
根据上面表格,要解析 UTF-8 编码就很简单了,如果一个字节第一位是 0 ,则这个字节就是一个单独的字符,如果第一位是 1 ,则连续有多少个 1 ,就表示当前字符占用多少个字节
下面以 "中" 字 为例来说明 UTF-8 的编码,具体的步骤如下图, 为了便于说明,图中左边加了 1,2,3,4 的步骤编号
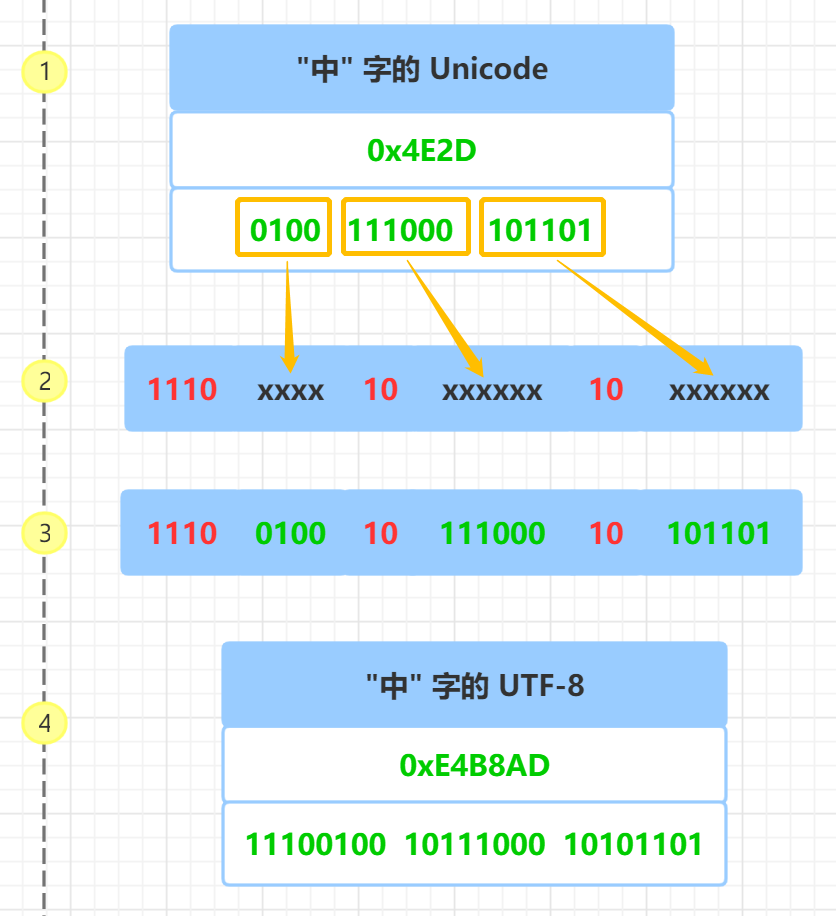
首先查询 "中" 字的 Unicode 码 0x4E2D, 转成二进制, 总共有 16 个二进制位, 具体如上图 步骤1 所示
通过前面的 Unicode 编码和 UTF-8 编码的表格知道,Unicode 码 0x4E2D 对应 000800 - 00FFFF 的范围,所以, "中" 字的 UTF-8 编码 需要 3 个字节,即格式是 1110xxxx 10xxxxxx 10xxxxxx
然后从 "中" 字的最后一个二进制位开始,按照从后向前的顺序依次填入格式中的 x 字符,多出的二进制补为 0, 具体如上图 步骤2、步骤3 所示
于是,就得到了 "中" 的 UTF-8 编码是 11100100 10111000 10101101, 转换成十六进制就是 0xE4B8AD, 具体如上图 步骤4 所示
UTF-16 编码UTF-16 也是一种变长字符编码, 这种编码方式比较特殊, 它将字符编码成 2 字节 或者 4 字节
具体的编码规则如下:
对于 Unicode 码小于 0x10000 的字符, 使用 2 个字节存储,并且是直接存储 Unicode 码,不用进行编码转换
对于 Unicode 码在 0x10000 和 0x10FFFF 之间的字符,使用 4 个字节存储,这 4 个字节分成前后两部分,每个部分各两个字节,其中,前面两个字节的前 6 位二进制固定为 110110,后面两个字节的前 6 位二进制固定为 110111, 前后部分各剩余 10 位二进制表示符号的 Unicode 码 减去 0x10000 的结果
大于 0x10FFFF 的 Unicode 码无法用 UTF-16 编码
下表是Unicode编码对应UTF-16编码格式
Unicode编码范围(16进制) 具体Unicode码(二进制) UTF-16编码方式(二进制) 字节0000 0000 - 0000 FFFF xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx 2
0001 0000 - 0010 FFFF yy yyyyyyyy xx xxxxxxxx 110110yy yyyyyyyy 110111xx xxxxxxxx 4
表格中第一列是Unicode编码的范围,第二列是 具体Unicode码的二进制 ( 第二行的第二列表示的是 Unicode 码 减去 0x10000 后的二进制 ) , 第三列是对应UTF-16编码方式,其中红色的二进制 "1" 和 "0" 是固定的前缀, 字母 x 和 y 表示可用编码的二进制位, 第四列表示 编码占用的字节数
前面提到过,"中" 字的 Unicode 码是 4E2D, 它小于 0x10000,根据表格可知,它的 UTF-16 编码占两个字节,并且和 Unicode 码相同,所以 "中" 字的 UTF-16 编码为 4E2D
我从 Unicode字符表网站 找了一个老的南阿拉伯字母, 它的 Unicode 码是: 0x10A6F , 可以访问 https://unicode-table.com/cn/10A6F/ 查看字符的说明, Unicode 码对应的字符如下图所示

下面以这个 老的南阿拉伯字母的 Unicode 码 0x10A6F 为例来说明 UTF-16 4 字节的编码,具体步骤如下,为了便于说明,图中左边加了 1,2,3,4 、5 的步骤编号
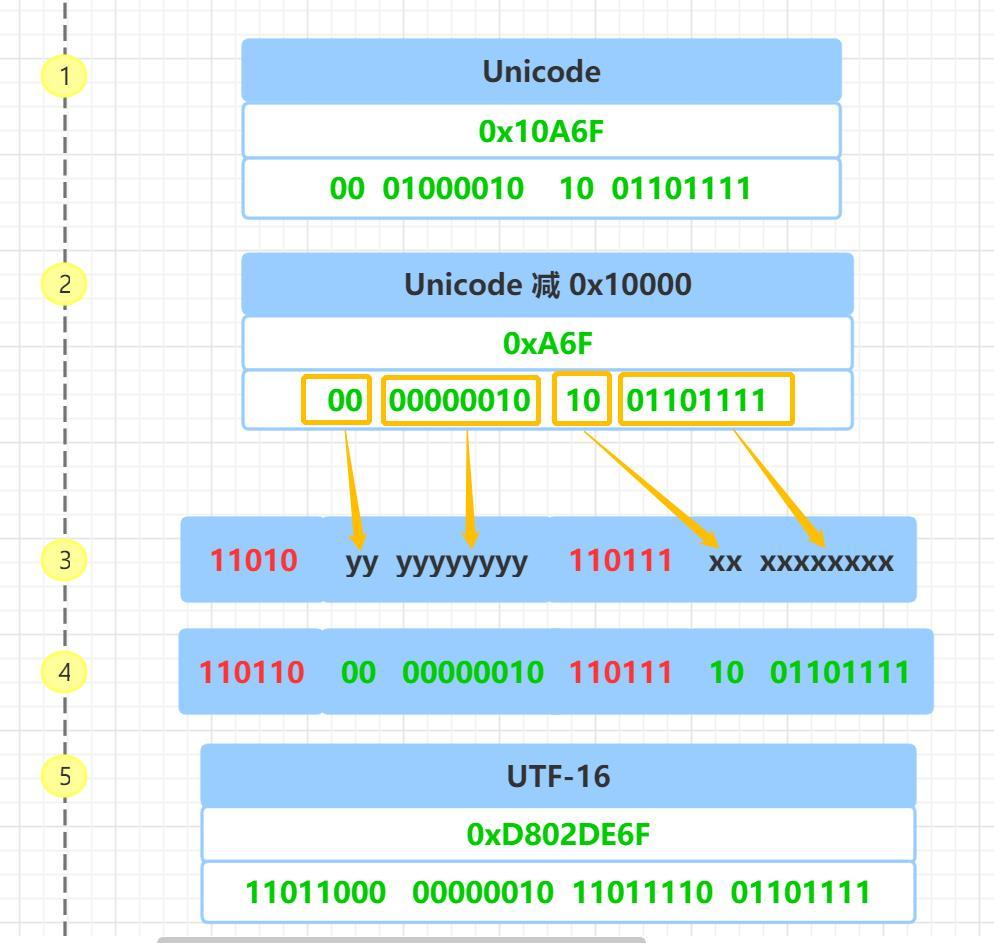
首先把 Unicode 码 0x10A6F 转成二进制, 对应上图的 步骤 1
然后把 Unicode 码 0x10A6F 减去 0x10000, 结果为 0xA6F 并把这个值转成二进制 00 00000010 10 01101111,对应上图的 步骤 2
然后 从二进制 00 00000010 10 01101111 的最后一个二进制为开始,按照从后向前的顺序依次填入格式中的 x 和 y 字符,多出的二进制补为 0, 对应上图的 步骤 3、 步骤 4