
在解决分类问题的时候,可以选择的评价指标简直不要太多。但基本可以分成两2大类,我们今分别来说道说道
基于一个概率阈值判断在该阈值下预测的准确率
衡量模型整体表现(在各个阈值下)的评价指标
在说指标之前,咱先把分类问题中会遇到的所有情况简单过一遍。36度的北京让我们举个凉快一点的例子-我们预测会不会下雨!横轴是预测概率从0-1,红色的部分是没下雨的日子(负样本),蓝色的部分是下雨的日子(正样本)。在真实情况下我们很难找到能对正负样本进行完美分割的分类器,所以我们看到在预测概率靠中间的部分,正负样本存在重合,也就是不管我们阈值卡在哪里都会存在被错误预测的样本。
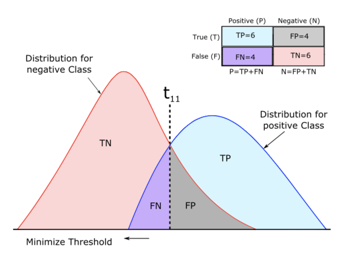
上述分布中的四种情况,可以简单的用confusion matrix来概括

TP:预测为正&真实为正
FP:预测为正&真实为负
TN:预测为负&真实为负
FN:预测为负&真实为正
分类模型输出的是每个样本为正的概率,我们要先把概率转换成0/1预测。给定一个阈值,我们把预测概率大于阈值的样本预测为正,小于的为负。这时就会出现上述confustion matrix里面的四种情况。那我们该如何去评价模型表现呢?
新手视角- Accuracy!这应该是大多数人第一个知道的评价指标,它把正负样本混在一起去评价整体的分类准确率。
\[Accuracy = \frac{TP + TN}{TP + TN + FN + FP}\]
老手会用一个在所有tutorial里面都能看到的Imbalance Sample的例子来告诉你,如果你的正样本只有1%,那全部预测为负你的准确率就是99%啦 - so simple and naive ~.~
当然Accuracy也不是不能用,和正样本占比放在一起比较也是能看出来一些信息的。但Accuracy确实更适用正负样本55开,且预测不止针对正样本的情况。
Accuracy知道咋算就可以啦,在解决实际问题的时候,往往会使用更有指向性的指标, 而且一般都会同时选用2个以上的指标因为不同指标之间往往都有trade-off
当目标是对正样本进行准确预测 - precision, recall, F1precision从预测的角度衡量预测为正的准确率,recall从真实分布的角度衡量预测为正的准确率。precision和recall存在trade-off, 想要挑选出更多的正样本,就要承担预测为正准确率下降的风险。例如在飞机过安检时,想要保证危险物品基本都被识别出来,就肯定要承担一定的误判率。不过在这种情境下查不出危险物品显然比让误判乘客多开包检查一遍要重要的多。
\[ \begin{align} precision &= \frac{TP}{TP+FP} \\ recall &= \frac{TP}{TP+FN} \end{align} \]
既然有trade-off,一般就会用可以综合两个指标的复合指标 - F1 Score
\[
F1 =\frac{1}{\frac{1}{precision} + \frac{1}{recall}}= \frac{precision * recall}{precision + recall}
\]
其实简单一点直接对precision,recall求平均也可以作为复合指标,但F1用了先取倒数再求平均的方式来避免precision或recall等于0这种极端情况的出现
当目标是对真实分布进行准确预测 - sensitivity(recall), specifity, fprsensitivity, sepcifity都从真实分布的角度,分别衡量正/负样本预测的准确率。这一对搭配最常在医学检验中出现,衡量实际生病/没生病的人分别被正确检验的概率。正确检验出一个人有病很重要,同时正确排除一个人没生病也很重要。
\[ \begin{align} sensitivity &= recall \\ specifity & =\frac{TN}{TN + FP} \\ \end{align} \]
如果specifity对很多人来说很陌生的话,它兄弟很多人一定知道fpr。fpr和recall(tpr)一起构成了ROC曲线。这一对的tradeoff同样用医学检验的逻辑来解释就是,医生既不希望遗漏病人的病情(recall),要不希望把本身没病的人吓出病来(fpr)。
\[
fpr = \frac{FP}{TN+FP} = 1- specifity
\]
和阈值相关经常用到的指标差不多就是这些。这些指标的计算依赖于阈值的确定,所以在应用中往往用验证集来找出使F1/accuracy最大的阈值,然后应用于测试集,再用测试集的F1/accuracy来评价模型表现。下面是几个应用上述指标的kaggle比赛
F1 score
https://www.kaggle.com/c/quora-insincere-questions-classification/overview/evaluation
accuracy
https://www.kaggle.com/c/titanic/overview/evaluation
不过开始用到和阈值相关的评价指标有时是在模型已经确定以后。第一步在确定模型时,往往还是需要一些可以综合衡量模型整体表现的指标。简单!粗暴!别整啥曲线阈值的,你给我个数就完了!
综合评价指标综合评价指标基本都是对上述指标再加工的产物。对应的kaggle比赛会持续更新。
tpr(recall) + fpr = ROC-> AUC随着阈值从1下降到0,我们预测为正的样本会逐渐变多,被正确筛选出的正样本会逐渐增多,但同时负样本被误判为正的概率也会逐渐上升。