
分区数可以设置成 6、12 等数值。比如 6,当消费者只有一个时,这 6 个分区都归这个消费者,后面再加入一个消费者时,每个消费者都负责 3 个分区,后面又加入一个消费者时,每个消费者就负责 2 个分区。每个消费者分配到的分区数是一样的,可以均匀地消费。
副本
主题的副本数即数据备份的个数,如果副本数为 1 , 即使 Kafka 机器有多个,当该副本所在的机器宕机后,对应的数据将访问失败。
集群模式下创建主题时,如果分区数和副本数都大于 1,主题会将分区 Leader 较均匀的分配在有副本的 Kafka 上。这样客户端在消费这个主题时,可以从多台机器上的 Kafka 消息数据,实现分布式消费。
副本数不是越多越好,从节点需要从主节点拉取数据同步,一般设置成和 Kafka 机器数一样即可。如果只需要用到高可用的话,可以采用 N+1 策略,副本数设置为 2,专门弄一台 Kafka 来备份数据。然后主题分布存储在 "N" 台 Kafka 上,"+1" 台 Kafka 保存着完整的主题数据,作为备用服务。
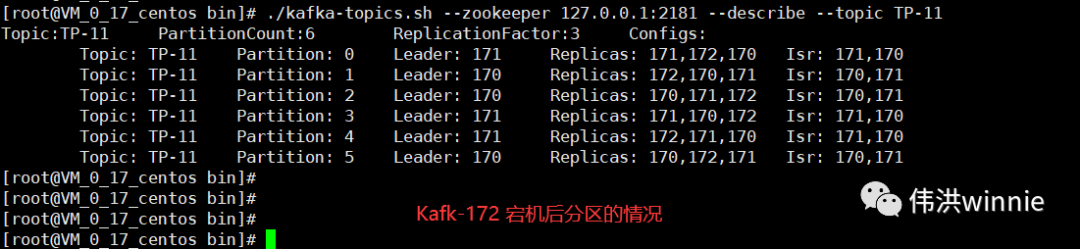
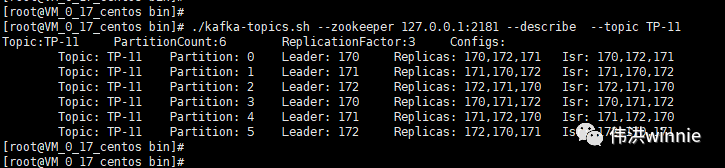
Replicas 表示在哪些 Kafka 机器上有主题的副本,Isr 表示当前有副本的 Kafka 机器上还存活着的 Kafka 机器。主题分区中所涉及的 Leader Kafka 宕机时,会将宕机 Kafka 涉及的分区分配到其它可用的 Kafka 节点上。如下:
消费组
每一个消费组记录者各个主题分区的消费偏移量,在消费的时候,如果没有指定消费组,会默认创建一个临时消费组。生产者生产的消息只能被同一消费组下某个消费者消费。如果想要一条消息可以被多个消费者消费,可以加入不同的消费组。
偏移量最大值,消息存储策略
偏移量的最大值
long 类型最大值是(2^63)-1 (为什么要减一呢?第一位是符号位,正的有262,负的有262,其中+0 和 -0 是相等的 , 只不过有的语言把0算到负里面,有的语言把0算到正里面)。 偏移量是一个 long 类型,除去负数,包含0,其最大值为 2^62。
消息存储策略
Kafka 配置项提供两种策略, 一种是基于时间:log.retention.hours=168,另一种是基于大小:log.retention.bytes=1073741824 。符合条件的数据会被标记为待删除,Kafka会在恰当的时候才真正删除。
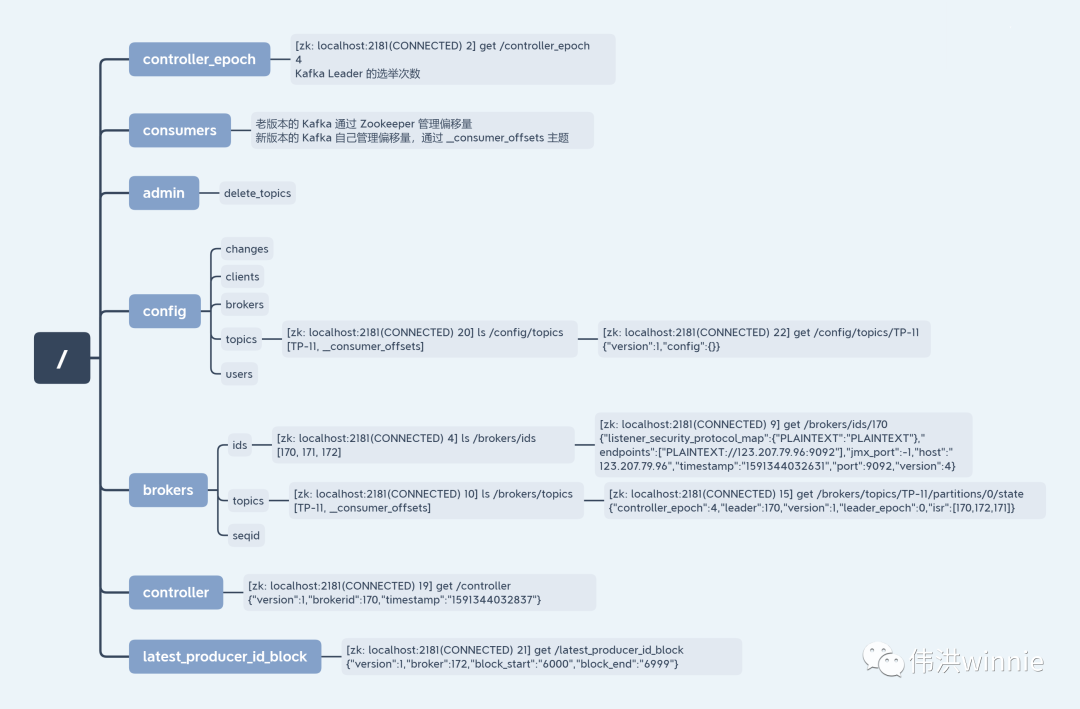
Zookeeper 上存的 Kafka 相关数据
如何确保消息只被消费一次
前面已经讲到,同一主题里的分区数据,只能被相同消费组里其中一个消费者消费。当有多个消费者同时消费同一主题时,将这些消费者都加入相同的消费组,这时生产者的消息只能被其中一个消费者消费。
重复消费和数据丢失问题
生产者
生产者发送消息成功后,不等 Kafka 同步完成的确认,继续发送下一条消息。在发的过程中如果 Leader Kafka 宕机了,但生产者并不知情,发出去的信息 Kafka 就收不到,导致数据丢失。解决方案是将 Request.Required.Acks 设置为 -1,表示生产者等所有副本都确认收到后才发送下一条消息。
Request.Required.Acks=0 表示发送消息即完成发送,不等待确认(可靠性低,延迟小,最容易丢失消息)
Request.Required.Acks=1 表示当 Leader 提交同步完成后才发送下一条消息
消费者
消费者有两种情况,一种是消费的时候自动提交偏移量导致数据丢失:拿到消息的同时偏移量加一,如果业务处理失败,下一次消费的时候偏移量已经加一了,上一个偏移量的数据丢失了。
另一种是手动提交偏移量导致重复消费:等业务处理成功后再手动提交偏移量,有可能出现业务处理成功,偏移量提交失败,那下一次消费又是同一条消息。
怎么解决呢?这是一个 or 的问题,偏移量要么自动提交要么手动提交,对应的问题是要么数据丢失要么重复消费。如果消息要求实时性高,丢个一两条没关系的话可以选择自动提交偏移量。如果消息一条都不能丢的话可以选择手动提交偏移量,然后将业务设计成幂等,不管这条消息消费多少次最终和消费一次的结果一样。
Linux Kafka 操作命令
查看 Kafka 中 Topic
查看 Kafka 详情
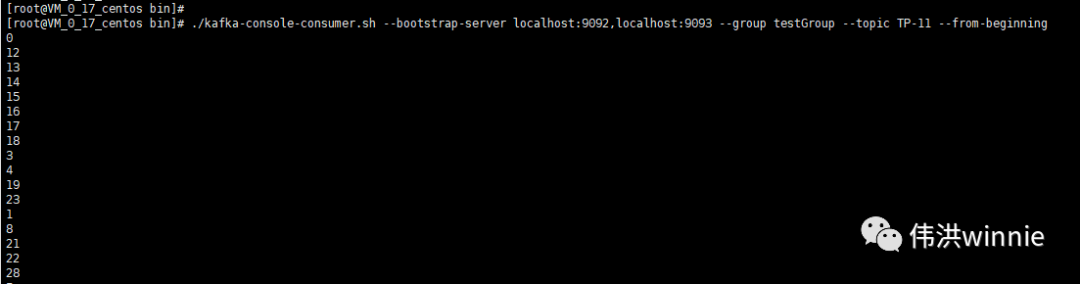
消费 Topic
查看所有消费组

查看消费组的消费情况

Windows 可视化工具 Kafka Tool
配置 Hosts 文件
123.207.79.96 ZooKeeper-Kafka-01配置 Kafka Tool 连接信息