

为什么需要消息队列
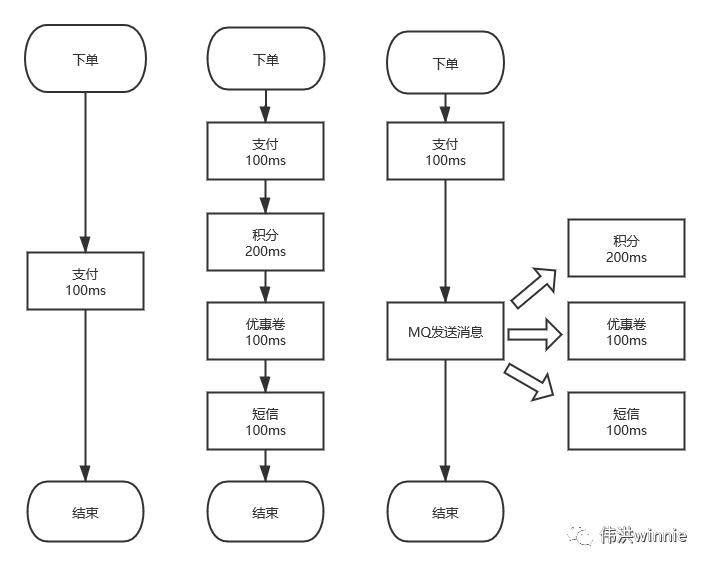
1.异步 :一个下单流程,你需要扣积分,扣优惠卷,发短信等,有些耗时又不需要立即处理的事,可以丢到队列里异步处理。
2.削峰 :按平常的流量,服务器刚好可以正常负载。偶尔推出一个优惠活动时,请求量极速上升。由于服务器 Redis,MySQL 承受能力不一样,如果请求全部接收,服务器负载不了会导致宕机。加机器嘛,需要去调整配置,活动结束后用不到了,即麻烦又浪费。这时可以将请求放到队列里,按照服务器的能力去消费。
3.解耦 :一个订单流程,需要扣积分,优惠券,发短信等调用多个接口,出现问题时不好排查。像发短信有很多地方需要用到, 如果哪天修改了短信接口参数,用到的地方都得修改。这时可以将要发送的内容放到队列里,起一个服务去消费, 统一发送短信。
高吞吐、高可用 MQ 对比分析
看了几个招聘网站,提到较多的消息队列有:RabbitMQ、RocketMQ、Kafka 以及 Redis 的消息队列和发布订阅模式。
Redis 队列是用 List 数据结构模拟的,指定一端 Push,另一端 Pop,一条消息只能被一个程序所消费。如果要一对多消费的,可以用 Redis 的发布订阅模式。Redis 发布订阅是实时消费的,服务端不会保存生产的消息,也不会记录客户端消费到哪一条。在消费的时候如果客户端宕机了,消息就会丢失。这时就需要用到高级的消息队列,如 RocketMQ、Kafka 等。
ZeroMQ 只有点对点模式和 Redis 发布订阅模式差不多,如果不是对性能要求极高,我会用其它队列代替,毕竟关解决开发环境所需的依赖库就够折腾的。
RabbitMQ 多语言支持比较完善,特性的支持也比较齐全,但是吞吐量相对小些,而且基于 Erlang 语言开发,不利于二次开发和维护。
RocketMQ 和 Kafka 性能差不多,基于 Topic 的订阅模式。RocketMQ 支持分布式事务,但在集群下主从不能自动切换,导致了一些小问题。RocketMQ 使用的集群是 Master-Slave ,在 Master 没有宕机时,Slave 作为灾备,空闲着机器。而 Kafka 采用的是 Leader-Slave 无状态集群,每台服务器既是 Master 也是 Slave。

Kafka 相关概念
在高可用环境中,Kafka 需要部署多台,避免 Kafka 宕机后,服务无法访问。Kafka集群中每一台 Kafka 机器就是一个 Broker。Kafka 主题名称和 Leader 的选举等操作需要依赖 ZooKeeper。
同样地,为了避免 ZooKeeper 宕机导致服务无法访问,ZooKeeper 也需要部署多台。生产者的数据是写入到 Kafka 的 Leader 节点,Follower 节点的 Kafka 从 Leader 中拉取数据同步。在写数据时,需要指定一个 Topic,也就是消息的类型。
一个主题下可以有多个分区,数据存储在分区下。一个主题下也可以有多个副本,每一个副本都是这个主题的完整数据备份。Producer 生产消息,Consumer 消费消息。在没给 Consumer 指定 Consumer Group 时会创建一个临时消费组。Producer 生产的消息只能被同一个 Consumer Group 中的一个 Consumer 消费。
Broker:Kafka 集群中的每一个 Kafka 实例
Zookeeper:选举 Leader 节点和存储相关数据
Leader:生产者与消费者只跟 Leader Kafka 交互
Follower:Follower 从 Leader 中同步数据
Topic:主题,相当于发布的消息所属类别
Producer:消息的生产者
Consumer:消息的消费者
Partition:分区
Replica:副本
Consumer Group:消费组
分区、副本、消费组
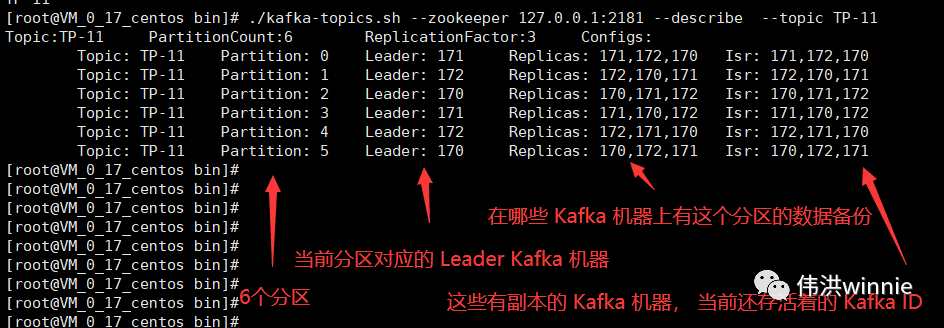
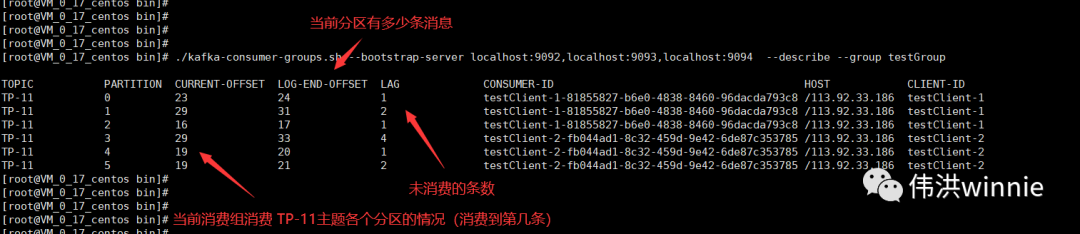
分区
主题的数据会按分区数分散存到分区下,把这些分区数据加起来才是一个主题的完整的数据。分区数最好是副本数的整数倍,这样每个副本分配到的分区数比较均匀。同一个分区写入是有顺序的,如果要保证全局有序,可以只设置一个分区。
如果分区数小于消费者数,前面的消费者会配到一个分区,后面超过分区数的消费者将无分区可消费,除非前面的消费者宕机了。如果分区数大于消费者数,每个消费者至少分配到一个分区的数据,一些分配到两个分区。这时如果有新的消费者加入,会把有两个分区的调一个分配到新的消费者。