
原文地址:https://martinfowler.com/articles/patterns-of-distributed-systems/wal.html
Write-Ahead log 预写日志预写日志(WAL,Write-Ahead Log)将每次状态更新抽象为一个命令并追加写入一个日志中,这个日志只追加写入,也就是顺序写入,所以 IO 会很快。相比于更新存储的数据结构并且更新落盘这个随机 IO 操作,写入速度更快了,并且也提供了一定的持久性,也就是数据不会丢失,可以根据这个日志恢复数据。
背景介绍如果遇到了服务器存储数据失败,例如已经确认客户端的请求,但是存储过程中,重启进程导致真正存储的数据没有落盘,在重启后,也需要保证已经答应客户端的请求数据更新真正落盘成功。
解决方案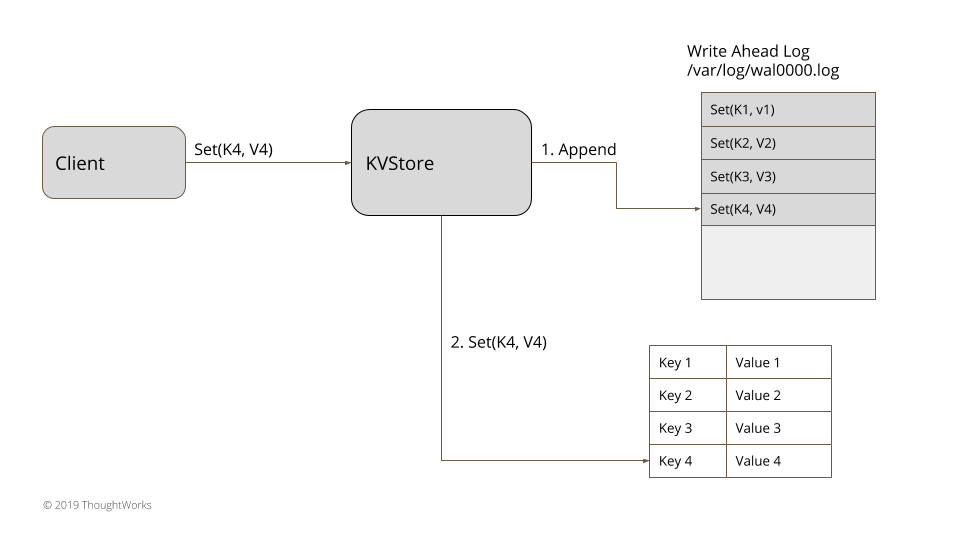
将每一个更新,抽象为一个指令,并将这些指令存储在一个文件中。每个进程顺序追加写各自独立的一个文件,简化了重启后日志的处理,以及后续的在线更新操作。每个日志记录有一个独立 id,这个 id 可以用来实现分段日志(Segmented Log)或者最低水位线(Low-Water Mark)清理老的日志。日志更新可以使用单一更新队列(Singular Update Queue)这种设计模式。
日志记录的结构类似于:
class WALEntry { //日志id private final Long entryId; //日志内容 private final byte[] data; //类型 private final EntryType entryType; //时间 private long timeStamp; }在每次重新启动时读取日志文件,回放所有日志条目来恢复当前数据状态。
假设有一内存键值对数据库:
class KVStore { private Map<String, String> kv = new HashMap<>(); public String get(String key) { return kv.get(key); } public void put(String key, String value) { appendLog(key, value); kv.put(key, value); } private Long appendLog(String key, String value) { return wal.writeEntry(new SetValueCommand(key, value).serialize()); } }put 操作被抽象为 SetValueCommand,在更新内存 hashmap 之前将其序列化并存储在日志中。SetValueCommand 可以序列化和反序列化。
class SetValueCommand { final String key; final String value; public SetValueCommand(String key, String value) { this.key = key; this.value = value; } @Override public byte[] serialize() { try { //序列化 var baos = new ByteArrayOutputStream(); var dataInputStream = new DataOutputStream(baos); dataInputStream.writeInt(Command.SetValueType); dataInputStream.writeUTF(key); dataInputStream.writeUTF(value); return baos.toByteArray(); } catch (IOException e) { throw new RuntimeException(e); } } public static SetValueCommand deserialize(InputStream is) { try { //反序列化 DataInputStream dataInputStream = new DataInputStream(is); return new SetValueCommand(dataInputStream.readUTF(), dataInputStream.readUTF()); } catch (IOException e) { throw new RuntimeException(e); } } }这可以确保即使进程重启,这个 hashmap 也可以通过在启动时读取日志文件来恢复。
class KVStore { public KVStore(Config config) { this.config = config; this.wal = WriteAheadLog.openWAL(config); this.applyLog(); } public void applyLog() { List<WALEntry> walEntries = wal.readAll(); applyEntries(walEntries); } private void applyEntries(List<WALEntry> walEntries) { for (WALEntry walEntry : walEntries) { Command command = deserialize(walEntry); if (command instanceof SetValueCommand) { SetValueCommand setValueCommand = (SetValueCommand)command; kv.put(setValueCommand.key, setValueCommand.value); } } } public void initialiseFromSnapshot(SnapShot snapShot) { kv.putAll(snapShot.deserializeState()); } } 实现考虑首先是保证 WAL 日志真的写入了磁盘。所有编程语言提供的文件处理库提供了一种机制,强制操作系统将文件更改flush落盘。在flush时,需要考虑的是一种权衡。对于日志的每一条记录都flush一次,保证了强持久性,但是严重影响了性能并且很快会成为性能瓶颈。如果是异步flush,性能会提高,但是如果在flush前程序崩溃,则有可能造成日志丢失。大部分的实现都采用批处理,减少flush带来的性能影响,同时也尽量少丢数据。
另外,我们还需要保证日志文件没有损坏。为了处理这个问题,日志条目通常伴随 CRC 记录写入,然后在读取文件时进行验证。
同时,采用单个日志文件可能变得很难管理(很难清理老日志,重启时读取文件过大)。为了解决这个问题,通常采用之前提到的分段日志(Segmented Log)或者最低水位线(Low-Water Mark)来减少程序启动时读取的文件大小以及清理老的日志。