
这种情况,可以把它想象成二维矩阵,矩阵的行与线程块对应,矩阵的列与线程编号对应,那线程号的计算方式为
threadId = threadIdx.x + blcokIdx*blockDim.x;上面其实就是把二维的索引空间转换为一维索引空间的过程。
5.使用M×N的二维线程块,每一个线程块具有P×Q个线程,即 dim3 dimGrid(M, N); dim3 dimBlock(P, Q);这种情况其实是我们遇到的最多情况,特别适用于处理具有二维数据结构的算法,比如图像处理领域。
其索引有两个维度
threadId.x = blockIdx.x*blockDim.x+threadIdx.x; threadId.y = blockIdx.y*blockDim.y+threadIdx.y;上述公式就是把线程和线程块的索引映射为图像像素坐标的计算方法。
CUDA应用例子我们已经掌握了CUDA编程的基本语法,现在我们开始以一些小例子来真正上手CUDA。
首先我们编写一个程序,查看我们GPU的一些硬件配置情况。
#include "device_launch_parameters.h" #include <iostream> int main() { int deviceCount; cudaGetDeviceCount(&deviceCount); for(int i=0;i<deviceCount;i++) { cudaDeviceProp devProp; cudaGetDeviceProperties(&devProp, i); std::cout << "使用GPU device " << i << ": " << devProp.name << std::endl; std::cout << "设备全局内存总量: " << devProp.totalGlobalMem / 1024 / 1024 << "MB" << std::endl; std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl; std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl; std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl; std::cout << "设备上一个线程块(Block)种可用的32位寄存器数量: " << devProp.regsPerBlock << std::endl; std::cout << "每个EM的最大线程数:" << devProp.maxThreadsPerMultiProcessor << std::endl; std::cout << "每个EM的最大线程束数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl; std::cout << "设备上多处理器的数量: " << devProp.multiProcessorCount << std::endl; std::cout << "======================================================" << std::endl; } return 0; }我们利用nvcc来编译程序。
nvcc test1.cu -o test1输出结果:因为我的服务器是8个TITAN GPU,为了省略重复信息,下面只显示两个GPU结果
使用GPU device 0: TITAN X (Pascal) 设备全局内存总量: 12189MB SM的数量:28 每个线程块的共享内存大小:48 KB 每个线程块的最大线程数:1024 设备上一个线程块(Block)种可用的32位寄存器数量: 65536 每个EM的最大线程数:2048 每个EM的最大线程束数:64 设备上多处理器的数量: 28 ====================================================== 使用GPU device 1: TITAN X (Pascal) 设备全局内存总量: 12189MB SM的数量:28 每个线程块的共享内存大小:48 KB 每个线程块的最大线程数:1024 设备上一个线程块(Block)种可用的32位寄存器数量: 65536 每个EM的最大线程数:2048 每个EM的最大线程束数:64 设备上多处理器的数量: 28 ====================================================== .......第一个计算任务:将两个元素数目为1024×1024的float数组相加。
首先我们思考一下如果只用CPU我们怎么串行完成这个任务。
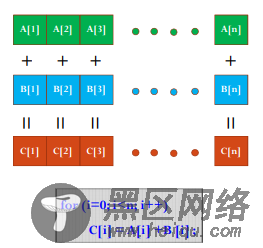
CPU方式输出结果
max_error is 0 total time is 22ms如果我们使用GPU来做并行计算,速度将会如何呢?
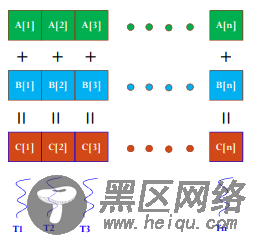
编程要点:
每个Block中的Thread数最大不超过512;