
摘要:根据设定的哈希函数 H(key) 和所选中的处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集 (区间) 上,并以关键字在地址集中的“象”作为相应记录在表中的存储位置,如此构造所得的查找表称之为“哈希表”。
本文分享自华为云社区《查找——HASH》,原文作者:ruochen。
对于频繁使用的查找表,希望 ASL = 0
记录在表中位置和其关键字之间存在一种确定的关系
根据设定的哈希函数 H(key) 和所选中的处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集 (区间) 上,并以关键字在地址集中的“象”作为相应记录在表中的存储位置,如此构造所得的查找表称之为“哈希表”
HASH函数的构造构造原则
函数本身便于计算
计算出来的地址分布均匀,即对任一关键字k,f(k) 对应不同地址的概率相等,目的是尽可能减少冲突
直接定址法哈希函数为关键字的线性函数
H(key) = key
H(key) = a * key + b
此法仅适合于:
地址集合的大小 = = 关键字集合的大小
优点:以关键码key的某个线性函数值为哈希地址,不会产生冲突
缺点:要占用连续地址空间,空间效率低
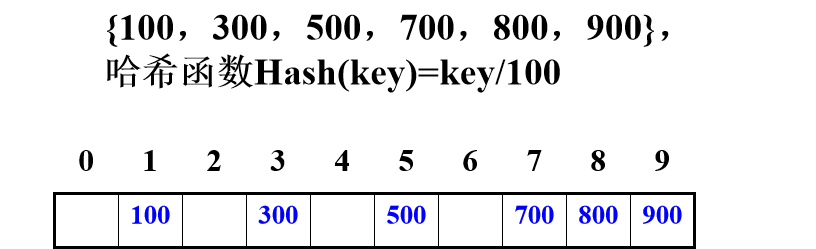
假设关键字集合中的每个关键字都是由 s 位数字组成 (u1, u2, …, us),分析关键字集中的全体, 并从中提取分布均匀的若干位或它们的组合作为地址
此方法仅适合于:
能预先估计出全体关键字的每一位上各种数字出现的频度
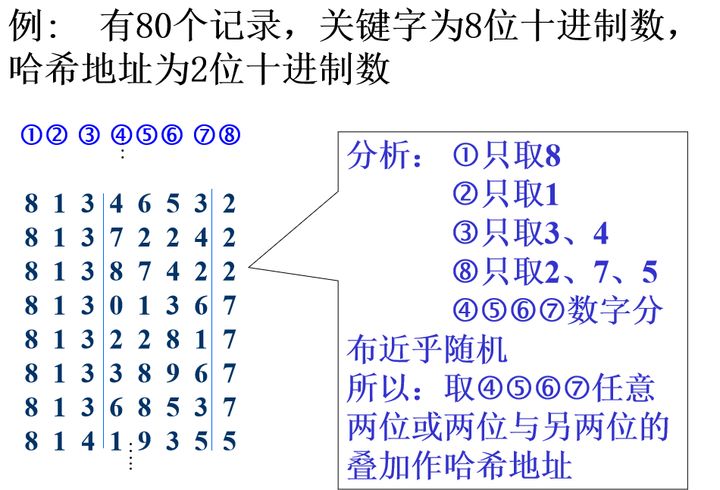
以关键字的平方值的中间几位作为存储地址。求“关键字的平方值” 的目的是“扩大差别” ,同时平方值的中间各位又能受到整个关键字中各位的影响
此方法适合于:
关键字中的每一位都有某些数字重复出现频度很高的现象
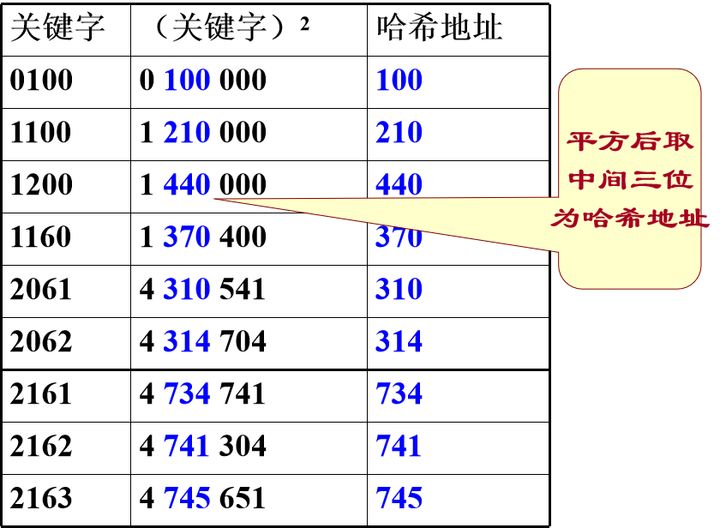
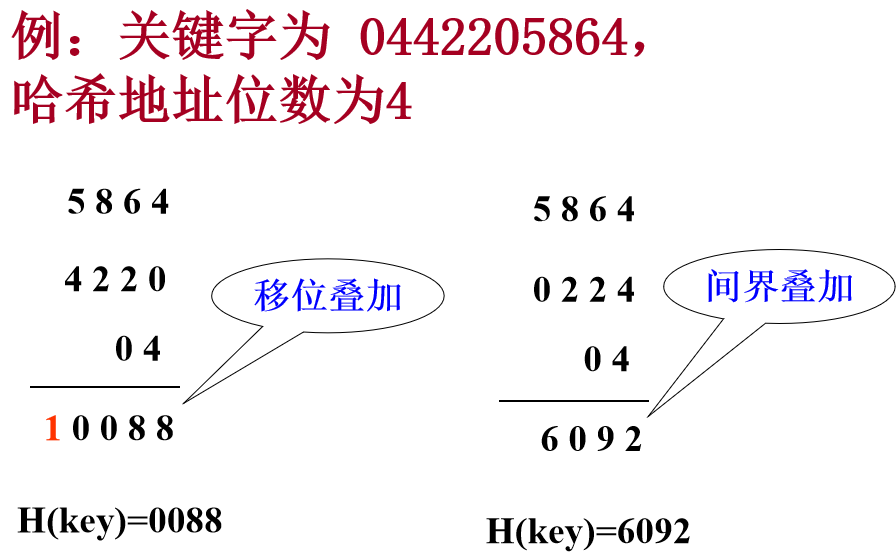
将关键字分割成若干部分,然后取它们的叠加和为哈希地址。有两种叠加处理的方法:移位叠加和间界叠加
此方法适合于:
关键字的数字位数特别多
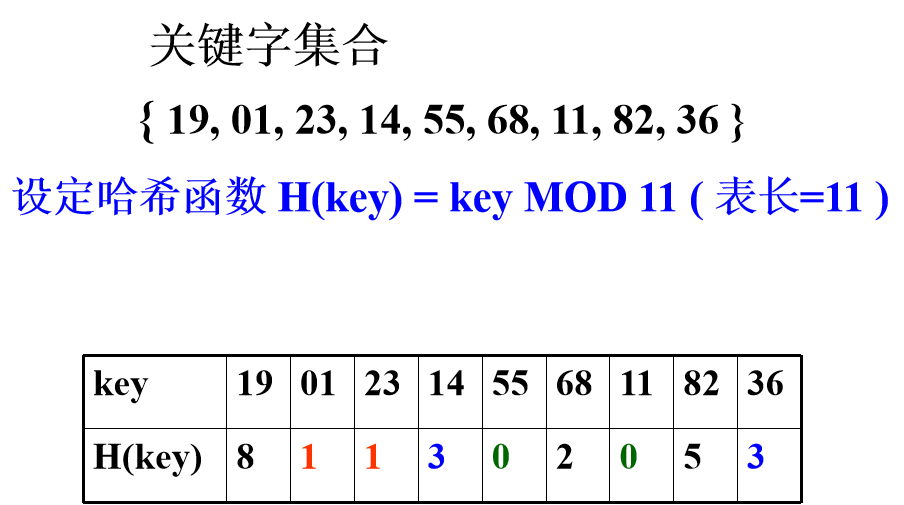
Hash(key)=key mod p (p是一个整数)
p≤m (表长)
p 应为小于等于 m 的最大素数
为什么要对 p 加限制?
给定一组关键字为: 12, 39, 18, 24, 33, 21若取 p=9, 则他们对应的哈希函数值将为:
3, 3, 0, 6, 6, 3
可见,若 p 中含质因子 3, 则所有含质因子 3 的关键字均映射到“3 的倍数”的地址上,从而增加了“冲突”的可能
H(key) = Random(key) (Random 为伪随机函数)
此方法用于对长度不等的关键字构造哈希函数
考虑因素
执行速度(即计算哈希函数所需时间)
关键字的长度
哈希表的大小
关键字的分布情况
查找频率
采用何种构造哈希函数的方法取决于建表的关键字集合的情况
原则是使产生冲突的可能性降到尽可能地小
有冲突时就去寻找下一个空的哈希地址,只要哈希表足够大,空的哈希地址总能找到,并将数据元素存入
线性探测法Hi=(Hash(key)+di) mod m ( 1≤i < m )
其中:m为哈希表长度
di 为增量序列 1,2,…m-1,且di=i
一旦冲突,就找下一个空地址存入