
单机时代,传统软件大多是单体/巨石架构(Monolithic)。大家往一个代码仓库提交CODE,这会导致应用膨胀,难以理解和修改,以及扩展受限,无法按需伸缩等诸多问题。单体架构怎么解决多人合作的问题?模块化,对,按功能拆分,模块之间定义编程接口(API),彼此关心功能而不关心实现。
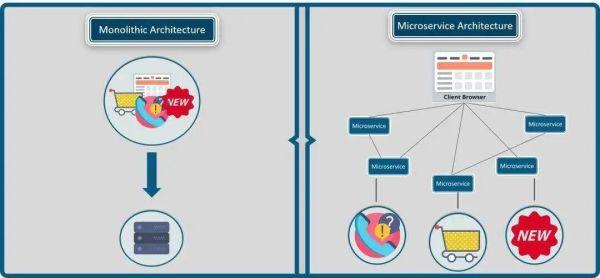
随着时代发展,单机程序遇到了计算力和存储的双重瓶颈,分布式架构应运而生。单体应用通过函数名(标识)便可轻松完成本地函数调用,在分布式系统中,服务(RPC/RESTful API)承担了类似的角色,但请求服务单靠服务名还不够,服务名只是服务能力(服务类型)的标识,还需要指示服务位于网络何处,而部署在云中的服务实例IP是动态分配的,扩缩容、失败和更新则让问题变得更加复杂,静态配置服务实例适应不了新变化,需要更精细化的服务治理能力,为了解决或者说简化这个问题,服务发现作为一种基础能力被抽象和提供,它试图让请求网络服务像调用本地函数一样简单透明。
服务即功能(函数)。只是服务跟网络紧密联系在一起,所有才会出现网络服务这个名词,服务提供者通过网络发布服务,服务使用者通过网络请求服务,分布式系统突破了单机算力和存储的限制,提升了系统稳定性,使得高并发高可用的海量服务成为可能,但这也增加了软件复杂度,引入软件分层、负载均衡、微服务、服务发现/治理、分布式一致性等新的问题和挑战。
服务发现服务分服务提供者(Service Provider)和服务消费者(Service Consumer),如果要提供海量服务能力,单一的服务实例显然是不够的,如果要提供成千上万种服务,则需要有一个地方记录服务名到服务实例列表的映射,所以,有必要引入一个新的角色:服务中介,服务中介维护一个服务注册表(Service Registry),可以把注册表理解为服务字典,key是服务名,value是服务提供实例列表;服务注册表是联系服务提供者和服务消费者的桥梁,它维护服务提供者的最新网络位置等信息,也是服务发现最核心的部分。
服务启动的时候,把服务信息注册(put)到服务注册表;服务终止的时候,从服务注册表删除(remove)自身的服务信息。
服务消费者在请求服务的时候,先去服务注册表按名查询(get)服务提供者列表,然后从列表里挑选一个服务实例,向该实例请求服务。
大道至简,这便是最简单的服务发现模型,也是服务发现的基本原理,至此,似乎一切都OK,但其实尚有几个问题没有说清楚。
问题和解法 第一个问题服务如果不是正常停止,而是被系统kill掉,它便没有机会通知服务注册表把自身服务信息删除,这样注册表便多了一条指向无效服务实例的信息,而服务消费者却并不知情,怎么办?解决的办法很简单:保活(keepalive),服务提供者定期(比如每隔10秒)给服务中介发送keepalive消息,服务中介收到keepalive消息后更新该服务实例的keepalive timestamp,服务中介定期检查该timestamp,如果超期便把该服务实例从注册表剔除。
第二个问题服务实例列表变化如何通知服务消费者?不外乎两种方法,轮询和pub-sub。轮询是消费者主动询问服务中介服务列表是否变化,如果有变化,则把新的服务列表发送给消费者。如果消费者过多,则服务中介处理轮询的消息会有压力,在服务类别很多,服务列表很大的时候,它甚至会成为瓶颈。pub-sub是服务中介主动通知服务消费者,时效性相比轮询更好,缺点是会占用单独的线程或者连接资源。
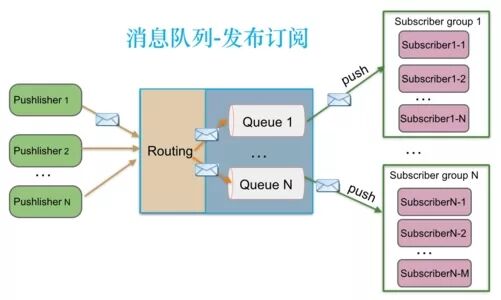
服务中介如果挂了怎么办?所以我们要解决单点的问题,通常会用集群来对抗这种脆弱性,有很多用于做服务注册表的开源解决方案,比如etcd/zookeeper/consul,本质上使用分布式一致性数据库来保存注册表信息,它既解决读写性能问题又提高了系统稳定性可用性。
第四个问题