将心跳超时值设置得太低可能会导致误报(由于瞬时网络拥塞,短暂的服务器流控制等原因,对等体被认为是不可用的,而实际情况并非如此)。 选择超时值时应考虑这一点。
用户和客户端库维护人员几年的反馈意见表明,低于5秒的值很可能导致误报,1秒或更低的值很可能会这样做。 对于大多数环境,5到20秒范围内的值是最佳的。
某些网络工具(HAproxy,AWS ELB)和设备(硬件负载平衡器)可能会在一段时间内没有活动时终止“空闲”TCP连接。 大多数时候这是不可取的。
在连接上启用心跳时,会导致周期性的轻型网络流量。 因此,心跳具有保护客户端连接的副作用,这些客户端连接可以在一段时间内空闲,以防止代理和负载平衡器过早关闭。
心跳超时为30秒时,连接将大约每15秒产生一次定期网络流量。 5到15秒范围内的活动足以满足大多数常用代理和负载平衡器的默认值。 另请参阅上面关于低超时和误报的部分。
由于错过了心跳,RabbitMQ节点将记录连接已关闭。 所有官方支持的客户端库也将如此。 检查服务器和客户端日志将提供有价值的信息,应该是第一个故障排除步骤。
可能需要检查打开或来自节点的连接,其状态,来源,用户名和有效心跳超时值。 “网络故障排除指南”概述了可用于提供帮助的工具。
六安杨洋(AY)
===================================================================
消费者拒收消息写法 channel.BasicReject(ea.DeliveryTag, false);
BasicReject方法第一个参数是消息的DeliveryTag,对于每个Channel来说,每个消息都会有一个DeliveryTag,一般用接收消息的顺序来表示:1,2,3,4 等等。第二个参数是是否放回queue中,requeue。
BasicReject一次只能拒绝接收一个消息,而BasicNack方法可以支持一次0个或多个消息的拒收,并且也可以设置是否requeue。
channel.BasicNack(3, true, false);

QoS = quality-of-service, 顾名思义,服务的质量。通常我们设计系统的时候不能完全排除故障或保证说没有故障,而应该设计有完善的异常处理机制。在出现错误的时候知道在哪里出现什么样子的错误,原因是什么,怎么去恢复或者处理才是真正应该去做的。在接收消息出现故障的时候我们可以通过RabbitMQ重发机制来处理。重发就有重发次数的限制,有些时候你不可能不限次数的重发,这取决于消息的大小,重要程度和处理方式。
甚至QoS是在接收端设置的。发送端没有任何变化,接收端的代码也比较简单,只需要加如下代码:
代码第一个参数是可接收消息的大小的,但是似乎在客户端2.8.6版本中它必须为0,即使:不受限制。如果不输0,程序会在运行到这一行的时候报错,说还没有实现不为0的情况。第二个参数是处理消息最大的数量。举个例子,如果输入1,那如果接收一个消息,但是没有应答,则客户端不会收到下一个消息,消息只会在队列中阻塞。如果输入3,那么可以最多有3个消息不应答,如果到达了3个,则发送端发给这个接收方得消息只会在队列中,而接收方不会有接收到消息的事件产生。总结说,就是在下一次发送应答消息前,客户端可以收到的消息最大数量。第三个参数则设置了是不是针对整个Connection的,因为一个Connection可以有多个Channel,如果是false则说明只是针对于这个Channel的。
这种数量的设置,也为我们在多个客户端监控同一个queue的这种负载均衡环境下提供了更多的选择。
其他一些设置,了解下
后面有些基础不看了,直接要封装库了。
网上一些的封装RabbitMQ 的使用
简洁,参考博客1
运行单元测试的几个总结
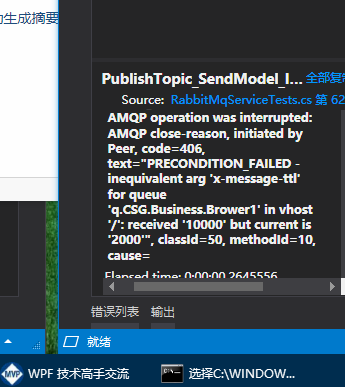
1 创建了一个队列,然后设置属性,由于不是过期,自动删除的,所以记录存在,然后我又单元测试,我修改了过期时间,但是还是那个队列名,所以属性对不上,所以报错了, 要不,删除那个队列,要不你把属性还原回去,要不然换个名字。