HashMap中不允许存在相同的 key 的,那怎么保证 key 的唯一性呢,判断的代码如下。
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))首先通过 hash 算法算出的值必须相等,算出的结果是 int,所以可以用 == 符号判断。只是这个条件可不行,要知道哈希碰撞是什么意思,有可能两个不一样的 key 最后产生的 hash 值是相同的。
并且待插入的 key == 当前索引已存在的 key,或者 待插入的 key.equals(当前索引已存在的key),注意== 和 equals 是或的关系。== 符号意味着这是同一个对象, equals 用来确定两个对象内容相同。
如果 key 是基本数据类型,比如 int,那相同的值肯定是相等的,并且产生的 hashCode 也是一致的。
String 类型算是最常用的 key 类型了,我们都知道相同的字符串产生的 hashCode 也是一样的,并且字符串可以用 equals 判断相等。
但是如果用引用类型当做 key 呢,比如我定义了一个 MoonKey 作为 key 值类型
public class MoonKey { private String keyTile; public String getKeyTile() { return keyTile; } public void setKeyTile(String keyTile) { this.keyTile = keyTile; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; MoonKey moonKey = (MoonKey) o; return Objects.equals(keyTile, moonKey.keyTile); } }然后用下面的代码进行两次添加,你说 size 的长度是 1 还是 2 呢?
Map<MoonKey, String> m = new HashMap<>(); MoonKey moonKey = new MoonKey(); moonKey.setKeyTile("1"); MoonKey moonKey1 = new MoonKey(); moonKey1.setKeyTile("1"); m.put(moonKey, "1"); m.put(moonKey1, "2"); System.out.println(hash(moonKey)); System.out.println(hash(moonKey1)); System.out.println(m.size());答案是 2 ,为什么呢,因为 MoonKey 没有重写 hashCode 方法,导致 moonkey 和 moonKey1 的 hash 值不可能一样,当不重写 hashCode 方法时,默认继承自 Object的 hashCode 方法,而每个 Object对象的 hash 值都是独一无二的。
划重点,正确的做法应该是加上 hashCode的重写。
@Override public int hashCode() { return Objects.hash(keyTile); }这也是为什么要求重写 equals 方法的同时,也必须重写 hashCode方法的原因之一。 如果两个对象通过调用equals方法是相等的,那么这两个对象调用hashCode方法必须返回相同的整数。有了这个基础才能保证 HashMap或者HashSet的 key 唯一。
发生哈希碰撞怎么办前面刚说了相等的对象产生的 hashCode 也要相等,但是不相等的对象使用 hash方法计算之后也有可能产生相同的值,这就叫做哈希碰撞。虽然通过算法已经很大程度上避免碰撞的发生,但是却无法避免。
产生碰撞之后,自然得出的在 table 数组的索引(也就是桶)也是一样的,这时,怎么办呢,一个桶里怎么放多个键值对?
拉链法
文章刚开头就提到了,HashMap可不是简单的数组而已。当碰撞发生就坦然接收。有一种方法叫做拉链法,不是衣服上那种拉链。而是,当碰撞发生了,就在当前桶上拉一条链表出来,这样解释就合理了。
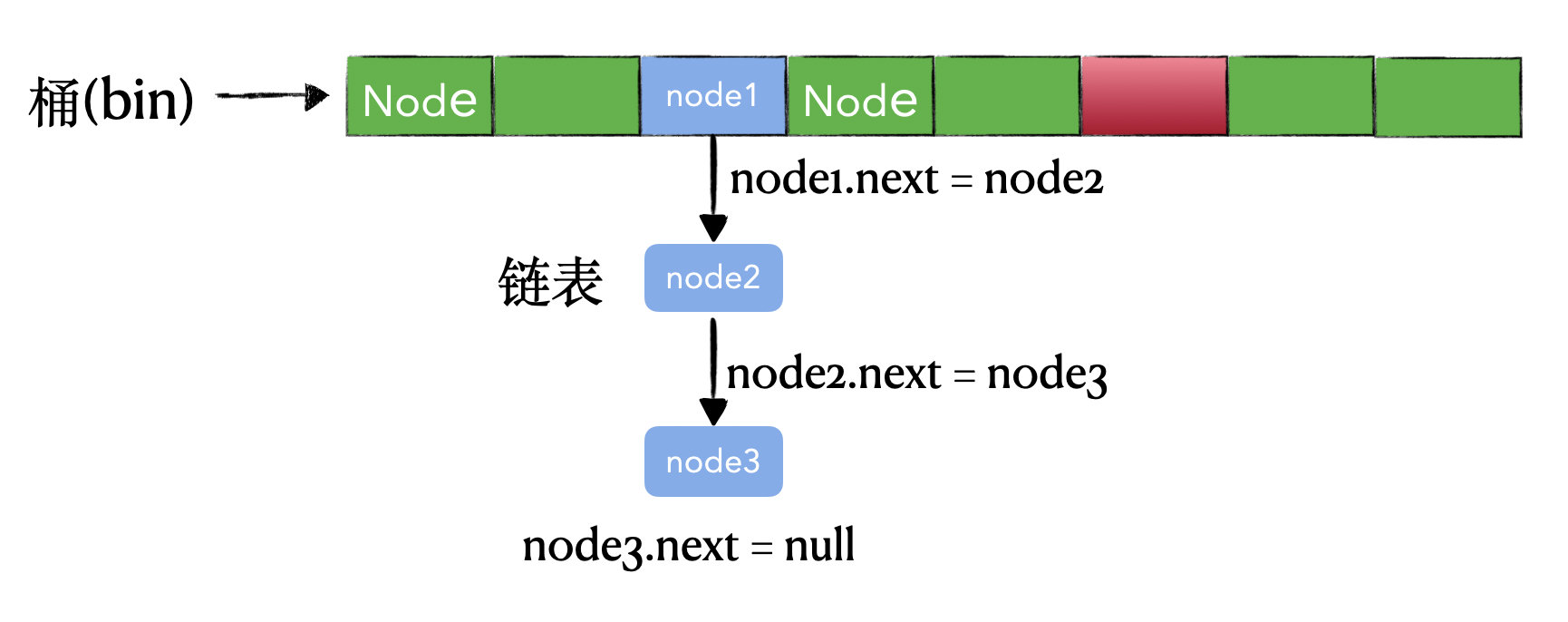
前面介绍关键概念的时候提到了 Node类型,里面有个属性叫做 next,它就是为了这种链表设计的,如下图所示。node1、node2、node3都落在了同一个桶中,这时候就得用链表的方式处理了,node1.next = node2,node2.next = node3,这样将链表串起来。而 node3.next = null,则说明这是链表的尾巴。
当有新元素准备插入到链表的时候,采用的是尾插法,而不是头插法了,JDK 1.7 的版本采用的是头插法,但是头插法有个问题,就是在两个线程执行 resize() 扩容的时候,很可能造成环形链表,导致 get 方法出现死循环。
链表转换成树
链表不是碰撞处理的终极结构,终极结构是红黑树,当链表长度到达 8 之后,再有新元素进来,那就要开始由链表到红黑树的转换了。方法 treeifyBin是完成这个过程的。
使用红黑树是出于性能方面的考虑,红黑树的查找速度要优于链表。那为什么不是一开始就直接生成红黑树,而是链表长度大于 8 之后才升级成树呢?
首先来说,哈希碰撞的概率还是很小的,大部分情况下都是一个桶装一个 Node,即便发生碰撞,都碰撞到一个桶的概率那就更是少之又少了,所以链表长度很少有机会能到 8 ,如果链表长度到 8 了,那说明当前 HashMap中的元素数量已经非常大了,那这时候用红黑树来提高性能是可取的。而反过来,如果 HashMap总的元素很少,即便用红黑树对性能的提升也不大,况且红黑树对空间的使用要比链表大很多。
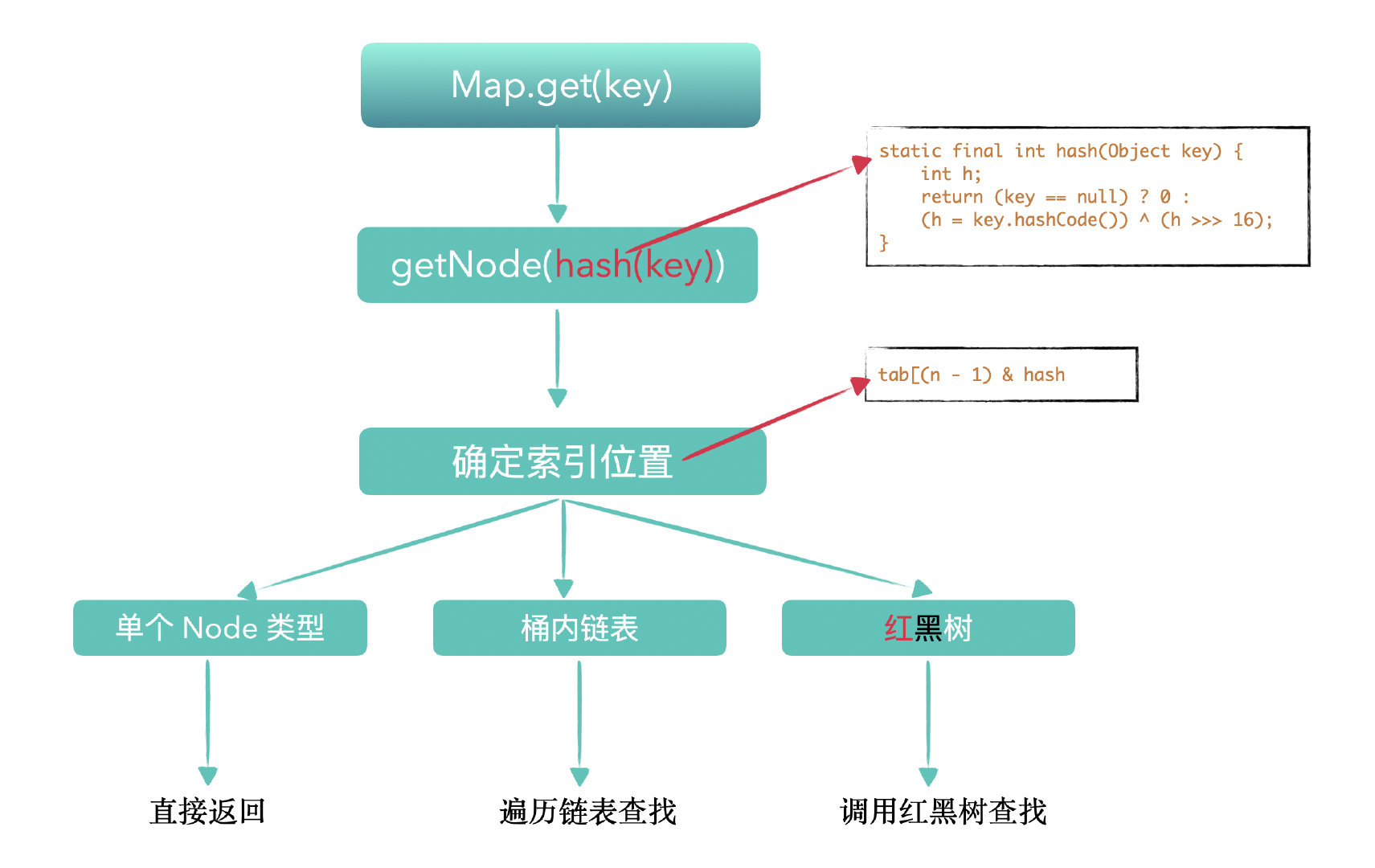
get 方法 T value = map.get(key);例如通过上面的语句通过 key 获取 value 值,是我们最常用到的方法了。