
面试官:今天想跟你聊聊Java内存模型,这块你了解过吗?
候选者:嗯,我简单说下我的理解吧。那我就从为什么要有Java内存模型开始讲起吧
面试官:开始你的表演吧。
候选者:那我先说下背景吧
候选者:1. 现有计算机往往是多核的,每个核心下会有高速缓存。高速缓存的诞生是由于「CPU与内存(主存)的速度存在差异」,L1和L2缓存一般是「每个核心独占」一份的。
候选者:2. 为了让CPU提高运算效率,处理器可能会对输入的代码进行「乱序执行」,也就是所谓的「指令重排序」
候选者:3. 一次对数值的修改操作往往是非原子性的(比如i++实际上在计算机执行时就会分成多个指令)
候选者:在永远单线程下,上面所讲的均不会存在什么问题,因为单线程意味着无并发。并且在单线程下,编译器/runtime/处理器都必须遵守as-if-serial语义,遵守as-if-serial意味着它们不会对「数据依赖关系的操作」做重排序。

候选者:CPU为了效率,有了高速缓存、有了指令重排序等等,整块架构都变得复杂了。我们写的程序肯定也想要「充分」利用CPU的资源啊!于是乎,我们使用起了多线程
候选者:多线程在意味着并发,并发就意味着我们需要考虑线程安全问题
候选者:1. 缓存数据不一致:多个线程同时修改「共享变量」,CPU核心下的高速缓存是「不共享」的,那多个cache与内存之间的数据同步该怎么做?
候选者:2. CPU指令重排序在多线程下会导致代码在非预期下执行,最终会导致结果存在错误的情况。

候选者:针对于「缓存不一致」问题,CPU也有其解决办法,常被大家所认识的有两种:
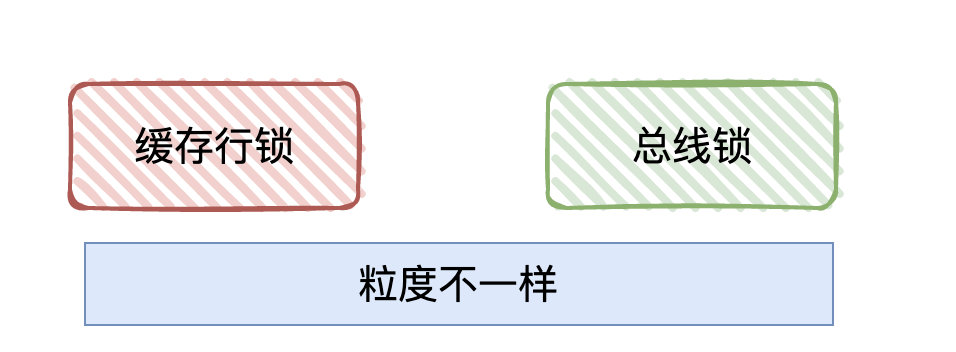
候选者:1.使用「总线锁」:某个核心在修改数据的过程中,其他核心均无法修改内存中的数据。(类似于独占内存的概念,只要有CPU在修改,那别的CPU就得等待当前CPU释放)
候选者:2.缓存一致性协议(MESI协议,其实协议有很多,只是举个大家都可能见过的)。MESI拆开英文是(Modified (修改状态)、Exclusive (独占状态)、Share(共享状态)、Invalid(无效状态))
候选者:缓存一致性协议我认为可以理解为「缓存锁」,它针对的是「缓存行」(Cache line) 进行"加锁",所谓「缓存行」其实就是 高速缓存 存储的最小单位。
面试官:嗯...
候选者:MESI协议的原理大概就是:当每个CPU读取共享变量之前,会先识别数据的「对象状态」(是修改、还是共享、还是独占、还是无效)。
候选者:如果是独占,说明当前CPU将要得到的变量数据是最新的,没有被其他CPU所同时读取
候选者:如果是共享,说明当前CPU将要得到的变量数据还是最新的,有其他的CPU在同时读取,但还没被修改
候选者:如果是修改,说明当前CPU正在修改该变量的值,同时会向其他CPU发送该数据状态为invalid(无效)的通知,得到其他CPU响应后(其他CPU将数据状态从共享(share)变成invalid(无效)),会当前CPU将高速缓存的数据写到主存,并把自己的状态从modify(修改)变成exclusive(独占)
候选者:如果是无效,说明当前数据是被改过了,需要从主存重新读取最新的数据。

候选者:其实MESI协议做的就是判断「对象状态」,根据「对象状态」做不同的策略。关键就在于某个CPU在对数据进行修改时,需要「同步」通知其他CPU,表示这个数据被我修改了,你们不能用了。
候选者:比较于「总线锁」,MESI协议的"锁粒度"更小了,性能那肯定会更高咯
面试官:但据我了解,CPU还有优化,你还知道吗?
候选者:嗯,还是了解那么一点点的。