
2019年5月24日17:22:41
导读:件开发最大的麻烦事之一就是环境配置,操作系统设置,各种库和组件的安装。只有它们都正确,软件才能运行。如果从一种操作系统里面运行另一种操作系统,通常我们采取的策略就是引入虚拟机,比如在 Windows 系统里面运行 Linux 系统。这种方式有个很大的缺点就是资源占用多、冗余步骤多、启动慢。目前最流行的 Linux 容器解决方案之一就是Docker,它最大优点就是轻量、资源占用少、启动快。本文从什么是Docker?Docker解决什么问题?有哪些好处?如何去部署实现去全面介绍。
1 ES基本介绍1.1 概念介绍
Elasticsearch是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,它可以快速地储存、搜索和分析海量数据。Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch至少需要Java 8。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
集群(Cluster):集群是一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
节点(Node):节点是作为集群一部分的单个服务器,存储数据并参与群集的索引和搜索功能。
索引(Index):索引是具有某些类似特征的文档集合。索引由名称标识(必须全部小写),此名称用于在对其中的文档执行索引,搜索,更新和删除操作时引用索引。 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
文档(Document):文档是可以编制索引的基本信息单元。Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。Document 使用 JSON 格式表示,同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
分片和副本(Shards & Replicas):索引可能存储大量可能超过单个节点的硬件限制的数据。为了解决这个问题,Elasticsearch提供了将索引细分为多个称为分片的功能。创建索引时,只需定义所需的分片数即可。每个分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
副本集很重要:它在分片/节点发生故障时提供高可用性。它允许您扩展搜索量/吞吐量,因为可以在所有副本上并行执行搜索。默认情况下,Elasticsearch中的每个索引都分配了5个主分片和1个副本,这意味着如果群集中至少有两个节点,则索引将包含5个主分片和另外5个副本分片(1个完整副本),总计为每个索引10个分片。
在线网上商店,允许客户搜索您销售的产品。在这种情况下,可以使用Elasticsearch存储整个产品目录和库存,并为它们提供搜索和自动填充建议。
收集日志或交易数据,并分析和挖掘此数据以查找趋势,统计信息,摘要或异常。在这种情况下,您可以使用Logstash(Elasticsearch / Logstash / Kibana堆栈的一部分)来收集,聚合和解析数据,然后让Logstash将此数据提供给Elasticsearch。一旦数据在Elasticsearch中,您就可以运行搜索和聚合来挖掘您感兴趣的任何信息。
价格警报平台,允许精通价格的客户指定一条规则,例如“我有兴趣购买特定的电子产品,如果小工具的价格在下个月内从任何供应商降至X美元以下,我希望收到通知” 。在这种情况下,您可以刮取供应商价格,将其推入Elasticsearch并使用其反向搜索功能来匹配价格变动与客户查询,并最终在发现匹配后将警报推送给客户。
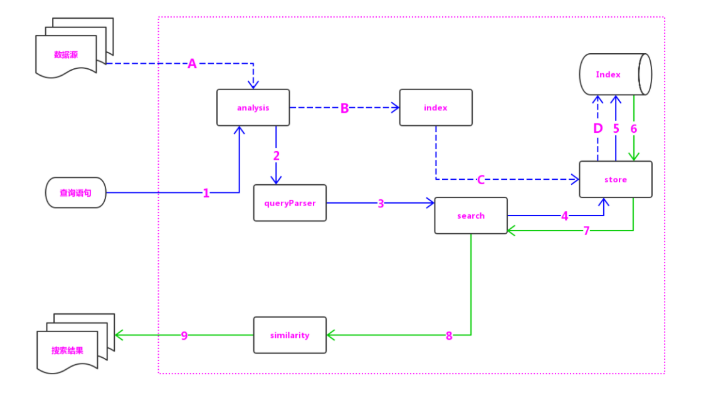
1.3 核心模块analysis:主要负责词法分析及语言处理,也就是我们常说的分词,通过该模块可最终形成存储或者搜索的最小单元 Term。
index 模块:主要负责索引的创建工作。
store 模块:主要负责索引的读写,主要是对文件的一些操作,其主要目的是抽象出和平台文件系统无关的存储。
queryParser 模块:主要负责语法分析,把我们的查询语句生成 Lucene 底层可以识别的条件。
search 模块:主要负责对索引的搜索工作。
similarity 模块:主要负责相关性打分和排序的实现。
1.4 检索方式