
这是设计模式系列文章的第三篇
之前两篇的阅读效果不是很好,我一度怀疑这种题材的文章不受大家欢迎,直到前两天我面试了一个小姐姐...
面试过程中和小姐姐聊起她在上家公司做过的项目,其中有一个功能,根据小姐姐的描述,我第一感觉应该用生成器模式来实现
小姐姐说她并没有用生成器模式,就是简单的硬编码
我问她为什么不使用生成器模式实现的时候,小姐姐的一句话突破了我的认知下线
小姐姐说:我不知道什么是生成器模式,我不打算做架构师,没必要学设计模式
原来她认为设计模式只有在做架构设计的时候才会用到,跟普通程序员没有关系
我觉得小姐姐的观点存在严重问题,设计模式是程序员的基本技能,每个程序员都应该掌握并灵活应用
良好的代码设计不仅可以让代码重复性更高,还能使代码更易读从而降低代码后期的维护成本,最重要的是可以提高系统的可靠性
今天,我们就使用生成器模式来实现小姐姐的需求
实际案例我们先来看一下这个小姐姐的项目的具体需求
根据用户近期的消费金额、消费次数、浏览商品类型、商品价格区间等一些属性,生成用户画像。根据画像分析用户行为,实现精准营销或刺激消费等。
当然,不同的业务关注的角度也不同。比如精准营销业务关注的是用户近半年的数据,而且以消费数据为主;刺激消费业务关注的是用户近一个月的数据,而且以常打开的商品为主
从编程角度把需求提炼一下,大概就是以下两点:
提供一个用户对象,这个对象包括用户名、消费金额、消费次数、浏览商品类型、商品价格区间等属性
根据这个对象进行一些业务处理
我们先来看一下小姐姐当初是怎么实现这个需求的
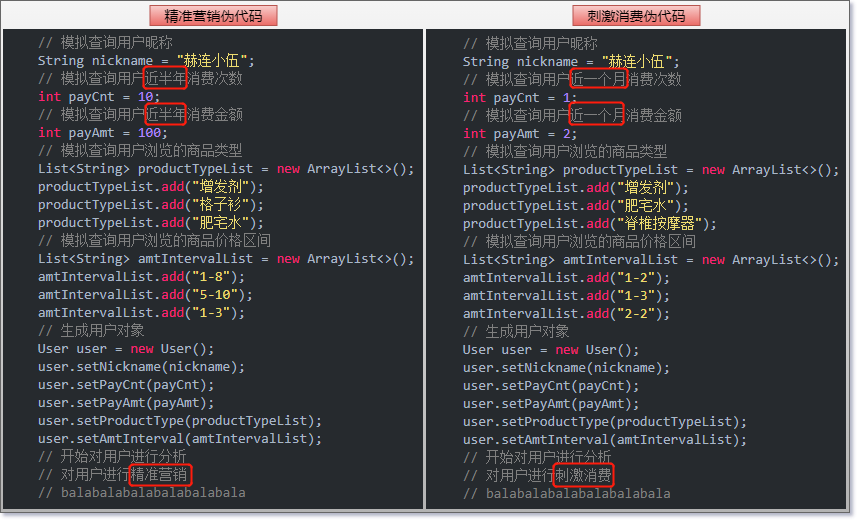
小姐姐的代码是在精准营销和刺激消费的业务逻辑里面,分别创建了一个User对象。
两个业务中创建User对象的逻辑基本一样,只有在获取近期消费数据时稍有差别。一个是获取近半年的数据,另一个是获取近一个月的数据
这样的硬编码是把User对象的创建过程,嵌入到了其他业务逻辑里面,这就造成一些问题
问题一:代码重用性降低
User对象的创建逻辑基本一样,但是写了两遍。如果后期加入新的业务,User对象的创建逻辑还要再写一遍,代码重用性太低
问题二:维护成本增大
示例中的伪代码模拟的比较简单,实际上User对象的创建过程非常复杂,需要查询各种数据并且对数据进行过滤、分类、整理,代码可能有几百行
精准营销或刺激消费的业务逻辑也是非常复杂的,把两块复杂的逻辑写到一块,后期阅读或维护代码的成本将几何倍的增长
问题三:代码耦合度增加
将两块业务逻辑写到一起,其中不免会共享一些逻辑。
如果后期想对共享的逻辑进行修改,让其仅对其中一方生效,代码的修改是很不友好的,很容易造成另一方的逻辑漏洞
我们可以尝试使用生成器模式来解决这些问题
生成器模式 生成器模式定义生成器模式是将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示
换成大白话理解就是:一个复杂的对象,它的创建过程和使用过程要分开。对于对象的使用者来说,我只需要告诉创建者我需要使用这个复杂对象,至于这个复杂对象是怎么创建的,不关我事 (ps:有点渣男的味道)
生成器模式使用场景在创建一个对象时,同时满足以下条件,可以使用生成器模式
对象的创建过程非常复杂
对象的创建步骤固定
不同的调用者获得的对象不完全相同
如果需要创建的对象不复杂,这时候是没必要使用生成器模式的。因为生成器模式本身的代码实现有一点复杂,使用它成本有点高,还不如简单的硬编码
如果对象的创建步骤不固定,也不推荐使用生成器模式。
假如在小姐姐的项目中,如果精准营销需要用户的消费数据,不需要浏览商品数据;刺激消费需要用户的浏览商品数据,不需要消费数据。

User对象的创建步骤就是