
如果 Old 区很小,上面的做法简单直接没有问题,但是如果 Old 区很大的情况,效率就非常低了。JVM 采用了一种叫 CardTable(卡表)的数据结构来解决这个问题。
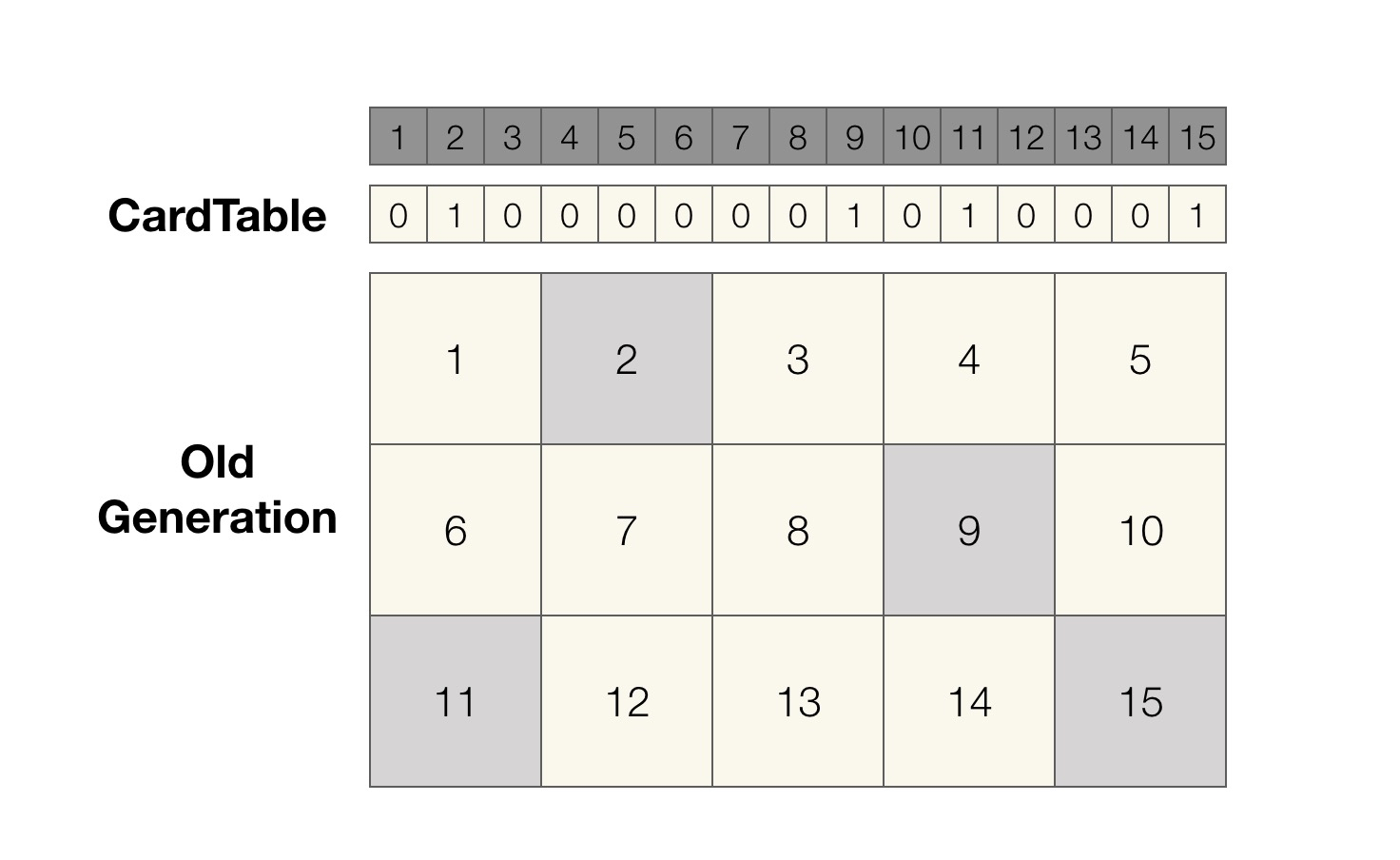
卡表就是一个 bit 数组,元素默认值为 0。从上图可以看出,Old 区被等分成了多个区域,每个区域对应卡表上的一个位置,如果某个区域中有对象引用了 Young 区的对象,则这个区域在卡表中对应的位置的值被设为 1。
YGC 时通过卡表的标志位就能让 GC 只扫描存在跨代引用的内存区域,从而避免了全 Old 区扫描。基于卡表的扫描流程可以从源码中看到:
void ClearNoncleanCardWrapper::do_MemRegion(MemRegion mr) { // ... // Old 区最后一个 Card 起始地址 jbyte* cur_entry = _ct->byte_for(mr.last()); // Old 区第一个 Card 起始地址 const jbyte* limit = _ct->byte_for(mr.start()); // Dirty Card 截止地址 HeapWord* end_of_non_clean = mr.end(); // Dirty Card 起始地址 HeapWord* start_of_non_clean = end_of_non_clean; while (cur_entry >= limit) { // 从后往前遍历 Card HeapWord* cur_hw = _ct->addr_for(cur_entry); // 如果当前 Card Dirty,先用 clear_card() 方法将其设置为 Clean if ((*cur_entry != CardTableRS::clean_card_val()) && clear_card(cur_entry)) { // 记录等会要清除的起始地址 start_of_non_clean = cur_hw; } else { // 如果遇到一个 Clean Card // 如果之前遇到过 DirtyCard,先清理掉再继续扫描 if (start_of_non_clean < end_of_non_clean) { const MemRegion mrd(start_of_non_clean, end_of_non_clean); _dirty_card_closure->do_MemRegion(mrd); } // ... end_of_non_clean = cur_hw; start_of_non_clean = cur_hw; } cur_entry--; } // 最终清理记录的 Dirty Card if (start_of_non_clean < end_of_non_clean) { const MemRegion mrd(start_of_non_clean, end_of_non_clean); _dirty_card_closure->do_MemRegion(mrd); } } -XX:+CMSClassUnloadingEnabled开启这个参数则每次触发 CMS GC 时都会顺带收集一次 Metaspace。当 Metaspace 达到空间使用阈值时会触发一次 FullGC,通过 CMS GC 经常清理 Metaspace,可以减小 Metaspace 触发 Full GC 的频率。
-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses开启这个参数,则每次由 System.gc() 触发的 FullGC 都转变为 CMS GC(前提是使用 CMS GC),并且要对 Metaspace 进行收集。
-XX:+UseCMSCompactAtFullCollection开启这个参数表示在 Full GC 后需要进行空间压缩,清除内存碎片,配合参数 -XX:CMSFullGCsBeforeCompaction 使用。后者指定多少次 Full GC 实际发生之后才进行一次压缩,默认是 0,表示每次 Full GC 后都要压缩。
清除内存碎片需要移动内存中的对象,所以只能单线程允许,这会让应用系统停顿时间更长。如果 Old 区足够大且内存足够零碎,那等待整理碎片的时间是不可接受的。如果不清理内存碎片,随着应用程序的长时间允许,最终会因为大量的内存碎片而没有足够空间分配对象,导致频繁 Full GC,最终 OOM。
一个生产可用的 CMS 配置参考服务器配置:Linux 64bit、8C16G、JDK8
-Xmx10880M -Xms10880M -Xmn4032M -XX:MaxMetaspaceSize=512M -XX:MetaspaceSize=512M -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:ErrorFile=http://www.likecs.com/home/admin/gclogs/hs_err_pid%p.log -Xloggc:/home/admin/gclogs/gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=http://www.likecs.com/home/admin/gclogs/heapdump -XX:+PrintGCApplicationStoppedTimeErrorFile 是 JVM Crash 日志;PrintGCApplicationStoppedTime 是打印 GC 过程中用户线程停顿时间,即 STW 的时长。将 Heap、Young、Metaspace 的初始和限制大小设置为一样可以避免扩容带来的 Full GC。
CMS 劣势
CPU 敏感
默认会使用 (CPU数 + 3)/ 4 条线程,如果服务器只有 2C,那么服务应用系统的能力直接减少一半。
内存碎片
默认不会清理碎片,长时间运行会导致严重碎片,引发频繁 Full GC,甚至 OOM。
CMF 导致 GC 退化
出现 CMS 时 GC 退化为 Serial Old,等待垃圾回收和内存清理,停顿时间变长。
如果程序运行过程中,98%的时间都在做垃圾回收,同时这些回收动作清理的堆内存空间不足总大小的 2%,则 CMS GC 会主动抛出 OOM。因为 CMS GC 会导致内存碎片,这个机制可以防止应用在小堆上长时间运行。因为大部分时间都在 GC,应用基本就等于失去了服务能力。
GC 日志GC 日志反映了 GC 的工作情况,读懂 GC 日志可以辅助我们定位内存问题,在 GC 日志中,我们主要关注 GC Cause、GC Flow 以及 GC 成果。以下面示例的 GC 日志为例:
示例程序Programmer.java
public class Programmer { private long id; private String name; private int age; private boolean male; }