候选者:从前面讲到的,可以发现的是:当CPU修改数据时,需要「同步」告诉其他的CPU,等待其他CPU响应接收到invalid(无效)后,它才能将高速缓存数据写到主存。
候选者:同步,意味着等待,等待意味着什么都干不了。CPU肯定不乐意啊,所以又优化了一把。
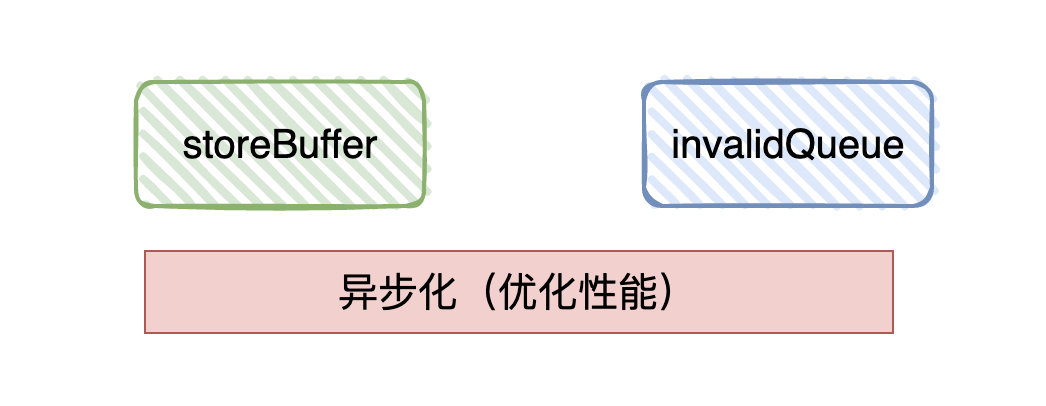
候选者:优化思路就是从「同步」变成「异步」。
候选者:在修改时会「同步」告诉其他CPU,而现在则把最新修改的值写到「store buffer」中,并通知其他CPU记得要改状态,随后CPU就直接返回干其他事了。等到收到其它CPU发过来的响应消息,再将数据更新到高速缓存中。
候选者:其他CPU接收到invalid(无效)通知时,也会把接收到的消息放入「invalid queue」中,只要写到「invalid queue」就会直接返回告诉修改数据的CPU已经将状态置为「invalid」
候选者:而异步又会带来新问题:那我现在CPU修改完A值,写到「store buffer」了,CPU就可以干其他事了。那如果该CPU又接收指令需要修改A值,但上一次修改的值还在「store buffer」中呢,没修改至高速缓存呢。
候选者:所以CPU在读取的时候,需要去「store buffer」看看存不存在,存在则直接取,不存在才读主存的数据。【Store Forwarding】
候选者:好了,解决掉第一个异步带来的问题了。(相同的核心对数据进行读写,由于异步,很可能会导致第二次读取的还是旧值,所以首先读「store buffer」。
面试官:还有其他?
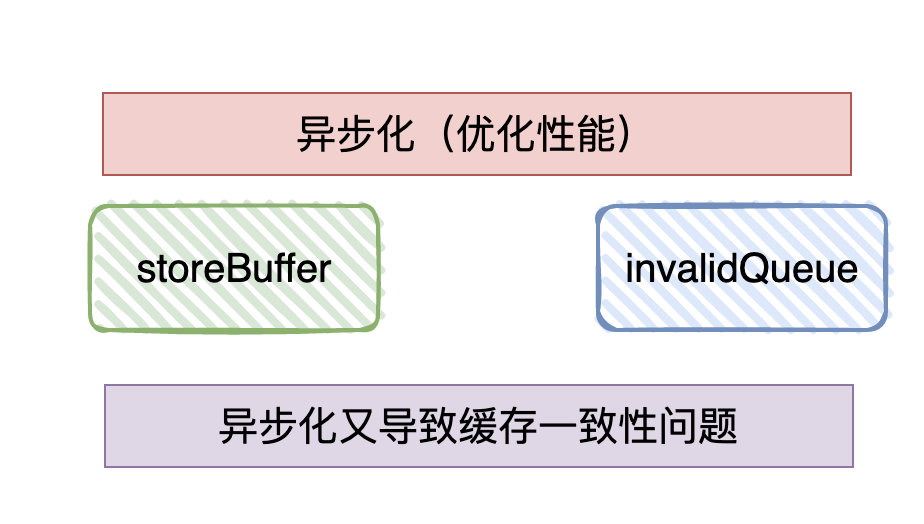
候选者:那当然啊,那「异步化」会导致相同核心读写共享变量有问题,那当然也会导致「不同」核心读写共享变量有问题啊
候选者:CPU1修改了A值,已把修改后值写到「store buffer」并通知CPU2对该值进行invalid(无效)操作,而CPU2可能还没收到invalid(无效)通知,就去做了其他的操作,导致CPU2读到的还是旧值。
候选者:即便CPU2收到了invalid(无效)通知,但CPU1的值还没写到主存,那CPU2再次向主存读取的时候,还是旧值...
候选者:变量之间很多时候是具有「相关性」(a=1;b=0;b=a),这对于CPU又是无感知的...
候选者:总体而言,由于CPU对「缓存一致性协议」进行的异步优化「store buffer」「invalid queue」,很可能导致后面的指令很可能查不到前面指令的执行结果(各个指令的执行顺序非代码执行顺序),这种现象很多时候被称作「CPU乱序执行」
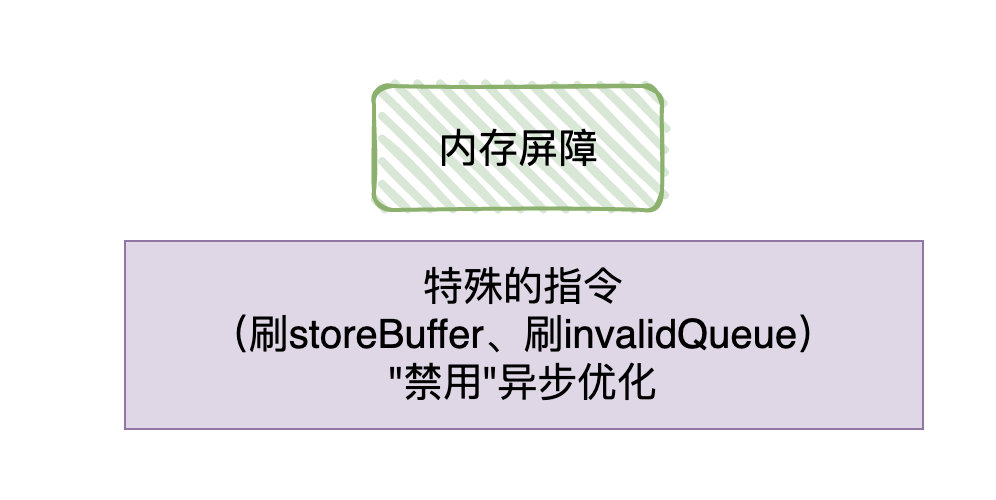
候选者:为了解决乱序问题(也可以理解为可见性问题,修改完没有及时同步到其他的CPU),又引出了「内存屏障」的概念。
面试官:嗯...
候选者:「内存屏障」其实就是为了解决「异步优化」导致「CPU乱序执行」/「缓存不及时可见」的问题,那怎么解决的呢?嗯,就是把「异步优化」给”禁用“掉(:
候选者:内存屏障可以分为三种类型:写屏障,读屏障以及全能屏障(包含了读写屏障),屏障可以简单理解为:在操作数据的时候,往数据插入一条"特殊的指令"。只要遇到这条指令,那前面的操作都得「完成」。
候选者:那写屏障就可以这样理解:CPU当发现写屏障的指令时,会把该指令「之前」存在于「store Buffer」所有写指令刷入高速缓存。
候选者:通过这种方式就可以让CPU修改的数据可以马上暴露给其他CPU,达到「写操作」可见性的效果。
候选者:那读屏障也是类似的:CPU当发现读屏障的指令时,会把该指令「之前」存在于「invalid queue」所有的指令都处理掉
候选者:通过这种方式就可以确保当前CPU的缓存状态是准确的,达到「读操作」一定是读取最新的效果。