
先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。
切分模式一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
不管怎么来说,数据切分虽然分散了单台服务器负载,但是带来了是设计和开发的复杂度。MyCat是一个开源的分布式数据库中间件,实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,在MyCat里,我们面向的是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
分库分表实践 基本环境操作系统:CentOS / 7.1 (64bit)
JDK:1.8
MySQL:5.7
MyCat:1.6
比如说我们现在有个实际的业务上设计需求,要将student和grade表进行垂直划分,分别存储不同的database中;还需要将student水平拆分,也要3个不同database存分别储。如下图所示,MyCat可以帮助实现这4个database的管理,而对于终端用户来说,就像只操作student和grade两张表,保证了中间件分库分页对程序员的透明性。
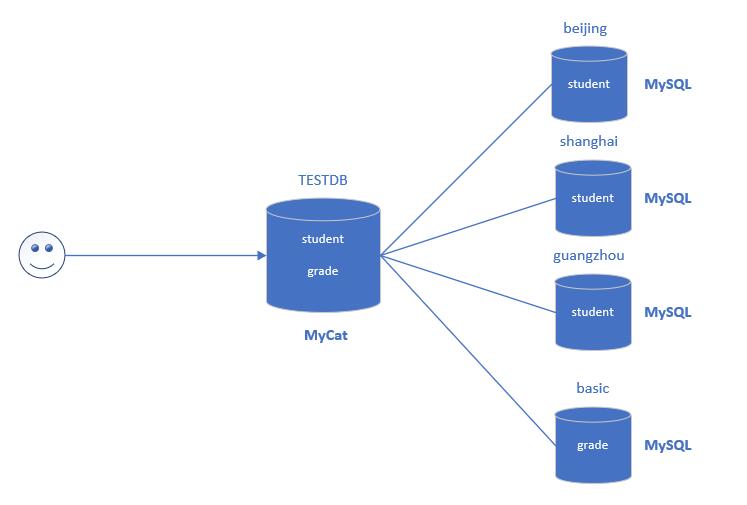
首先,我们肯定需要创建4个database:beijing、shanghai、guangzhou、basic,并生成对应的表。可以看出,student和grade表存在于不同的数据库,而且student表中的数据,分散存储在3个不同的数据库中:
create database beijing; use beijing; create table student( id int primary key, name varchar(8) not null, grade int not null ); create database shanghai; use shanghai; create table student( id int primary key, name varchar(8) not null, grade int not null ); create database guangzhou; use guangzhou; create table student( id int primary key, name varchar(8) not null, grade int not null ); create database basic; use basic; create table grade( id int primary key, name varchar(8) not null );