
看图理解,当调用 get方法后,第一步还是要确定索引位置,也就是我们所说的桶的位置,方法和 put方法时一样,都是先使用 hash这个 扰动函数 确定 hash 值,然后用 (n-1) & hash获取索引。这不废话吗,当然得和 put的时候一样了,不一样还怎么找到正确的位置。
确定桶的位置后,会出现三种情况:
单节点类型: 也就是这个桶内只有一个键值对,这也在 HashMap中存在最多的类型,只要不发生哈希碰撞都是这种类型。其实 HashMap最理想的情况就是这样,全都是这种类型就完美了。
链表类型: 如果发现 get 的 key 所在的是一个链表结构,就需要遍历链表,知道找到 key 相等的 Node。
红黑树类型: 当链表长度超过 8 就转变成红黑树,如果发现找到的桶是一颗红黑树,就使用红黑树专有的快速查找法查找。
另外,Map.containsKey方法其实用的就是 get方法。
remove 方法remove与put、get方法类似,都是先求出 key 的 hash 值,然后 (n-1) & hash获取索引位置,之后根据节点的类型采取不同的措施。
单节点类型: 直接将当前桶元素替换为被删除 node.next ,其实就是 null。
链表类型: 如果是链表类型,就将被删除 node 的前一个节点的 next 属性设置为 node.next。
红黑树类型: 如果是一棵红黑树,就调用红黑树节点删除法,这里,如果节点数在 2~6之间,就将树结构简化为链表结构。
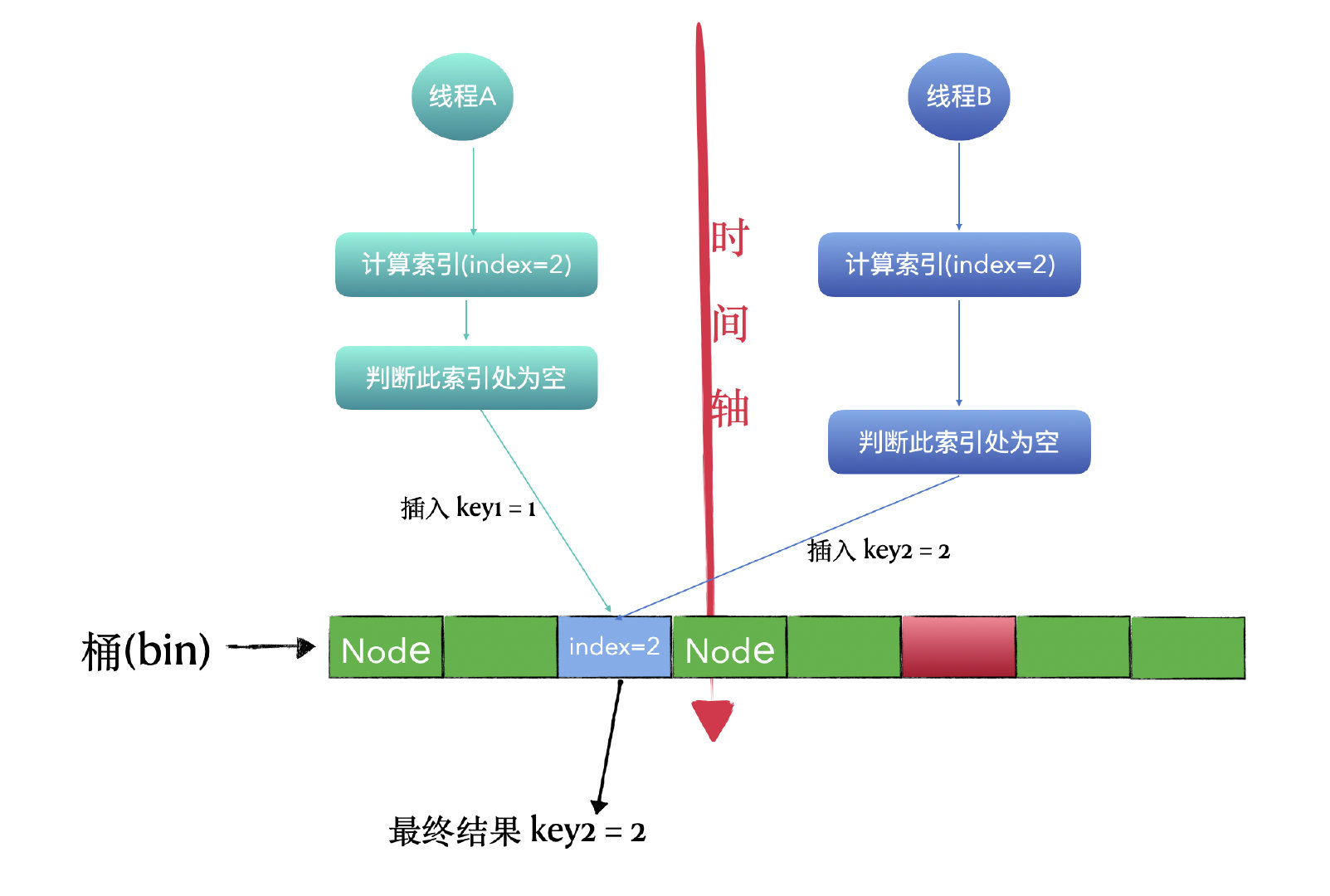
非线程安全HashMap没有做并发控制,如果想在多线程高并发环境下使用,请用 ConcurrentHashMap。同一时刻如果有多个线程同时执行 put 操作,如果计算出来的索引(桶)位置是相同的,那会造成前一个 key 被后一个 key 覆盖。
比如下图线程 A 和 线程 B 同时执行 put 操作,很巧的是计算出的索引都是 2,而此时,线程A 和 线程B都判断出索引为 2 的桶是空的,然后就是插入值了,线程A先 put 进去了 key1 = 1的键值对,但是,紧接着线程B 又 put 进去了 key2 = 2,线程A 表示痛哭流涕,白忙活一场。最后索引为2的桶内的值是 key2=2,也就是线程A的存进去的值被覆盖了。
前面没说,HashMap搞的这么复杂不是白搞的,它的最大优点就是快,尤其是 get数据,是 O(1)级别的,直接定位索引位置。
HashMap不是单纯的数组结构,当发生哈希碰撞时,会采用拉链法生成链表,当链表大于 8 的时候会转换成红黑树,红黑树可以很大程度上提高性能。
HashMap容量必须是 2 的 n 次方,这样设计是为了保证寻找索引的散列计算更加均匀,计算索引的公式为 (n - 1) & hash。
HashMap在键值对数量达到扩容阈值「容量 x 负载因子」的时候进行扩容,每次扩容为之前的两倍。扩容的过程中会对单节点类型元素进行重新计算索引位置,如果是红黑树节点则使用 split方法重新考量,是否将红黑树变为链表。
壮士且慢,先给点个赞吧,总是被白嫖,身体吃不消!
我是风筝,公众号「古时的风筝」。一个兼具深度与广度的程序员鼓励师,一个本打算写诗却写起了代码的田园码农!你可选择现在就关注我,或者看看历史文章再关注也不迟。