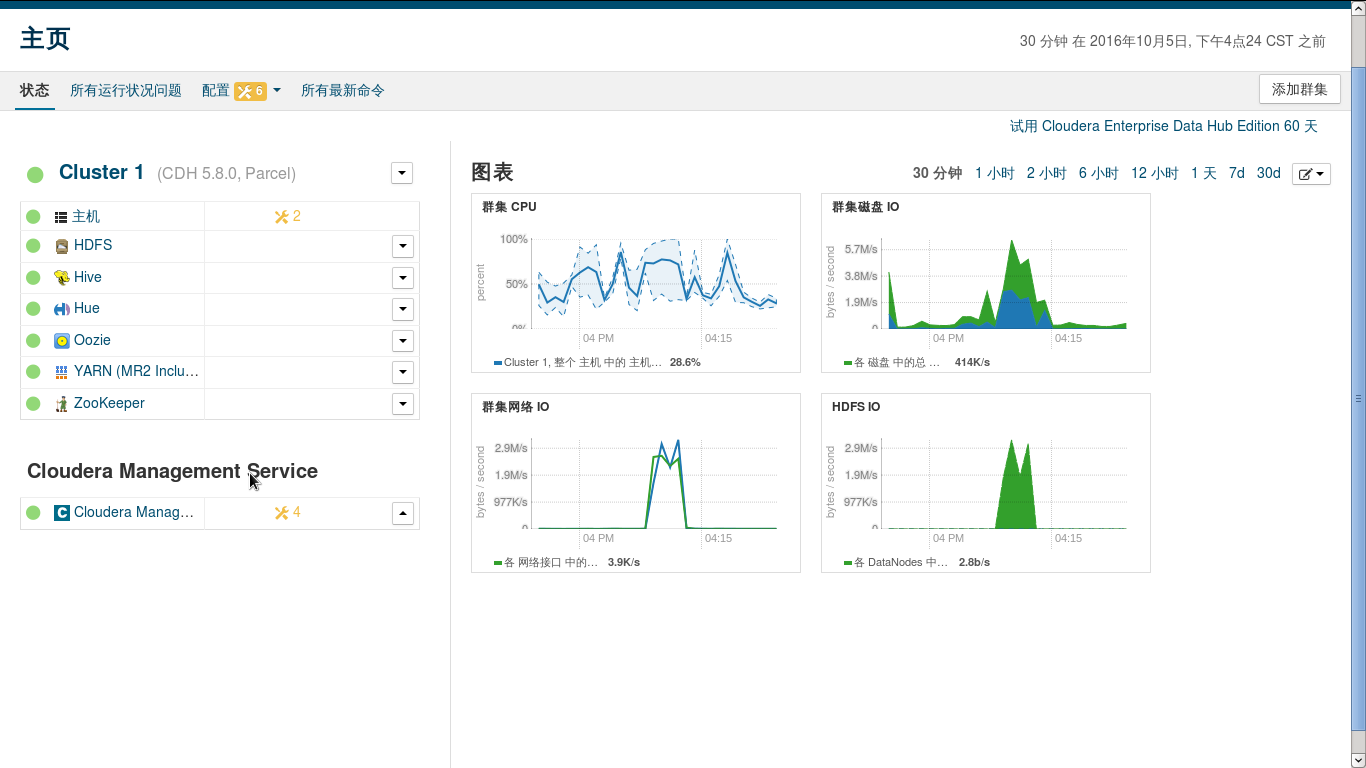
输入:8888 可以进入Hue中,使用Hive,Pig和Oozie
在终端输入spark-shell可以进入Spark-shell.
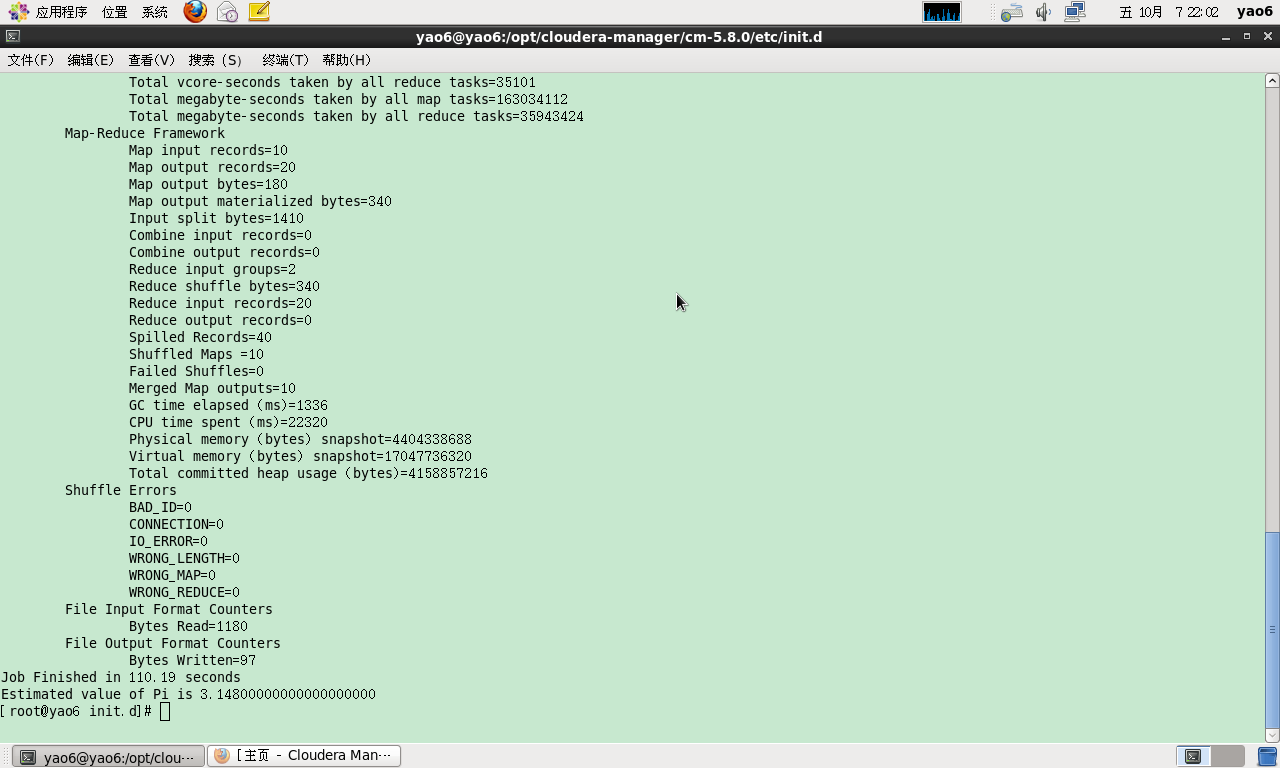
我们可以使用hdfs hadoop jar \/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \pi 10 100来测试mapreduce,运行结果如下