
MySQL 中的 "utf8" 实际上不是真正的 UTF-8, "utf8" 只支持每个字符最多 3 个字节, 对于超过 3 个字节的字符就会出错, 而真正的 UTF-8 至少要支持 4 个字节
MySQL 中的 "utf8mb4" 才是真正的 UTF-8
下面以 test 表为例来说明, 表结构如下: mysql> show create table test\G *************************** 1. row *************************** Table: test Create Table: CREATE TABLE `test` ( `name` char(32) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.00 sec)
向 test 表分别插入 "中" 字 和 Unicode 码为 0x10A6F 的字符,这个字符需要从 https://unicode-table.com/cn/10A6F/ 直接复制到 MySQL 控制台上,手工输入会无效,具体的执行结果如下图:

从上图可以看出,插入 "中" 字 成功,插入 0x10A6F 字符失败,错误提示无效的字符串,\xF0\X90\XA9\xAF 正是 0x10A6F 字符的 UTF-8 编码,占用 4 个字节, 因为 MySQL 的 utf8 编码最多只支持 3 个字节,所以插入会失败
把 test 表的字符集改成 utf8mb4 , 排序规则 改成 utf8bm4_unicode_ci, 具体如下图所示:
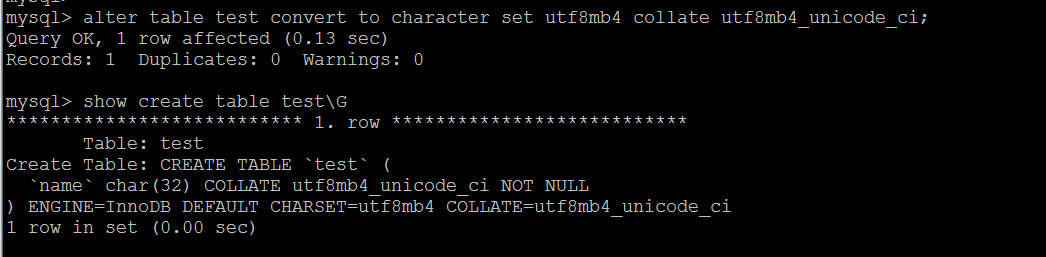
字符集和排序方式修改之后,再次插入 0x10A6F 字符, 结果是成功的,具体执行结果如下图所示
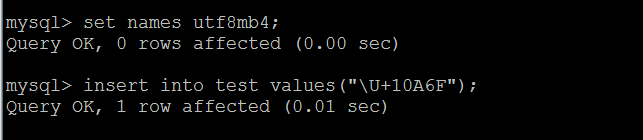
上图中,set names utf8mb4 是为了测试方便,临时修改当前会话的字符集,以便保持和 服务器一致,实际解决这个问题需要修改 my.cnf 配置中 服务器和客户端的字符集
小结本文从字符编码的历史介绍了 Unicode 出现的原因,接着介绍了 Unicode 字符集中 三种不同的编码方式: UTF-8、UTF-16、UTF-32 以及它们的的编码方法,紧接着介绍了 字节序、BOM ,最后讲到了字符集在 MySQL 和 Redis 应用中常见的问题以及解决方案 ,更多关于 Unicode 的介绍请参考 Unicode 的 RFC 文档