
block是软件概念,一个block只会由一个sm调度,程序员在开发时,通过设定block的属性,告诉GPU硬件,我有多少个线程,线程怎么组织。而具体怎么调度由sm的warps scheduler负责,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个blocks,但需要序列执行。下图显示了GPU内部的硬件架构:

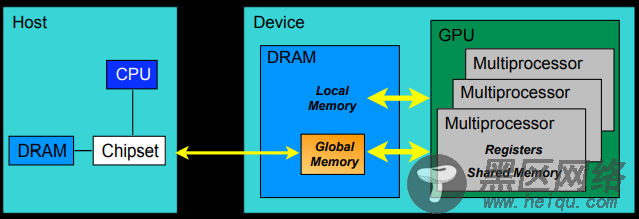
CUDA中的内存模型分为以下几个层次:
每个线程都用自己的registers(寄存器)
每个线程都有自己的local memory(局部内存)
每个线程块内都有自���的shared memory(共享内存),所有线程块内的所有线程共享这段内存资源
每个grid都有自己的global memory(全局内存),不同线程块的线程都可使用
每个grid都有自己的constant memory(常量内存)和texture memory(纹理内存),),不同线程块的线程都可使用
线程访问这几类存储器的速度是register > local memory >shared memory > global memory
下面这幅图表示就是这些内存在计算机架构中的所在层次。
上面讲了这么多硬件相关的知识点,现在终于可以开始说说CUDA是怎么写程序的了。
我们先捋一捋常见的CUDA术语:

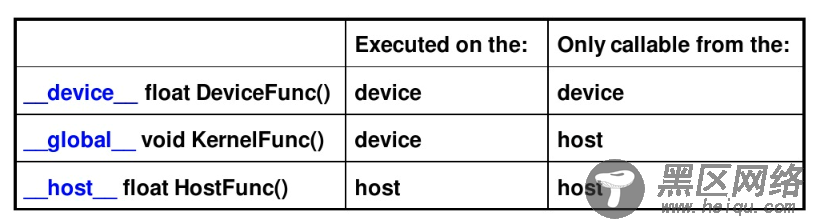
第一个要掌握的编程要点:我们怎么写一个能在GPU跑的程序或函数呢?
通过关键字就可以表示某个程序在CPU上跑还是在GPU上跑!如下表所示,比如我们用__global__定义一个kernel函数,就是CPU上调用,GPU上执行,注意__global__函数的返回值必须设置为void。
第二个编程要点:CPU和GPU间的数据传输怎么写?
首先介绍在GPU内存分配回收内存的函数接口:
cudaMalloc(): 在设备端分配global memory
cudaFree(): 释放存储空间
CPU的数据和GPU端数据做数据传输的函数接口是一样的,他们通过传递的函数实参(枚举类型)来表示传输方向:
cudaMemcpy(void dst, void src, size_t nbytes,
enum cudaMemcpyKind direction)
enum cudaMemcpyKind:
cudaMemcpyHostToDevice(CPU到GPU)
cudaMemcpyDeviceToHost(GPU到CPU)
cudaMemcpyDeviceToDevice(GPU到GPU)
第三个编程要点是:怎么用代码表示线程组织模型?
我们可以用dim3类来表示网格和线程块的组织方式,网格grid可以表示为一维和二维格式,线程块block可以表示为一维、二维和三维的数据格式。
接下来介绍一个非常重要又很难懂的一个知识点,我们怎么计算线程号呢?
1.使用N个线程块,每一个线程块只有一个线程,即 dim3 dimGrid(N); dim3 dimBlock(1);此时的线程号的计算方式就是
threadId = blockIdx.x;其中threadId的取值范围为0到N-1。对于这种情况,我们可以将其看作是一个列向量,列向量中的每一行对应一个线程块。列向量中每一行只有1个元素,对应一个线程。
2.使用M×N个线程块,每个线程块1个线程由于线程块是2维的,故可以看做是一个M*N的2维矩阵,其线程号有两个维度,即:
dim3 dimGrid(M,N); dim3 dimBlock(1);其中
blockIdx.x 取值0到M-1 blcokIdx.y 取值0到N-1这种情况一般用于处理2维数据结构,比如2维图像。每一个像素用一个线程来处理,此时需要线程号来映射图像像素的对应位置,如
pos = blockIdx.y * blcokDim.x + blockIdx.x; //其中gridDim.x等于M 3.使用一个线程块,该线程具有N个线程,即 dim3 dimGrid(1); dim3 dimBlock(N);此时线程号的计算方式为
threadId = threadIdx.x;其中threadId的范围是0到N-1,对于这种情况,可以看做是一个行向量,行向量中的每一个元素的每一个元素对应着一个线程。
4.使用M个线程块,每个线程块内含有N个线程,即 dim3 dimGrid(M); dim3 dimBlock(N);