单个词查询:指对一个 Term 进行查询。比如,若要查找包含字符串“Lucene”的文档,则只需在词典中找到 Term“Lucene”,再获得在倒排表中对应的文档链表即可。
AND:指对多个集合求交集。比如,若要查找既包含字符串“Lucene”又包含字符串“Solr”的文档,则查找步骤如下:在词典中找到 Term “Lucene”,得到“Lucene”对应的文档链表。在词典中找到 Term “Solr”,得到“Solr”对应的文档链表。合并链表,对两个文档链表做交集运算,合并后的结果既包含“Lucene”也包含“Solr”。
OR:指多个集合求并集。比如,若要查找包含字符串“Luence”或者包含字符串“Solr”的文档,则查找步骤如下:在词典中找到 Term “Lucene”,得到“Lucene”对应的文档链表。在词典中找到 Term “Solr”,得到“Solr”对应的文档链表。合并链表,对两个文档链表做并集运算,合并后的结果包含“Lucene”或者包含“Solr”。
NOT:指对多个集合求差集。比如,若要查找包含字符串“Solr”但不包含字符串“Lucene”的文档,则查找步骤如下:在词典中找到 Term “Lucene”,得到“Lucene”对应的文档链表。在词典中找到 Term “Solr”,得到“Solr”对应的文档链表。合并链表,对两个文档链表做差集运算,用包含“Solr”的文档集减去包含“Lucene”的文档集,运算后的结果就是包含“Solr”但不包含“Lucene”。
通过上述四种查询方式,我们不难发现,由于 Lucene 是以倒排表的形式存储的。所以在 Lucene 的查找过程中只需在词典中找到这些 Term,根据 Term 获得文档链表,然后根据具体的查询条件对链表进行交、并、差等操作,就可以准确地查到我们想要的结果。相对于在关系型数据库中的“Like”查找要做全表扫描来说,这种思路是非常高效的。虽然在索引创建时要做很多工作,但这种一次生成、多次使用的思路也是很高明的。
1.5 ES特性Elasticsearch可扩展高达PB级的结构化和非结构化数据。
Elasticsearch可以用来替代MongoDB和RavenDB等做文档存储。
Elasticsearch使用非标准化来提高搜索性能。
Elasticsearch是受欢迎的企业搜索引擎之一,目前被许多大型组织使用,如Wikipedia,The Guardian,StackOverflow,GitHub等。
Elasticsearch是开放源代码,可在Apache许可证版本2.0下提供。
1.6 ES优点Elasticsearch是基于Java开发的,这使得它在几乎每个平台上都兼容。
Elasticsearch是实时的,换句话说,一秒钟后,添加的文档可以在这个引擎中搜索得到。
Elasticsearch是分布式的,这使得它易于在任何大型组织中扩展和集成。
通过使用Elasticsearch中的网关概念,创建完整备份很容易。
与Apache Solr相比,在Elasticsearch中处理多租户非常容易。
Elasticsearch使用JSON对象作为响应,这使得可以使用不同的编程语言调用Elasticsearch服务器。
Elasticsearch支持几乎大部分文档类型,但不支持文本呈现的文档类型。
1.7 ES缺点Elasticsearch在处理请求和响应数据方面没有多语言和数据格式支持(仅在JSON中可用),与Apache Solr不同,Elasticsearch不可以使用CSV,XML等格式。
Elasticsearch也有一些伤脑的问题发生,虽然在极少数情况下才会发生。
2 ES的安装部署本文主要采用Win10下的Elasticsearch安装,当然Linux安装操作起来更加简便了。完成之后对python安装elasticsearch包,并实现交互案例。
第一步:条件检查:Elasticsearch至少需要Java 8,首先需要java -version查看当前版本。
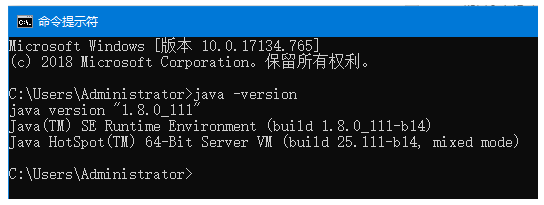
第二步:安装ES,这里采用elasticsearch-7.1.0-windows-x86_64下载地址链接: https://pan.baidu.com/s/1k5AOGpMy8uJEXtA6KoNb7g 提取码: qtmj 。