是这么一回事:
我正在苦思一个业务逻辑,捋着我还剩不多的秀发,一时陷入冥想中......
突然聊天图标一顿猛闪,打开一看,有同事语音;
大概意思是:同事把项目中Redis部分缓存换成MemoryCache/Memcached,还强调MemoryCache/Memcached的效率是Redis的2~5倍;
当时我想到的是Memcached,听到的似乎也是,心想:怎么可能,就算有性能差,也不至于那么多;
因为当时同事代码还没提交,然后就陷入讨论ing,最后还是没聊通,我就跑到同事那当面沟通(要去打架吗,不不不,文明人);
沟通中.....,好几分钟过去了,突然同事说:他用的是微软的MemoryCache;
虽然从读音上我还没区分出来,但一听微软,我就感觉我成笑话啦;
然后赶紧让同事打开代码,我擦,真成笑话啦,还理直气壮的沟通了好几十分钟。
为什么会那么“理直气壮”?
对Memcached(听错的)性能高于Redis的2~5倍产生重大怀疑,经验告诉我不可能,除非Redis用法有问题;
同事把Redis换成Memcached(听错的),那肯定不行的,前期的技术选型,Memcached不太符合项目应用场景;
最后因为MemoryCache成就了一场笑话,那MemoryCache和Memcached有什么区别呢?
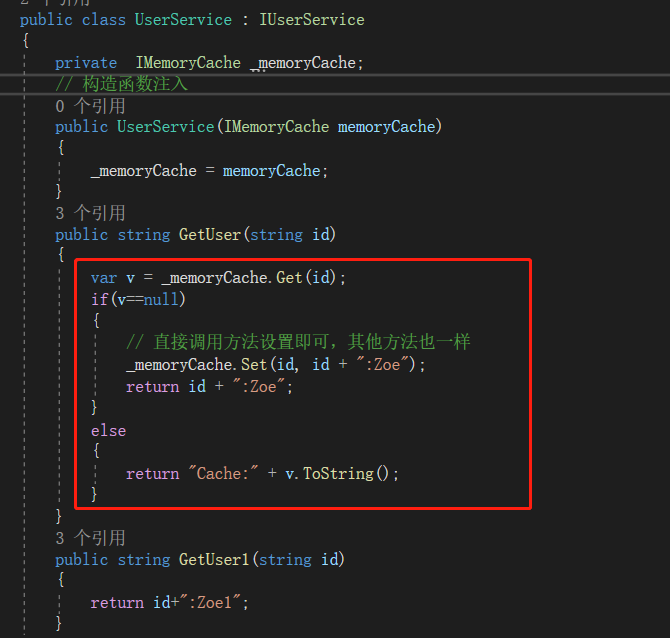
MemoryCache不是分布式缓存,是基于程序存储在内存中的;是微软封装好的内存缓存库,合理利用CPU,性能好;由于基于程序分配内存,使用时避免了网络通讯的消耗。
Memcached是分布式缓存,是存储在公共机器上的,供不同程序使用的,存在一定的网络传输消耗。
这样比较感觉有点勉强,虽然Memcached是分布式的,但也是基于内存的,在数据存储内存的逻辑还是不同的,不过这里不打算讲解源码,我要说应用,哈哈哈。
附加-为什么Redis让同事感觉性能不好真实场景是这样的,客户端开启多线程频繁读取Redis数据,当访问比较多时,导致Redis读取数据超过20毫秒,对于Web项目来说其实这还好,20毫秒的响应用户根本无法感知。但对于一个高性能要求的服务程序来说,对通讯要求就比较高,所以简单分析了一下拖慢的原因,大概以下两点:
客户端增多,导致一个常用Key对应的数据变大(其实不大,只是相对大,稍微影响了读取速度,毫秒级别);
解决方案:同事使用MemoryCache多做一层缓存,将这个常用Key直接存在内存中,提高读取性能;
使用类似于Keys * 的命令频繁获取数据,导致有些命令执行在20毫秒左右(慢日志中可以看到);
解决方案:改用Scan类似命令获取数据;
Redis自身的持久化耗时;
解决方案:适当调整Redis持久化策略,让持久化频率没那么高;
正文回归正题,既然说到MemoryCache,就来简单聊聊,主要分享在项目实战中如何使用;
主要依赖包:Microsoft.Extensions.Caching.Memory;
MemoryCache的使用很简单,就是在调用方法设置和获取值就对啦;来直接看Demo吧;
1. 控制台Demo其实有很多程序是基于后台服务运行的,并不都是Web,所以写了一个控制台的Demo,方便小伙伴参考;
1.1 引入相关包,项目中使用了Autofac作为依赖注入和其切面编程,则需要引入相关的依赖包,项目结构和包引入如下图: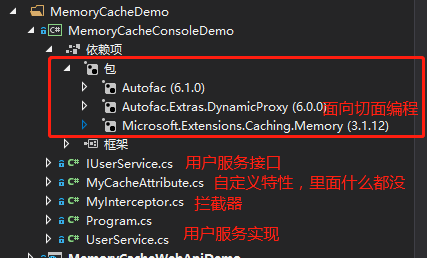
IUserService就是简单接口;

接口和方法上标注的Intercept和MyCache特性不是必须的,接下来会说;
UserService对接口的实现;

MyCacheAttribute自定义特性,用于标识,里面没有任何逻辑处理;
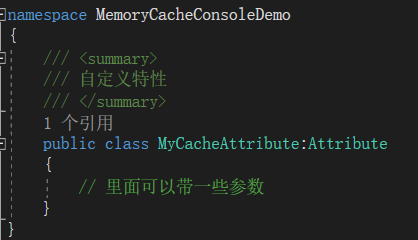
MyInterceptor自定义拦截器,面向切面的逻辑代码在这里处理;

代码完了,就开始使用Autofac注册服务,进行使用啦,如下:

注:Autofac不是必须的,根据自己需要进行选择使用,这里是为了要使用Autofac的切面编程功能。
1.3 两种方式进行缓存处理通常在非Web程序中,有以下两种方式进行缓存处理:
代码嵌入到业务逻辑,在真实业务逻辑处进行缓存获取或设置;