
博客:
Blob作用据Caffe官方描述:
A Blob is a wrapper over the actual data being processed and passed along by Caffe, and also under the hood provides synchronization capability between the CPU and the GPU. Mathematically, a blob is an N-dimensional array stored in a C-contiguous fashion.
Caffe stores and communicates data using blobs. Blobs provide a unified memory interface holding data; e.g., batches of images, model parameters, and derivatives for optimization.
Blobs conceal the computational and mental overhead of mixed CPU/GPU operation by synchronizing from the CPU host to the GPU device as needed. Memory on the host and device is allocated on demand (lazily) for efficient memory usage.
Blob是Caffe中的基础数据结构,主要作用如下:
存储和传输数据,对外提供统一的内存接口。在Caffe中,输入图像、每层的权重和反向传播时的梯度、每层的输入和输出等都以Blob形式管理
隐藏CPU和GPU之间数据同步的细节(通过SyncedMemory实现),用户使用时不需要自己管理CPU和GPU间的数据同步
在逻辑上,Blob是个\(N_d\)维张量。当\(N_d=4\)时,Blob的shape定义为\(N * C * H * W\),即\(Num * Channel * Height * Width\),可以表示输入图像Batch、卷积层的kernel参数、卷积层的输入输出map等;当\(N_d=2\)时,可以表示全连接层的权重,\(N_{out} * N_{in}\);当\(N_d=1\)时,可以表示卷积层和全连接层的bias参数。
具体地,
\(N_d=4\),Blob表示输入图像时,\(N\)为当前批次的图片数量即MiniBatchNum,\(C\)为图像的通道数,RGB图\(C=3\),\(H\)和\(W\)为图像的高和宽。
\(N_d=4\),Blob表示卷积层的输入输出时,\(N=1\),\(C\)为特征图的数量,\(H\)和\(W\)为特征图的高和宽。
\(N_d=4\),Blob表示卷积层kernel参数时,\(N\)为当前层输出特征图的数量,其与卷积核数量相同,\(C\)为当前层输入特征图的数量,其与一个卷积核的层数相同,\(H\)和\(W\)为卷积核的高和宽,每个卷积是三维的即\(C*H*W\)。
\(N_d=2\),Blob表示全连接层的权重时,shape为\(N_{out} * N_{in}\)的二维矩阵,\(N_{out}\)为输出数量,\(N_{in}\)为输入数量。
\(N_d=1\),Blob为长度为\(N\)的向量,表示卷积层bias参数时,\(N\)为卷积核数量(与输出特征图数量相同),表示全连接层bias参数时,\(N\)为输出数量(与上面的\(N_{out}\)相同)。
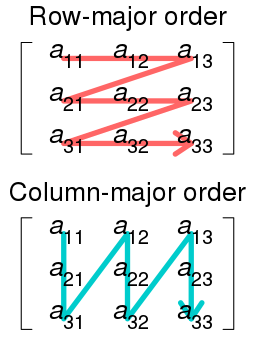
主要成员变量 shared_ptr<SyncedMemory> data_; // 数据,存储图像、参数、输入输出等 shared_ptr<SyncedMemory> diff_; // 反向传播时的梯度,训练阶段update时参数的更新量 shared_ptr<SyncedMemory> shape_data_; // GPU shape,与下面的shape是相同的 vector<int> shape_; // shape,data和diff相同 int count_; // 张量中的元素数量,比如 N*C*H*W int capacity_; // 容量,当前分配内存的大小,当reshape时,可能需要扩容 Blob存储结构Blob的data_和diff_对应的数据区,在内存中均以行有先的方式存储(C语言风格)。行优先和列优先的存储方式如下图所示,9个数连续存储,表示同一个矩阵,但是存储顺序不同,图片来自WIKI:
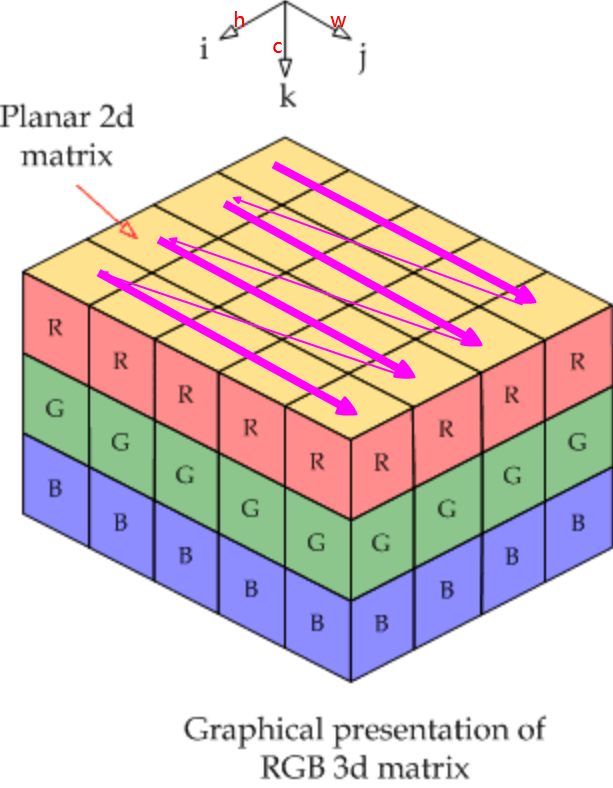
当输入图像为1张RGB图时,shape为\(1*3*4*5\),其存储顺序如下图所示,图片素材来自链接。channel维上,0为R,1为G、2为B,先在R上行有先存储,再在G上行有先存储,最后在B上行有先存储。这里仅作示意,在caffe中实际存储顺序为BGR。
当\(N=4\)时,\(Num * Channel * Height * Width\),Blob在\(Width\)维上连续存储,如下图所示:
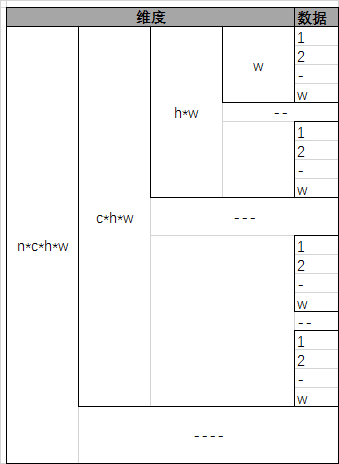
理解了上图,再理解多维Blob的拼接、裁剪等操作就很容易了。
通过Blob的offset成员函数可以获得\((n, c, h, w)\)处的偏移量,偏移的计算方式与行优先存储是一致的,代码如下:
inline int offset(const int n, const int c = 0, const int h = 0, const int w = 0) const { CHECK_GE(n, 0); CHECK_LE(n, num()); CHECK_GE(channels(), 0); CHECK_LE(c, channels()); CHECK_GE(height(), 0); CHECK_LE(h, height()); CHECK_GE(width(), 0); CHECK_LE(w, width()); return ((n * channels() + c) * height() + h) * width() + w; } CPU与GPU间的数据传递 const Dtype* cpu_data() const; // 不可修改数据,return (const Dtype*)data_->cpu_data(); const Dtype* gpu_data() const; // return (const Dtype*)data_->gpu_data(); Dtype* mutable_cpu_data(); // 可修改数据,return static_cast<Dtype*>(data_->mutable_cpu_data()); Dtype* mutable_gpu_data(); // static_cast<Dtype*>(data_->mutable_gpu_data());