
开局一张图,前面已经从每一部分解析过JVM的内存结构了,现在按照顺序来分析:
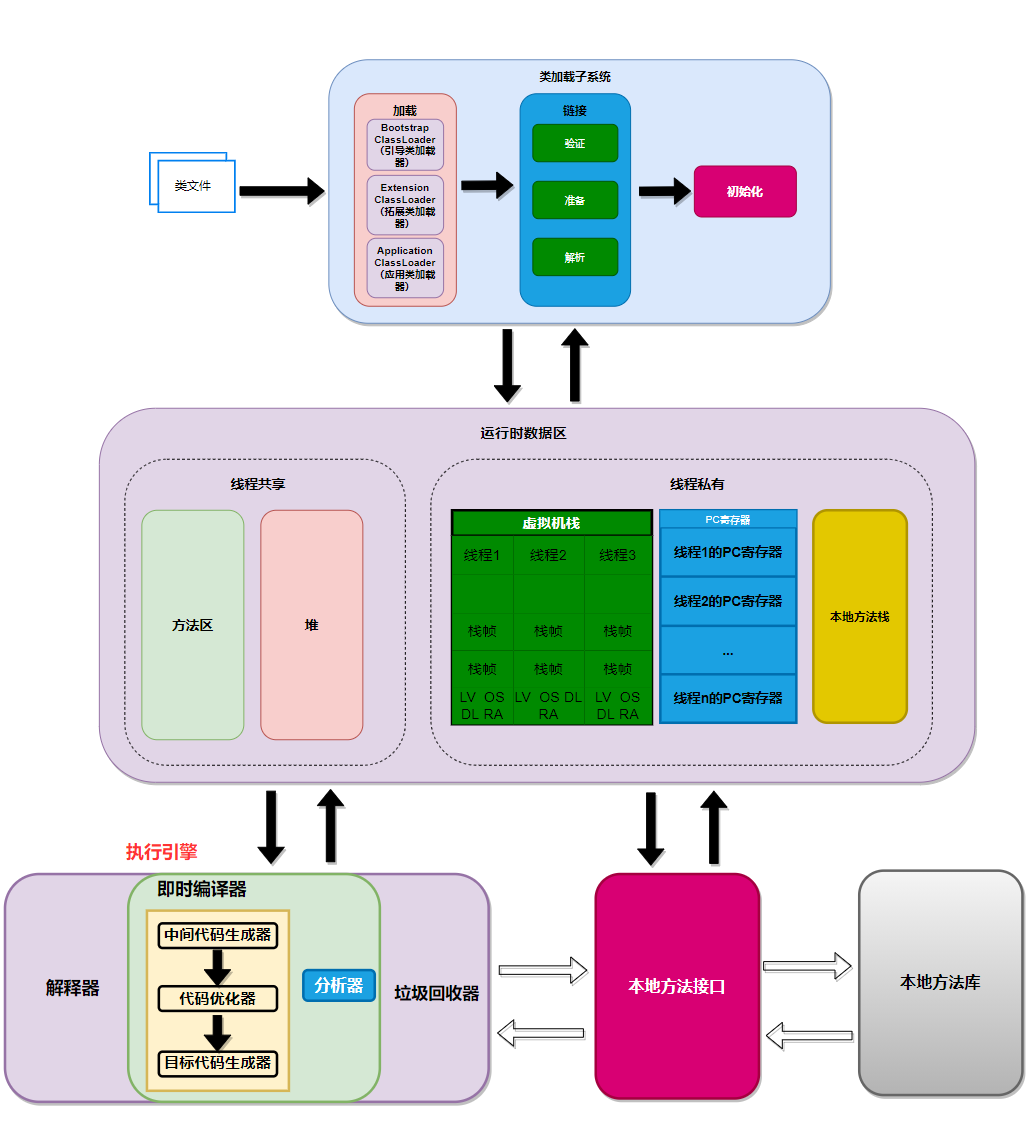
整体上来看:类文件从类加载子系统,加载完成之后,主要存放在方法区(JRockit和H9没有方法区,这里指的是HotSpot)。运行时的数据主要是存放在运行时数据区,代码的解释编译优化以及垃圾收集,都是在执行引擎中。本地方法是指Native方法,也就是C/C++编写的方法。
类加载子系统类文件首先需要经过类加载子系统,进行加载,进类信息等加载到运行时数据区。
在类加载子系统中有以下三个阶段操作:
加载
链接
初始化
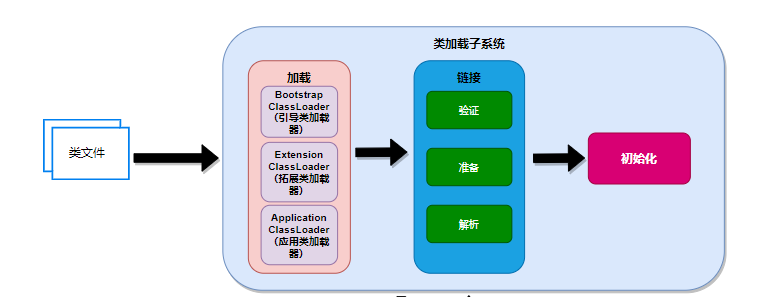
其中加载的时候,有三种类加载器:
Bootstrap ClassLoader:引导类加载器,主要加载JDK里面的核心类
Extension ClassLoader:拓展类加载器
Application ClassLoader:应用加载器
而链接也分为3个阶段,主要是:
验证
链接
解析
运行时数据区经过类加载子系统加载之后,进入运行时数据区,运行时区域主要分为:
线程私有:
程序计数器:Program Count Register,线程私有,没有垃圾回收
虚拟机栈:VM Stack,线程私有,没有垃圾回收
本地方法栈:Native Method Stack,线程私有,没有垃圾回收
线程共享:
方法区:Method Area,以HotSpot为例,JDK1.8后元空间取代方法区,有垃圾回收。
堆:Heap,垃圾回收最重要的地方。
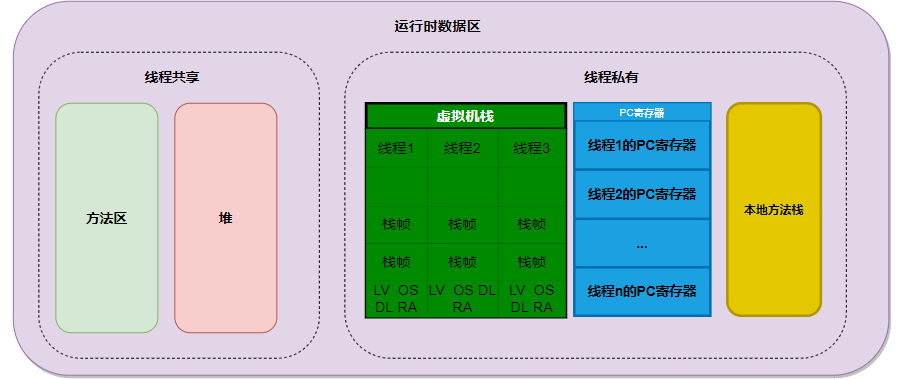
虚拟机栈,每一个线程有一份,每一个线程的虚拟机栈里面,存放的是一个个栈帧,每一个栈帧表示一个方法调用。
PC寄存器,同样是每一个线程有一份,不同线程之间执行到何处,互不干扰。
执行引擎执行引擎里面可以逐行解释执行,也可以编译成机器指令直接执行,主要包括:
解释器
即时编译器:即时编译器中包括了中间代码生成器,代码优化器,目标代码生成器等。
垃圾收集器
解释器,需要逐行解释执行,效率低下。譬如:如果循环两千次,循环体很大,每次执行都需要解释执行。
JIT 编译器,除了可以直接全部即时编译,还可以统计出那些代码执行频率比较高,这部分代码就是热点代码,这种技术叫做热点代码探测技术,JIT 编译器会将热点代码,提前编译成为机器指令,放在方法区缓存起来,下次执行到的时候,不需要解释执行,而是直接运行机器指令。
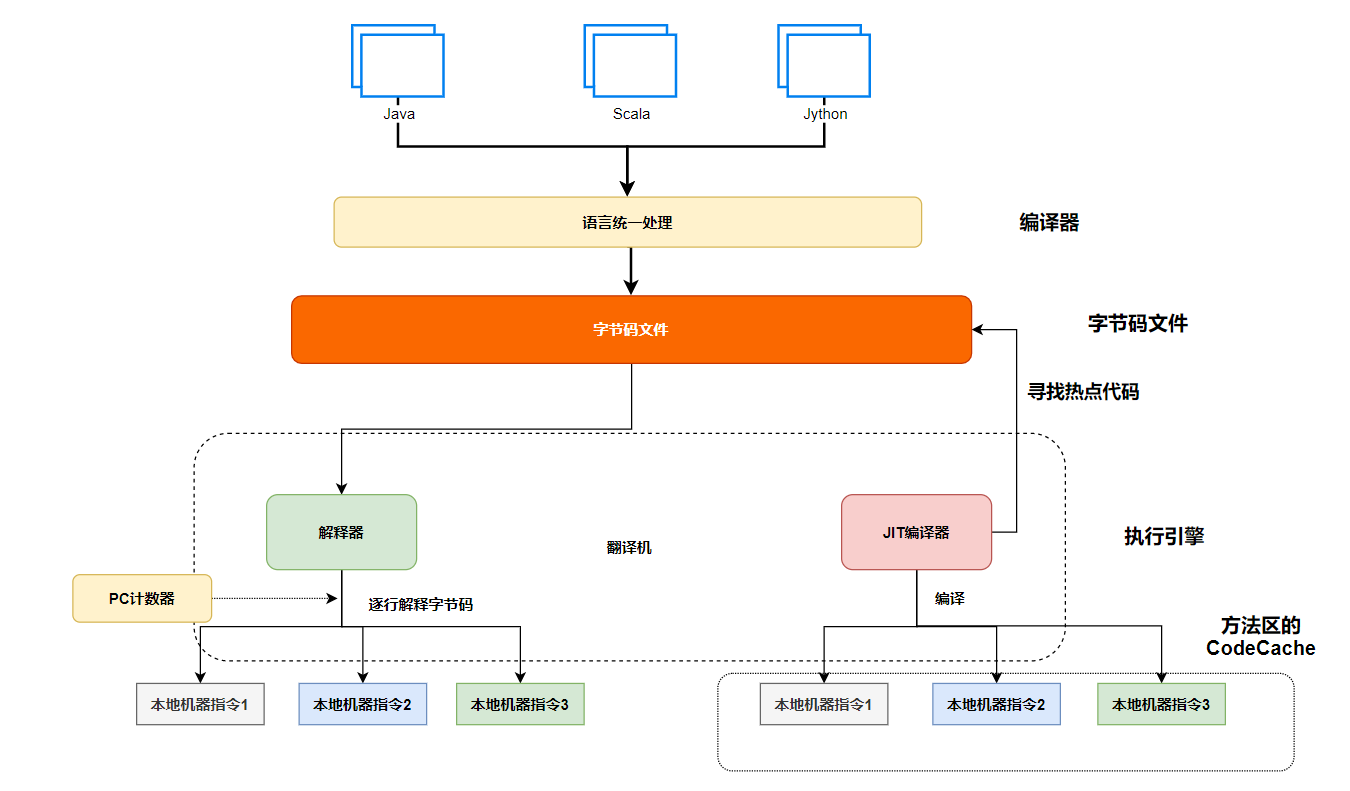
即时编译器的执行效率很高,为什么不将它全部提前编译好缓存起来呢?
全部提前编译,首次启动响应速度慢,会有卡顿的感觉,因为编译需要大量时间。(主要原因)
缓存代码,需要放在方法区,占用内存空间,容易溢出。
翻译成为机器指令,则这部分缓存的 CodeCache 是不能够直接跨平台,因为不同环境的机器指令是不大一样的,只能每次运行前就全部编译。
如果需要写一个虚拟机,那么需要考虑的重要两部分是:类加载子系统和执行引擎。类加载子系统负责将类信息按照规定,加载到运行时数据区,而执行引擎主要负责对代码解释执行或者编译成二进制缓存起来,进行执行。
【作者简介】:
秦怀,公众号【秦怀杂货店】作者,技术之路不在一时,山高水长,纵使缓慢,驰而不息。个人写作方向:Java源码解析,JDBC,Mybatis,Spring,redis,分布式,剑指Offer,LeetCode等,认真写好每一篇文章,不喜欢标题党,不喜欢花里胡哨,大多写系列文章,不能保证我写的都完全正确,但是我保证所写的均经过实践或者查找资料。遗漏或者错误之处,还望指正。
2020年我写了什么?