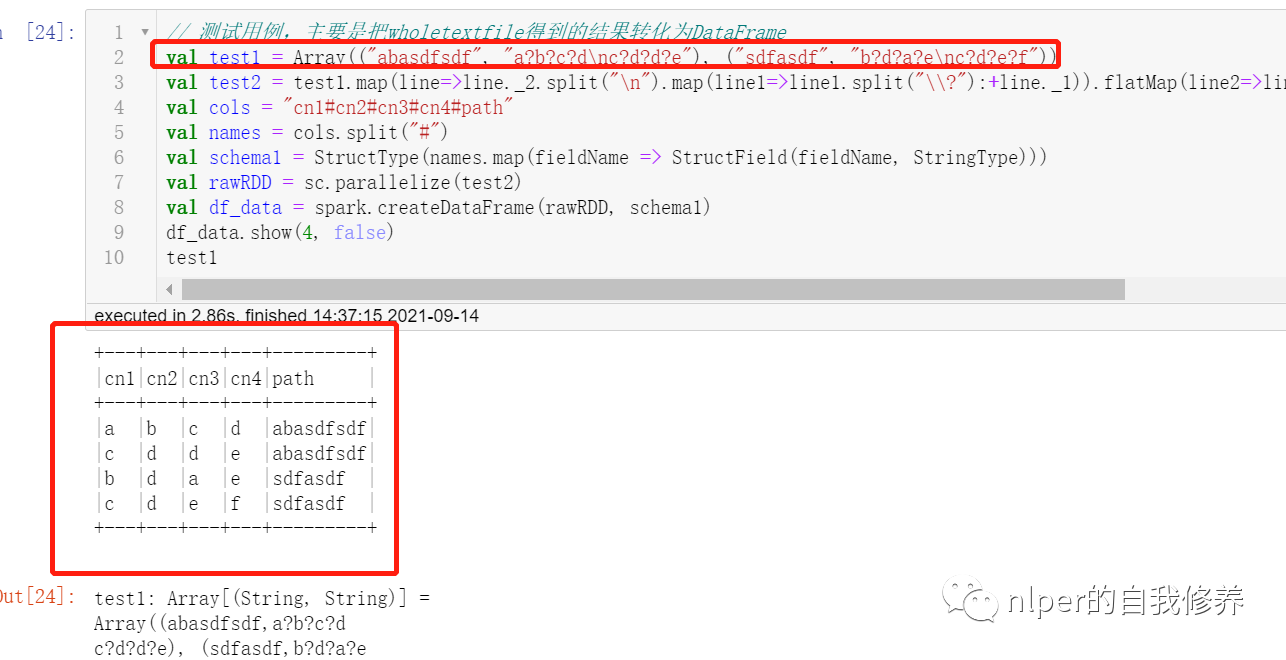
通过for循环遍历读取文件夹里面的文件时,保留文件名信息;
具体示例可以参考文末的
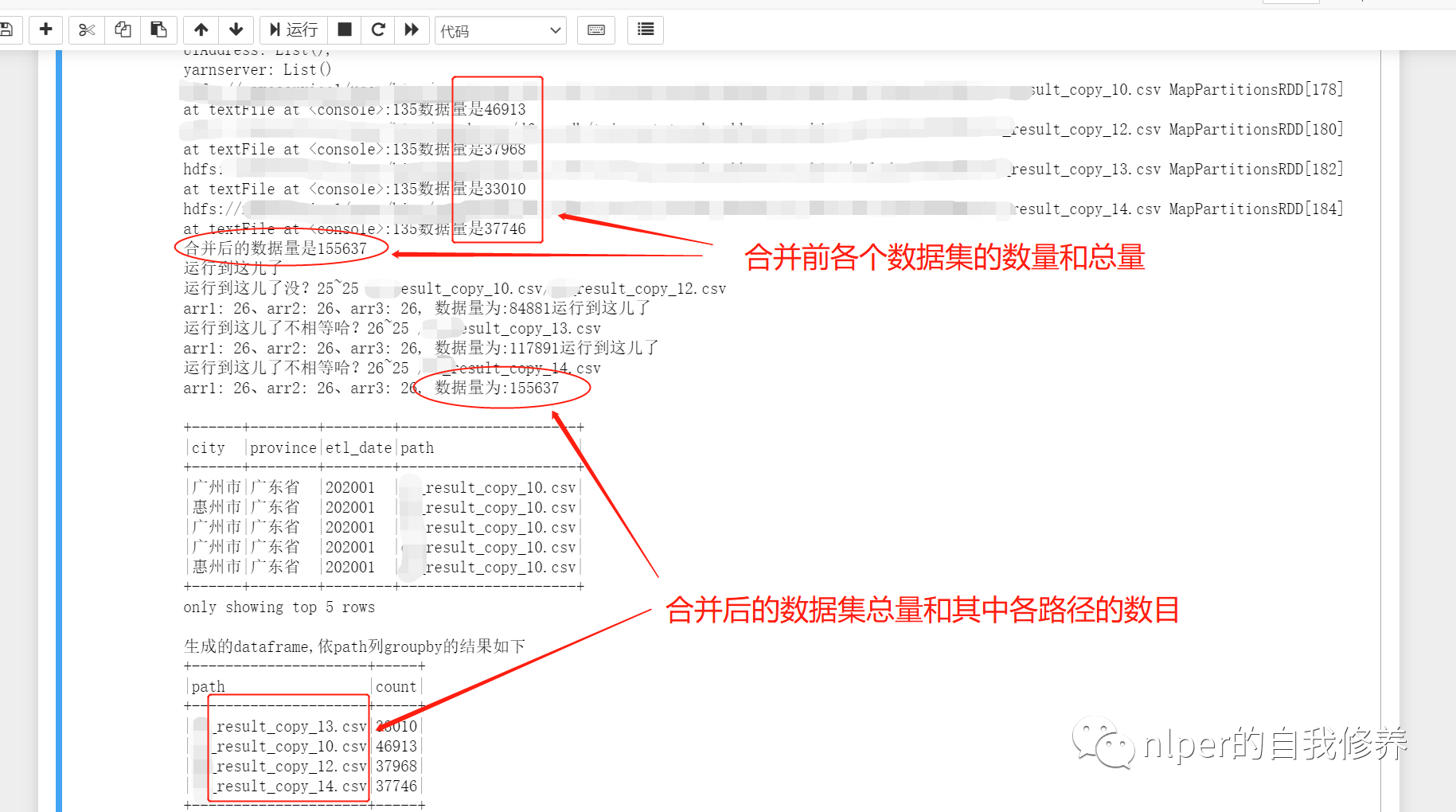
import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, Row} import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.sql.functions.monotonically_increasing_id import org.apache.log4j.{Level, Logger} import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType} import org.apache.hadoop.fs.{FileSystem, Path} Logger.getLogger("org").setLevel(Level.WARN) // val log = Logger.getLogger(this.getClass) @transient lazy val log:Logger = Logger.getLogger(this.getClass) class DataProcess_get_data_byfor (ss: SparkSession) extends java.io.Serializable{ import ss.implicits._ import ss.sql import org.apache.spark.sql.types.DataTypes ... def union_dataframe(df_1:RDD[String], df_2:RDD[String]):RDD[String] ={ val count1 = df_1.map(item=>item.split(sep_line)).take(1)(0).length val count2 = df_2.map(item=>item.split(sep_line)).take(1)(0).length val name2 = df_2.name.split("http://www.likecs.com/").takeRight(1)(0) val arr2 = df_2.map(item=>item.split(sep_line):+name2).map(p => Row(p: _*)) println(s"运行到这儿了") var name1 = "" var arr1 = ss.sparkContext.makeRDD(List().map(p => Row(p: _*))) // var arr1 = Array[org.apache.spark.sql.Row] if (count1 == count2){ name1 = df_1.name.split("http://www.likecs.com/").takeRight(1)(0) arr1 = df_1.map(item=>item.split(sep_line):+name1).map(p => Row(p: _*)) // arr1.foreach(f=>print(s"arr1嘞$f" + f.length + "\n")) println(s"运行到这儿了没?$count1~$count2 $name1/$name2") arr1 } else{ println(s"运行到这儿了不相等哈?$count1~$count2 $name1/$name2") arr1 = df_1.map(item=>item.split(sep_line)).map(p => Row(p: _*)) } var rawRDD = arr1.union(arr2) // arr3.foreach(f=>print(s"$f" + f.length + "\n")) // var rawRDD = sc.parallelize(arr3) var sourceRdd = rawRDD.map(_.mkString(sep_line)) // var count31 = arr1.take(1)(0).length // var count32 = arr2.take(1)(0).length // var count3 = sourceRdd.map(item=>item.split(sep_line)).take(1)(0).length // var nums = sourceRdd.count // print(s"arr1: $count31、arr2: $count32、arr3: $count3, 数据量为:$nums") sourceRdd } } object LoadingData_from_hdfs_text_with_path_byfor extends mylog{// with Logging ... def main(args: Array[String]=Array("tb1", "hdfs:/", "3","\n", "\001", "cols","data1", "test", "")): Unit = { ... val hdfs_address = args(1) ... val pattern = args(6) val pattern_no = args(7) val select_cols = select_col.split("#").toSeq log.warn(s"Loading cols are : \n $select_cols") val files = FileSystem.get(spark.sparkContext.hadoopConfiguration).listStatus(new Path(s"$hdfs_address")) val files_name = files.toList.map(f=> f.getPath.getName) val file_filter = files_name.filter(_.contains(pattern)).filterNot(_.contains(pattern_no)) val df_1 = file_filter.map(item=> sc.textFile(s"$path1$item")) df_1.foreach(f=>{ println(f + "数据量是" + f.count) }) val df2 = df_1.reduce(_ union _) println("合并后的数据量是" + df2.count) val Cs = new DataProcess_get_data_byfor(spark) ... // 将for循环读取的结果合并起来 val result = df_1.reduce((a, b)=>union_dataframe(a, b)) val result2 = result.map(item=>item.split(sep_line)).map(p => Row(p: _*)) val df_data = spark.createDataFrame(result2, new_schema1) val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left") println("\n") //df_desc.show(false) val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*) df_gb_result.show(5, false) println("生成的dataframe,依path列groupby的结果如下") df_gb_result.groupBy("path").count().show(false) ... // spark.stop() } } val path1 = "hdfs:202001/" val tb_name = "tb_name" val sep_text = "\n" val sep_line = "\001" val cols = "city#province#etl_date#path" val pattern = "result_copy_1" val pattern_no = "1.csv" // val file_filter = List("file1_10.csv", "file_12.csv", "file_11.csv") // 执行脚本 LoadingData_from_hdfs_text_with_path_byfor.main(Array(tb_name, path1, "4", sep_line, sep_text, cols, pattern, pattern_no, ""))