
DRS通过全量迁移将客户数据库中的存量数据迁移到GaussDB(for openGauss)中,通过增量同步,实时解析源库日志,将客户的实时变化数据同步到Gauss(for openGauss),通过全量和增量的无缝衔接来保证客户在不中断业务的情况下,完整地将全部数据迁移到GaussDB(for openGauss)。
预校验
在DRS的迁移任务启动之前,为提早发现迁移启动后可能存在的风险或错误,DRS引入预校验环节,能够提前对配置信息、数据库兼容性信息、连通性信息等进行校验,同时会对一些可以迁移成功但可能会对业务产生影响的情况进行告警,让客户及时发现并提前处理。
断点机制
为保证数据迁移的一致性,DRS在每个组件中都设有断点机制,无论是在正常启停、异常重启还是在故障切换的场景下都可以保证数据同步的准确性,不会造成数据丢失。
4.DRS技术实现原理DRS在技术实现上主要分为两个大的模块,一个是全量的数据同步,另一个是增量数据同步。全量同步解决对静态数据的迁移,增量同步解决对实时的变化数据迁移。
全量同步的技术架构全量同步的整体逻辑比较简单,就是从源库把数据通过select的方式查询出来,然后再将这些数据写入到目标库,只是在具体的代码实现上会有一些关键技术点。
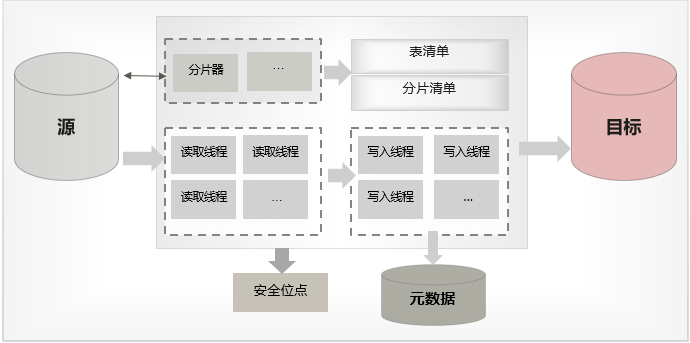
数据分片
一般全量同步产品的同步粒度都可以达到表级别的并发,即多个线程可以同时对多张表同时进行同步,但往往客户的系统中会存在单表数据量特别大的情况,比如一张表几十亿甚至上百亿的数据,此时这张表的同步时间就变为整个全量同步的时间。那么如何进一步提升单张表的同步效率呢?我们可以对单表做进一步的拆分,按照主键去把它拆分成多个分片,多线程以分片为单位做并行的同步。
当前DRS按照下面的策略对表进行分片:
无主键表不进行分片
分区表按分区进行同步,不再对每个分区进行分片
有主键表按主键(第一列)进行分片
数据不落盘
为减少全量同步过程中对磁盘的占用,DRS导出的数据不进行落盘缓存,而是直接通过内存传递给导入线程,在导出和导入速率相当的情况下,可以最大化的提高全量同步的效率。
断点控制
全量同步半途中断是一个非常让人棘手的问题,可能一张2亿条数据的表,在同步到1.8亿的时候因为网络或源库快照过旧的问题导致同步失败,如果没有好的断点控制机制,那可能之前的付出都白白浪费,还要重新再次同步一次。DRS通过以分片为单位做为断点的保存记录,对于上面的例子,即使同步中断,也可以再次被拉起,而且拉起后,已经同步成功的分片将不再同步,还没有同步的分片则会继续同步。
流量控制
客户的业务往往是存在高峰期和低峰期,高峰期时,数据库的资源占用是最高的,我们要尽量避开在业务高峰期做全量的同步,因为全量同步对源库的cpu、内存和网络资源占用是很大的。DRS采用流量控制的机制来减少业务高峰期对源库的资源占用,主要是通过控制网络流量的方式,客户可以设置要进行流量控制的时间段,DRS在全量同步过程中,会实时计算同步的流量大小,运行到该时段后,当流量超过设置的阈值,会放缓数据获取的速度。运行过该时段后,便恢复全部的数据同步速度。
全量+增量的无缝衔接
在业务切库的场景中,数据的迁移过程一般可以选择两种方案,一种是一次性将源库的数据迁移到目标库,但是需要业务停机窗口,这个窗口的大小取决于全量数据迁移的时间。当数据量较大时,整个迁移过程可能需要几天的时间,这种业务停机是无法接受的。所以另一种方案就是业务不中断的数据迁移方案,它的实现原理就是基于全量迁移和增量同步的无缝衔接,对于Oracle->GaussDB(for openGauss)的迁移,Oracle数据库提供了指定scn进行快照导出的功能,基于这个特性,DRS在做全量同步时,指定scn进行导出,这样整个全量同步的数据就是此scn点前的快照数据,然后增量同步以这个scn点作为同步的分界点,只有大于这个scn的增量事务才会被同步到目标库。这样就实现了全量和增量的无缝衔接,同步过程无需业务进行停机,当全量数据同步完成且增量同步追赶到当前时间点时,便可进行业务切换,业务中断窗口可以控制在秒级。
增量同步的技术架构DRS的增量同步架构主要分为3个部分,分别是数据抓取、落盘文件和数据回放。