
Java 版本的ZAB协议的实现跟上面的定义略有不同,选举阶段使用的是 Fast Leader Election(FLE),它包含了步骤2的发现职责。因为FLE会选举拥有最新提议的历史节点作为 Leader,这样就省去了发现最新提议的步骤。
实际的实现将 发现和同步阶段合并为 Recovery Phase(恢复阶段) ,所以,Zab 的实现实际上有三个阶段。
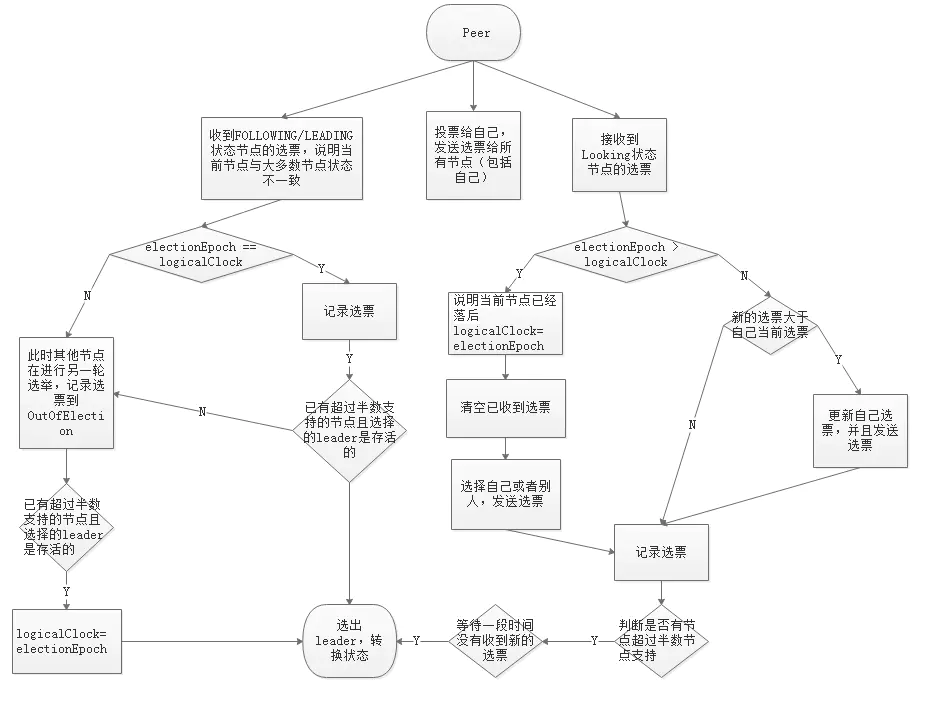
快速选举(Fast Leader Election)前面提到的 FLE 会选举拥有最新Proposal history (lastZxid最大)的节点作为 Leader,这样就省去了发现最新提议的步骤。 这是基于拥有最新提议的节点也拥有最新的提交记录
成为Leader的条件:
选epoch最大的
epoch相等,选zxid最大的
epoch和zxid都相等,选server_id最大的(zoo.cfg 中配置的 myid)
节点在选举开始时,都默认投票给自己,当接收其他节点的选票时,会根据上面的 Leader条件 判断并且更改自己的选票,然后重新发送选票给其他节点。当有一个节点的得票超过半数,该节点会设置自己的状态为 Leading ,其他节点会设置自己的状态为 Following。
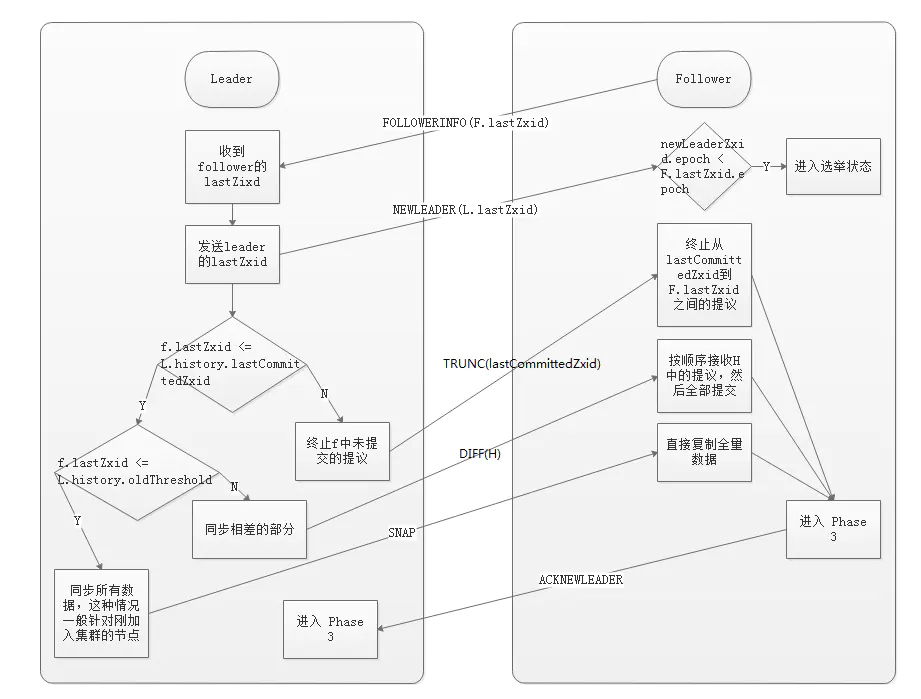
这一阶段 Follower 发送他们的 lastZxid 给 Leader,Leader 根据 lastZxid 决定如何同步数据。这里的实现跟前面的 阶段 3 有所不同:Follower 收到 TRUNC 指令会终止 L.lastCommitedZxid 之后的 Proposal ,收到 DIFF 指令会接收新的 Proposal。
history.lastCommittedZxid:最近被提交的提议的 zxid
history.oldThreshold:被认为已经太旧的已提交提议的 zxid
参考 4.1 [ZAB协议内容#消息广播]
ZAB与Paxos的联系和区别 联系都存在一个类似Leader进程的角色,由其负责协调多个Follower进程的运行
Leader进程都会等待超过半数的Follower作出正确的反馈后,才会将一个提议进行提交(过半原则)
在ZAB中,每个Proposal中都包含了一个epoch值,用来代表当前Leader周期,在Paxos中同样存在这样的一个表示,名字为 Ballot。
区别Paxos算法中,新选举产生的主进程会进行两个阶段的工作;第一阶段称为读阶段:新的主进程和其他进程通信来收集主进程提出的提议,并将它们提交。第二阶段称为写阶段:当前主进程开始提出自己的提议。
ZAB协议在Paxos基础上添加了同步阶段,此时,新的Leader会确保存在过半的Follower已经提交了之前Leader周期中的所有事物Proposal。这一同步阶段的引入,能够有效保证,Leader在新的周期中提出事务Proposal之前,所有的进程都已经完成了对之前所有事务Proposal的提交。
总的来说,ZAB协议和Paxos算法的本质区别在于两者的设计目的不一样:ZAB协议主要用于构建一个高可用的分布式数据主备系统,而Paxos算法则用于构建一个分布式的一致性状态机系统。
总结问题解答:
主从架构下,leader 崩溃,数据一致性怎么保证?
leader 崩溃之后,集群会选出新的 leader,然后就会进入恢复阶段,新的 leader 具有所有已经提交的提议,因此它会保证让 followers 同步已提交的提议,丢弃未提交的提议(以 leader 的记录为准),这就保证了整个集群的数据一致性。
选举 leader 的时候,整个集群无法处理写请求的,如何快速进行 leader 选举?
这是通过 Fast Leader Election 实现的,leader 的选举只需要超过半数的节点投票即可,这样不需要等待所有节点的选票,能够尽早选出 leader。