If your applications aren't sending traces, yet, configure them with Zipkin instrumentation or try one of our examples.
Check out the zipkin-server documentation for configuration details, or docker-zipkin for how to use docker-compose.
以上内容来自zipkin官方github摘录。简单解释就是可以使用https下载的方式下载zipkin.jar,并使用java -jar的方式启动,还有一种就是使用docker的方式进行启动。
具体搭建过程我这里就不在赘述,有不懂的可以私信或者关注公众号留言问我。
3.1.2 zipkin启动zipkin的启动命令就比较谜了。
最简单的启动命令为:nohup java -jar zipkin.jar >zipkin.out 2>&1 &,这时,我们使用的是zipkin的In-Memory,含义是所有的数据都保存在内存中,一旦重启数据将全部清空,这肯定不是我们想要的,我们更想数据可以保存在磁盘中,可以被抽取到大数据平台上,方便我们后续的相关性能、服务状态分析、实时报警等功能。
这里我把使用mysql的启动语句分享出来,有关ES的启动语句基本相同:
STORAGE_TYPE=mysql MYSQL_DB=zipkin MYSQL_USER=name MYSQL_PASS=password MYSQL_HOST=172.19.237.44 MYSQL_TCP_PORT=3306 MYSQL_USE_SSL=false nohup java -jar zipkin.jar --zipkin.collector.rabbitmq.addresses=localhost --zipkin.collector.rabbitmq.username=username --zipkin.collector.rabbitmq.password=password --logging.level.zipkin2=DEBUG >zipkin.out 2>&1 &注意: 因为链路追踪的数据上报量是非常大的,如果上报数据直接使用http请求的方式推送到zipkin中,很有可能会把zipkin服务或者数据库冲崩掉,所以我在这里增加了rabbitmq的相关配置,上报数据先推送至rabbitmq中,再由rabbitmq讲数据推送至zipkin服务,这样达到一个请求削峰填谷的作用。
有关zipkin的启动命令可以配置的参数可以看这里:https://github.com/apache/incubator-zipkin/tree/master/zipkin-server
有关zipkin配置mysql基础建表语句可以看这里:https://github.com/apache/incubator-zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
有关zipkin本身配置文件可以看这里:https://github.com/apache/incubator-zipkin/blob/master/zipkin-server/src/main/resources/zipkin-server-shared.yml
至此,zipkin服务应该已经搭建并完成,现在我们可以访问一下默认端口,看一下zipkin-ui具体长什么样子了。
我们先将上一篇用到的zuul-simple、Eureka和producer copy到本篇文章使用的文件夹中。
3.2.1 增加依赖: <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency>在zuul-simple和producer两个项目中增加sleuth和rabbitmq的依赖。
3.2.2 配置文件增加有关rabbitmq和sleuth的配置,这里我仅给出zuul的配置文件,producer的配置同理。
server: port: 8080 spring: application: name: spring-cloud-zuul rabbitmq: host: host port: port username: username password: password sleuth: sampler: probability: 1.0 zuul: FormBodyWrapperFilter: pre: disable: true eureka: client: service-url: defaultZone: :8761/eureka/注:spring.sleuth.sampler.probability的含义是链路追踪采样率,默认是0.1,我这里为了方便测试,将其改成1.0,意思是百分之百采样。
3.2.3 测试这里我们依次启动Eureka、producer和zuul-simple。
打开浏览器,访问测试连接::8080/spring-cloud-producer/hello?name=spring&token=123
这时我们先看zuul的日志,如下图:
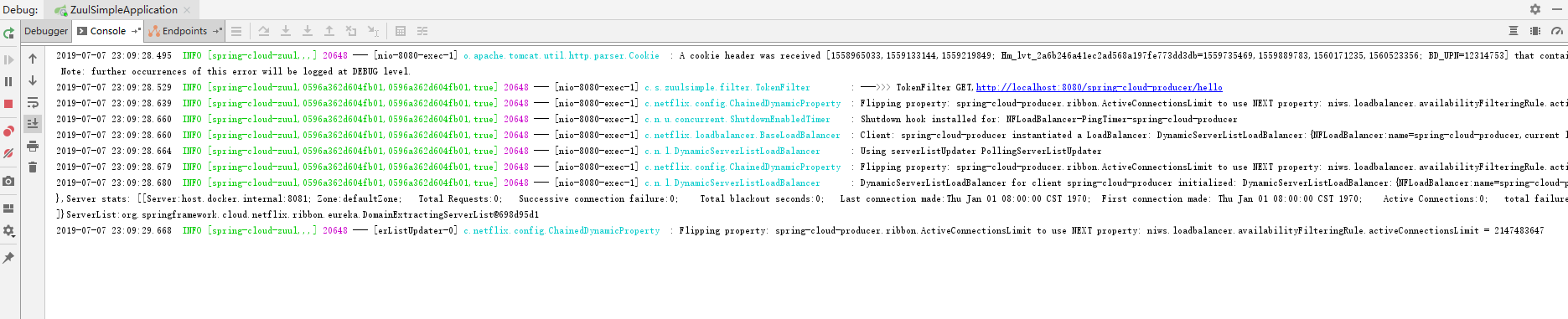
注:这里的0596a362d604fb01就是这个请求的traceID,0596a362d604fb01是spanID。
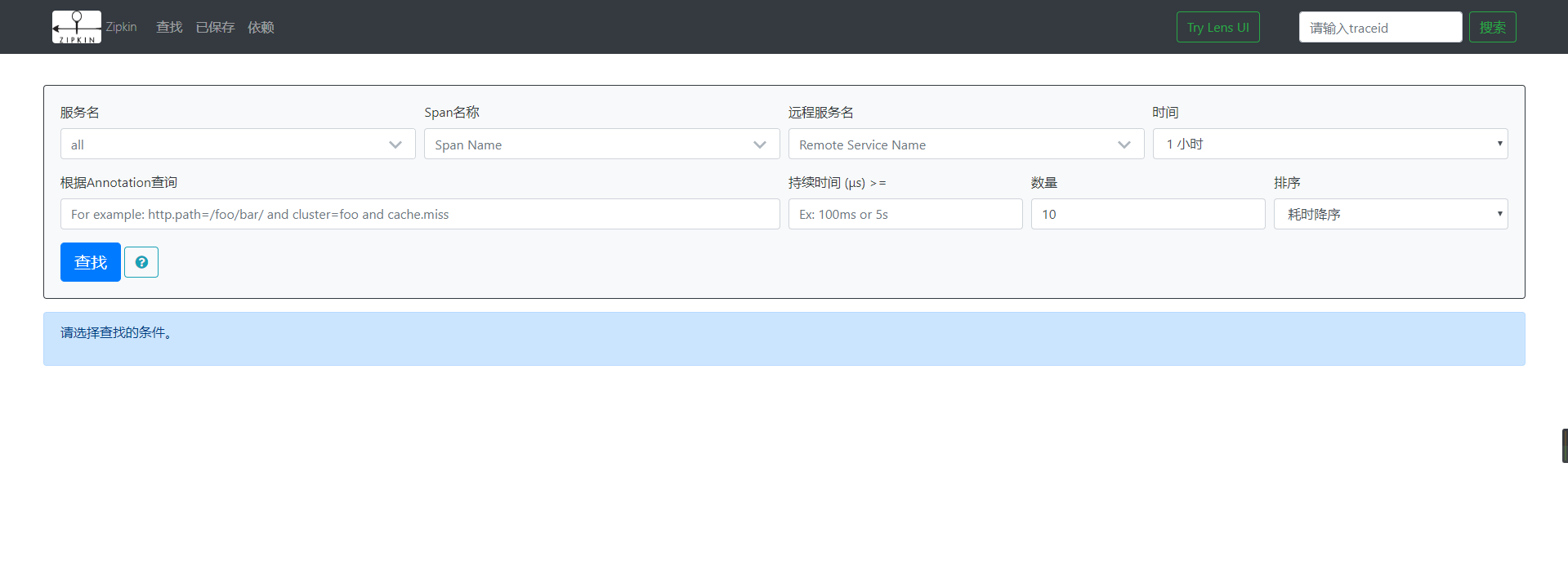
我们打开zipkin-ui的界面,如下图:
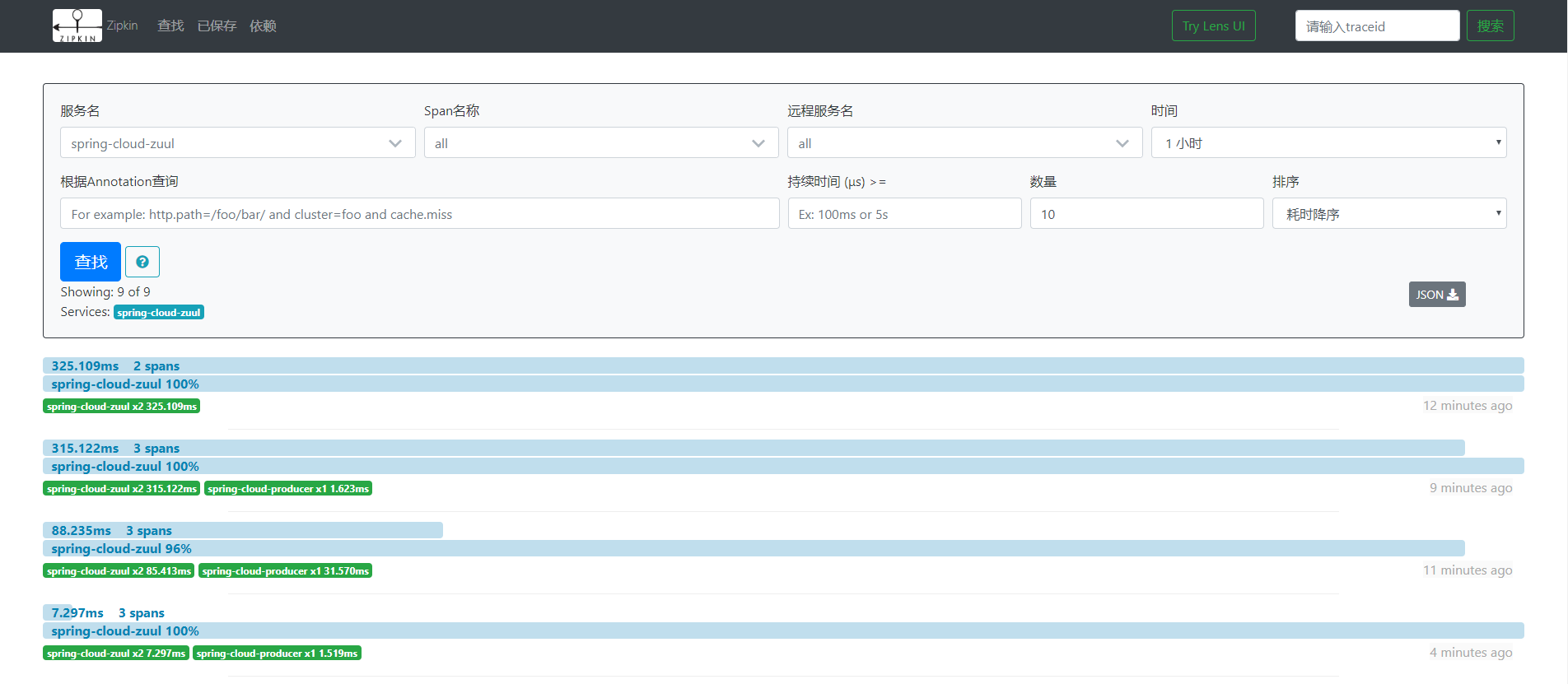
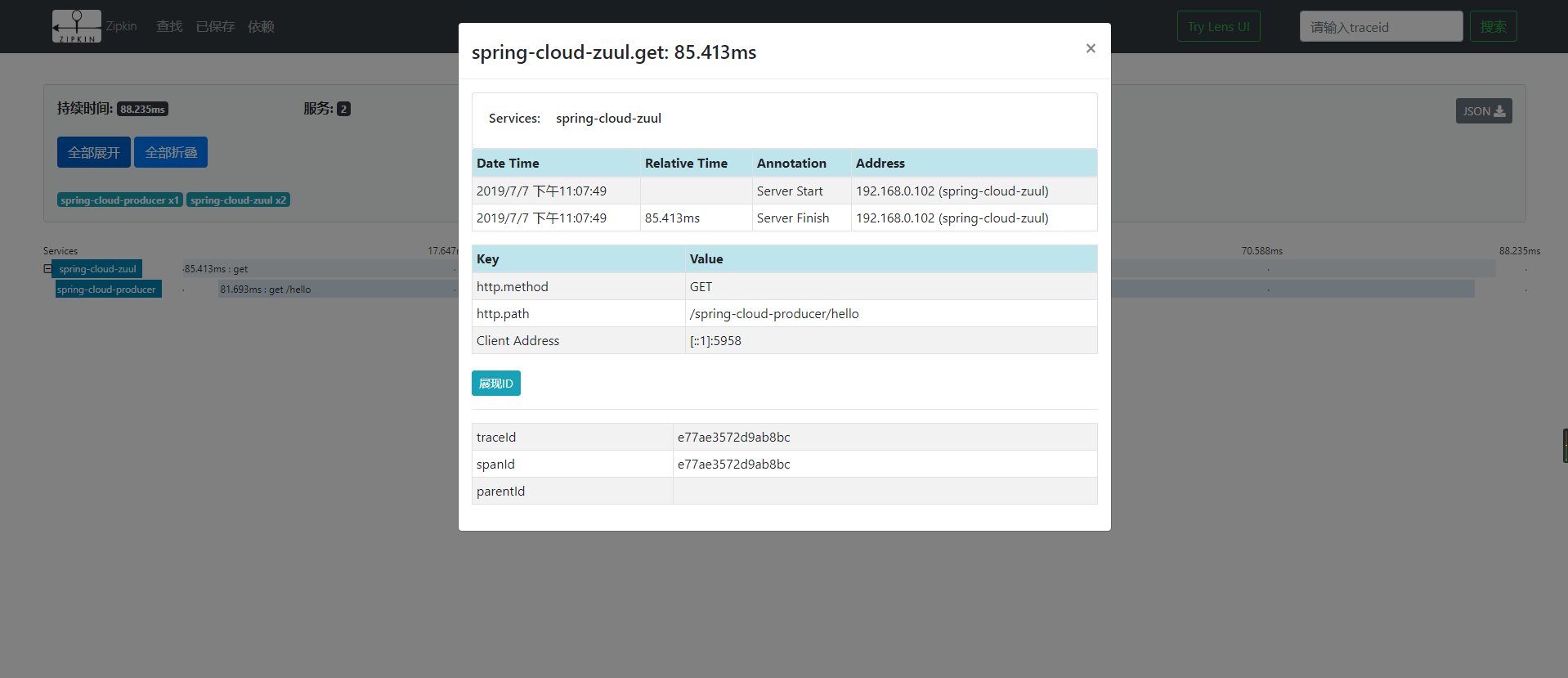
这里我们可以看到这个请求的整体耗时,点击这个请求,可以进入到详情页面,查看每个服务的耗时:
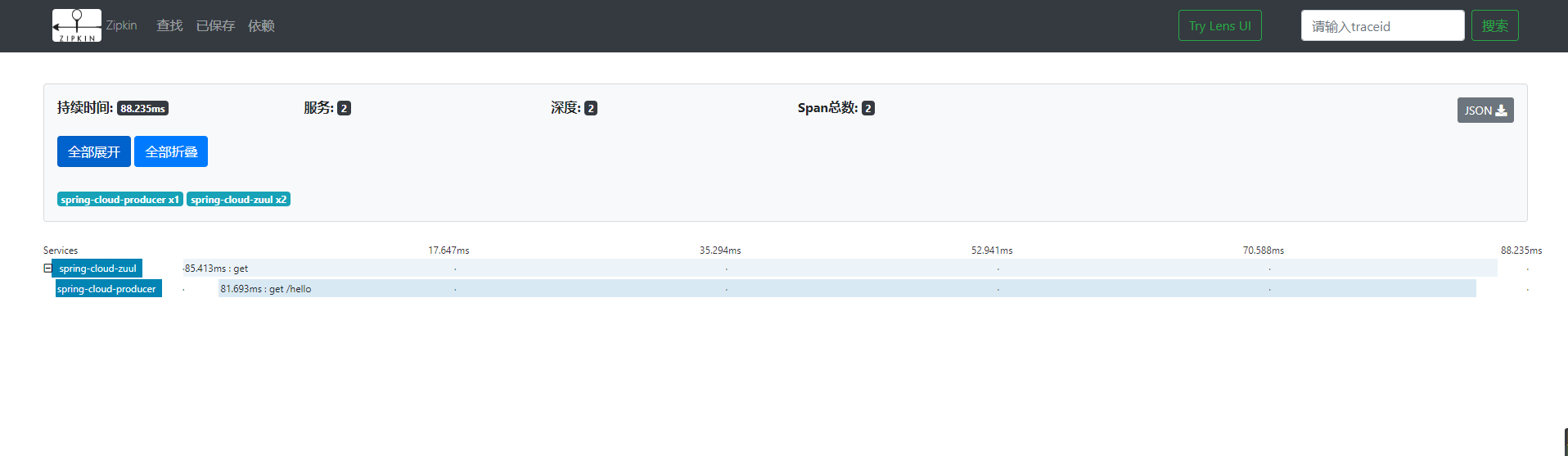
点击对应的服务,我们可以看到相应的访问时间,http请求类型、路径、IP、tranceID、spanId等内容,如下图: