
spark读取hive表的数据,主要包括直接sql读取hive表;通过hdfs文件读取hive表,以及hive分区表的读取。
通过jupyter上的cell来初始化sparksession。
文末还有通过spark提取hdfs文件的完整示例
jupyter配置文件我们可以在jupyter的cell框里面,对spark的session做出对应的初始化,具体可以见下面的示例。
%%init_spark launcher.master = "local[*]" launcher.conf.spark.app.name = "BDP-xw" launcher.conf.spark.driver.cores = 2 launcher.conf.spark.num_executors = 3 launcher.conf.spark.executor.cores = 4 launcher.conf.spark.driver.memory = '4g' launcher.conf.spark.executor.memory = '4g' // launcher.conf.spark.serializer = "org.apache.spark.serializer.KryoSerializer" // launcher.conf.spark.kryoserializer.buffer.max = '4g' import org.apache.spark.sql.SparkSession var NumExecutors = spark.conf.getOption("spark.num_executors").repr var ExecutorMemory = spark.conf.getOption("spark.executor.memory").repr var AppName = spark.conf.getOption("spark.app.name").repr var max_buffer = spark.conf.getOption("spark.kryoserializer.buffer.max").repr println(f"Config as follows: \nNumExecutors: $NumExecutors, \nAppName: $AppName,\nmax_buffer:$max_buffer")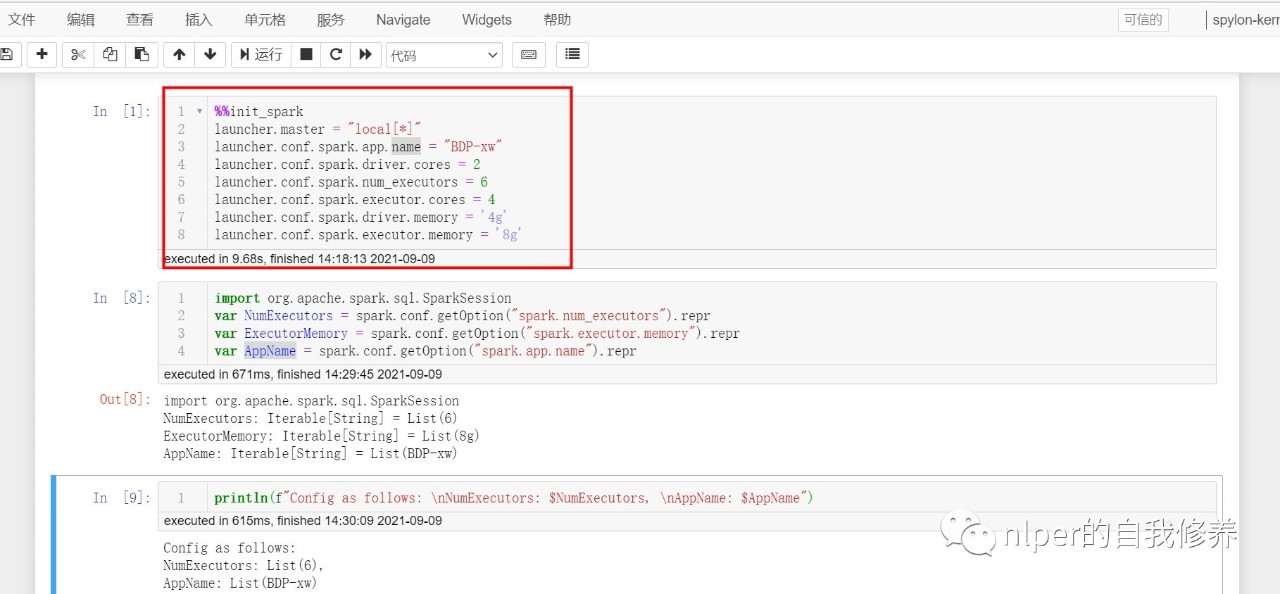
直接查看我们初始化的sparksession对应的环境各变量
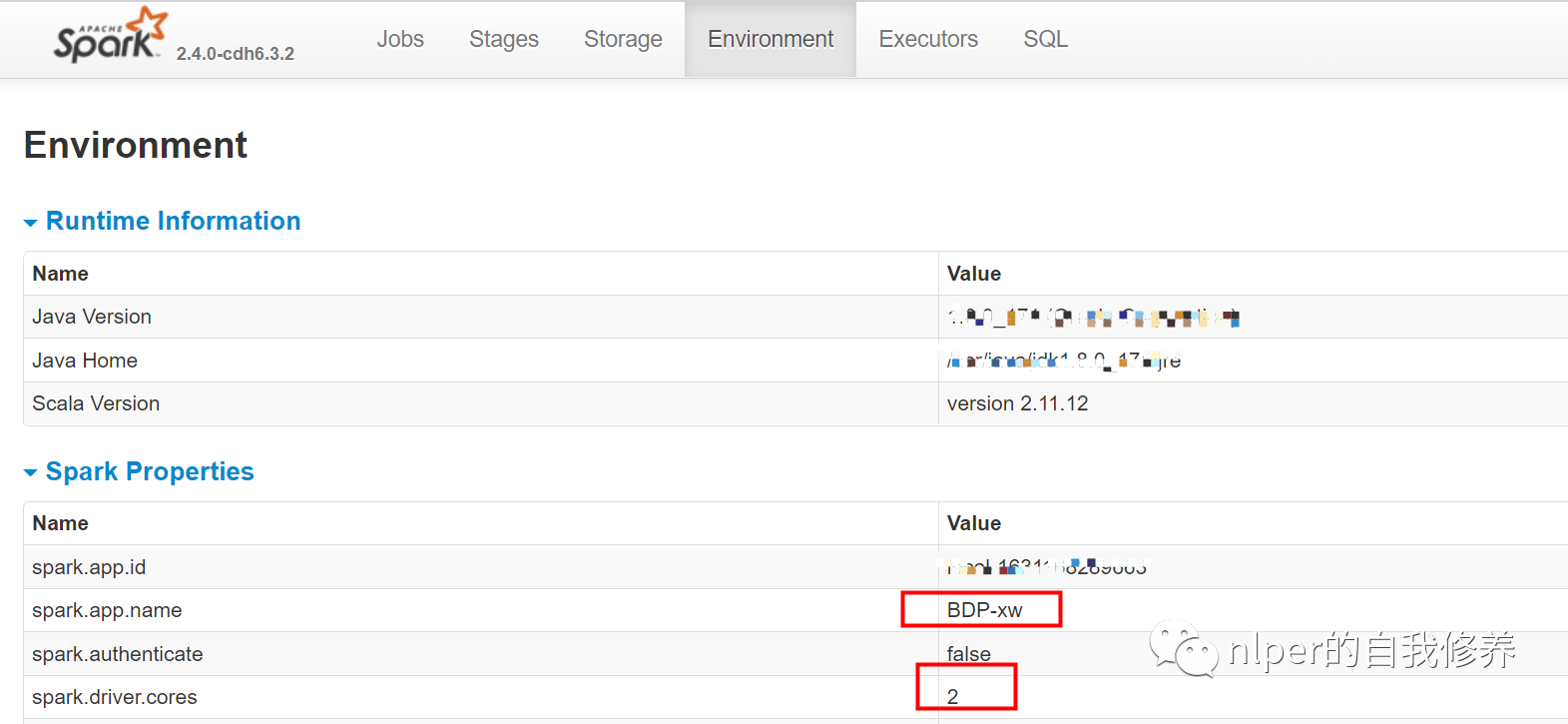
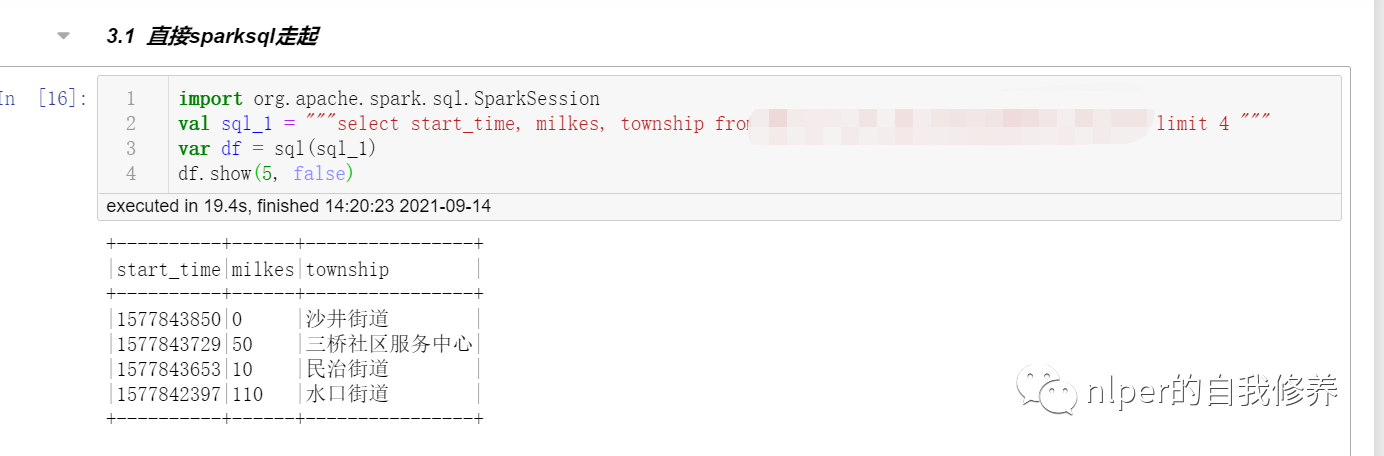
具体示例可以参考文末的
object LoadingData_from_hdfs_base extends mylog{// with Logging ... def main(args: Array[String]=Array("tb1", "3", "\001", "cols", "")): Unit = { if (args.length < 2) { println("Usage: LoadingData_from_hdfs <tb_name, parts. sep_line, cols, paths>") System.err.println("Usage: LoadingData_from_hdfs <tb_name, parts, sep_line, cols, paths>") System.exit(1) } log.warn("开始啦调度") val tb_name = args(0) val parts = args(1) val sep_line = args(2) val select_col = args(3) val save_paths = args(4) val select_cols = select_col.split("#").toSeq log.warn(s"Loading cols are : \n $select_cols") val gb_sql = s"DESCRIBE FORMATTED ${tb_name}" val gb_desc = sql(gb_sql) val hdfs_address = gb_desc.filter($"col_name".contains("Location")).take(1)(0).getString(1) val hdfs_address_cha = s"$hdfs_address/*/" val Cs = new DataProcess_base(spark) val tb_desc = Cs.get_table_desc(tb_name) val raw_data = Cs.get_hdfs_data(hdfs_address) val len1 = raw_data.map(item => item.split(sep_line)).first.length val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString) val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType))) val rawRDD = raw_data.map(_.split(sep_line).map(_.toString)).map(p => Row(p: _*)).filter(_.length == len1) val df_data = spark.createDataFrame(rawRDD, schema1)//.filter("custommsgtype = '1'") val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left") val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)//.limit(100) df_gb_result.show(5, false) ... // spark.stop() } } val cols = "area_name#city_name#province_name" val tb_name = "tb1" val sep_line = "\u0001" // 执行脚本 LoadingData_from_hdfs_base.main(Array(tb_name, "4", sep_line, cols, ""))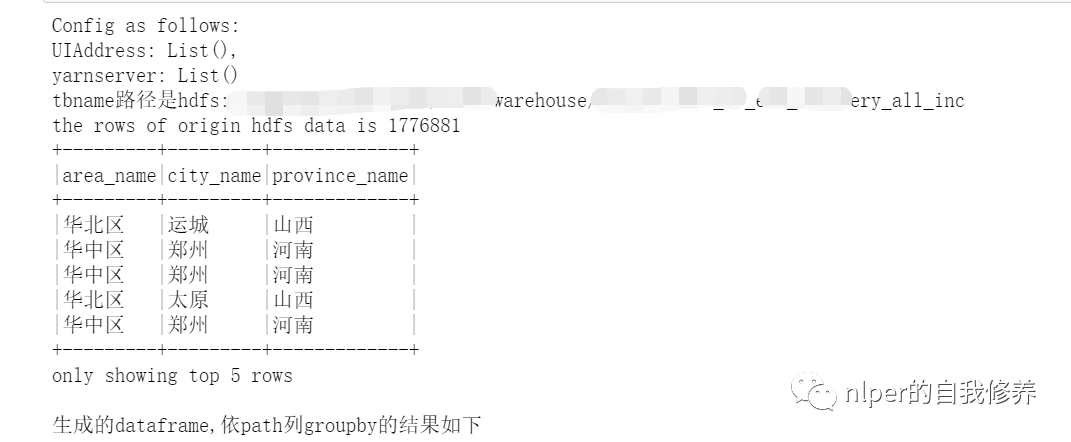
)
判断路径是否为文件夹方式1
def pathIsExist(spark: SparkSession, path: String): Boolean = { val filePath = new org.apache.hadoop.fs.Path( path ) val fileSystem = filePath.getFileSystem( spark.sparkContext.hadoopConfiguration ) fileSystem.exists( filePath ) } pathIsExist(spark, hdfs_address) // 得到结果如下: // pathIsExist: (spark: org.apache.spark.sql.SparkSession, path: String)Boolean // res4: Boolean = true方式2
import java.io.File val d = new File("/usr/local/xw") d.isDirectory // 得到结果如下: // d: java.io.File = /usr/local/xw // res3: Boolean = true 分区表读取源数据对分区文件需要注意下,需要保证原始的hdfs上的raw文件里面是否有对应的分区字段值
如果分区字段在hdfs中的原始文件中,则可以直接通过
若原始文件中,不包括分区字段信息,则需要按照以下方式取数啦
具体示例可以参考文末的
单个文件读取 object LoadingData_from_hdfs_onefile_with_path extends mylog{ def main(args: Array[String]=Array("tb_name", "hdfs:/", "3","\n", "\001", "cols", "")): Unit = { ... val hdfs_address = args(1) val len1 = raw_data.map(item => item.split(sep_line)).first.length val rawRDD = raw_data.flatMap(line => line.split(sep_text)).map(word => (word.split(sep_line):+hdfs_address)).map(p => Row(p: _*)) println(rawRDD.take(2)) val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString) import org.apache.spark.sql.types.StructType val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType))) val new_schema1 = schema1.add(StructField("path", StringType)) val df_data = spark.createDataFrame(rawRDD, new_schema1) val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left") // df_desc.show(false) val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)//.limit(100) df_gb_result.show(5, false) ... // spark.stop() } } val file1 = "hdfs:file1.csv" val tb_name = "tb_name" val sep_text = "\n" val sep_line = "\001" val cols = "city#province#etl_date#path" // 执行脚本 LoadingData_from_hdfs_onefile_with_path.main(Array(tb_name, file1, "4", sep_line, sep_text, cols, ""))