
因为要同时部署两个docker镜像,这里推荐使用docker-composer,桌面版安装完成后就带有该命令,需要的配置如下:
services: kibana: image: kibana:7.2.0 container_name: kibana-simple environment: - TIMELION_ENABLED=true ports: - "5601:5601" networks: - mynetwork elasticsearch: image: elasticsearch:7.2.0 container_name: es-simple environment: - cluster.name=mytestes #这里就是ES集群的名称 - node.name=es-simple #节点名称 - bootstrap.memory_lock=true - network.publish_host=elasticsearch #节点发布的网络名称 - discovery.seed_hosts=es-simple #设置集群中的主机地址 - cluster.initial_master_nodes=es-simple #手动设置可以成为master的节点集合 ulimits: memlock: soft: -1 hard: -1 volumes: - esdata1:/usr/local/elasticsearch/simpledata ports: - 9200:9200 networks: - mynetwork volumes: esdata1: driver: local networks: mynetwork: driver: bridge创建一个名称为docker-compose.yaml文件,复制下面的配置到文件中,然后再文件所在目录执行docker-compose up,之后会启动两个docker实例,分别是elasticsearch和kibana。
在本地浏览器中,访问:5601/,可以看到kibana的界面如下:
创建好的kibana已经默认添加了Elasticsearch的配置,通过管理工具可以很方便的查看ES集群的状态,索引情况,删除索引等。
下面通过dev tools创建索引,dev tools提供的命令提示很方便,并且可以把已写好的请求保存在浏览器缓存中,非常适合用来学习Elasticsearch。
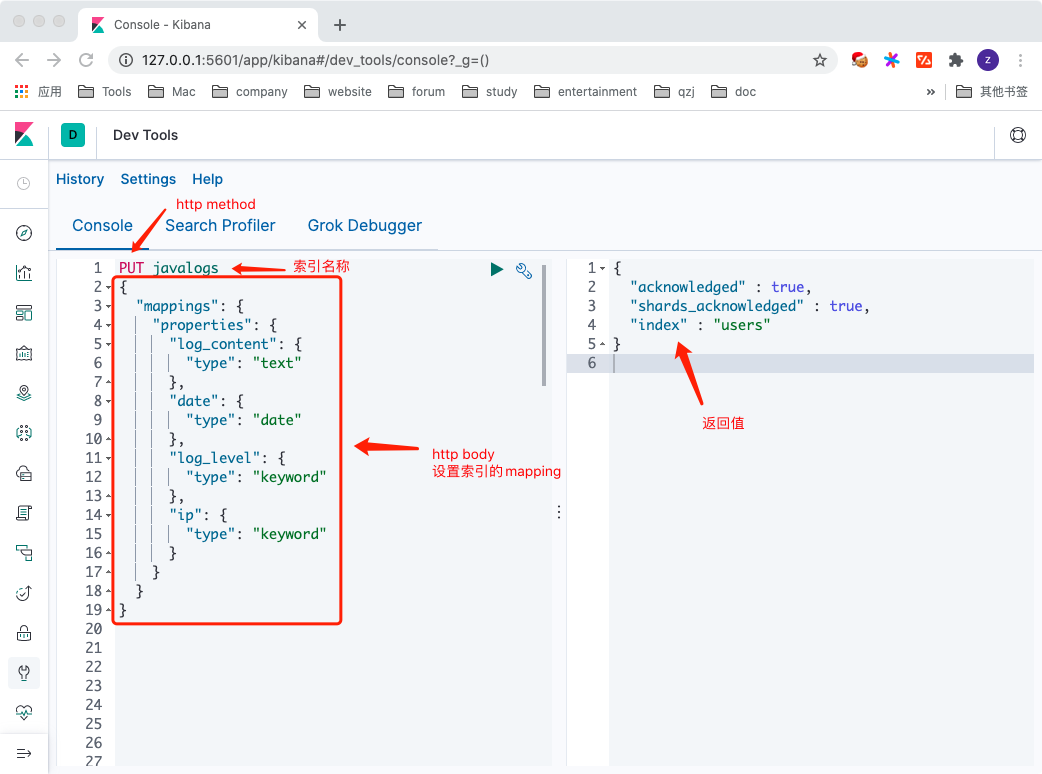
这里通过ES提供的RESTful Api创建了第一个索引, 并且设置了该索引中的mapping,ES的地址已经设置过,这里可以不写完整的域名,对应的curl完整请求如下:
curl --location --request PUT 'http://127.0.0.1:9200/javalogs' \ --header 'Content-Type: application/json' \ --data-raw '{ "mappings": { "properties": { "log_content": { "type": "text" }, "date": { "type": "date" }, "log_level": { "type": "keyword" }, "ip": { "type": "keyword" } } } }' 常用RESTful Api示例下面介绍下Elasticsearch中常用的api,这些例子都是直接在kibana的dev tools中运行的,如果想用curl访问,可参考前一节中的转换例子。
新增文档 //自动生成_id POST javalogs/_doc { "log_content" : "get user_id 123456", "date" : "2020-04-15T11:09:08", "log_level": "info", "ip": "10.223.32.67" } //指定_id POST javalogs/_doc/111 { "log_content" : "api response in 55ms", "date" : "2020-04-15T11:09:07", "log_level": "info", "ip": "10.223.32.67" } 查询文档-不分词类型ES在文档查询时,对于不分词的查询,直接按值查询即可,例如下面这样:
//不分词类型查询 POST javalogs/_search { "query": { "match": { "ip": "10.223.32.67" } } } 查询文档-分词类型这里主要说下分词类型的查询,对于分析类型的field在查询时,也会默认把查询的语句分词。假设有两个文档如下:
//文档1 { "log_content" : "call aaa service error", "date" : "2020-04-15T11:09:07", "log_level": "error", "ip": "10.223.32.67" } //文档2 { "log_content" : "call bbb service error", "date" : "2020-04-15T11:09:08", "log_level": "error", "ip": "10.223.32.67" }当搜索条件为call aaa service时,实际上会把两个文档都搜索出来。
这是因为在搜索时,条件call aaa service会被分词为call,aaa和service,所有包含这三个词的文档都会被搜索出来,例如下面:
那如果想要只搜索包含call aaa service的文档,应该如何做呢?
按照上面的分析,需要同时包含这三个词,并且按照给定的顺序,才返回对应的文档,那么这个可以使用match_phrase实现,示例如下:
//文档必须同时包含三个词,并且顺序与搜索条件一致才会返回。这里只会返回-文档1 POST javalogs/_search { "profile": "true", "query": { "match_phrase": { "log_content": "call aaa service" } } }那如果条件是包含call,aaa和service,但是不一定是连着的,该如何搜索呢?可以使用operator操作符实现。
例如有第三个文档如下:
//文档3 { "log_content" : "call inner aaa service error", "date" : "2020-04-15T11:09:08", "log_level": "error", "ip": "10.223.32.67" }