
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
sy: Time spent running kernel code. (system time)
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
根据user+system时间,可以判断CPUs是否繁忙。如果wait I/O一直维持一定程度,说明disk有瓶颈,这时CPUs是"idle"的,因为任务都被block在等待disk I/O中。wait I/O可以被视为另一种形式的CPU idle,并且说明idle的原因就是在等待disk I/O的完成。
处理I/O需要花费system time,在将I/O提交到disk driver之前可能要经过remap, split和merge等操作,并被I/O scheduler调度到request queue。如果处理I/O时平均system time比较高,超过20%,则要进一步分析下,是不是内核处理I/O时的效率有问题。
如果用户空间的CPU使用率接近100%,不一定就代表有问题,可以结合r列的进程总数量看下CPU的饱和程度。
上面示例可以看到在CPU方面有一个明显的问题。user+system的CPU一直维持在50%左右,并且system消耗了大部分的CPU。
4. mpstat -P ALL 1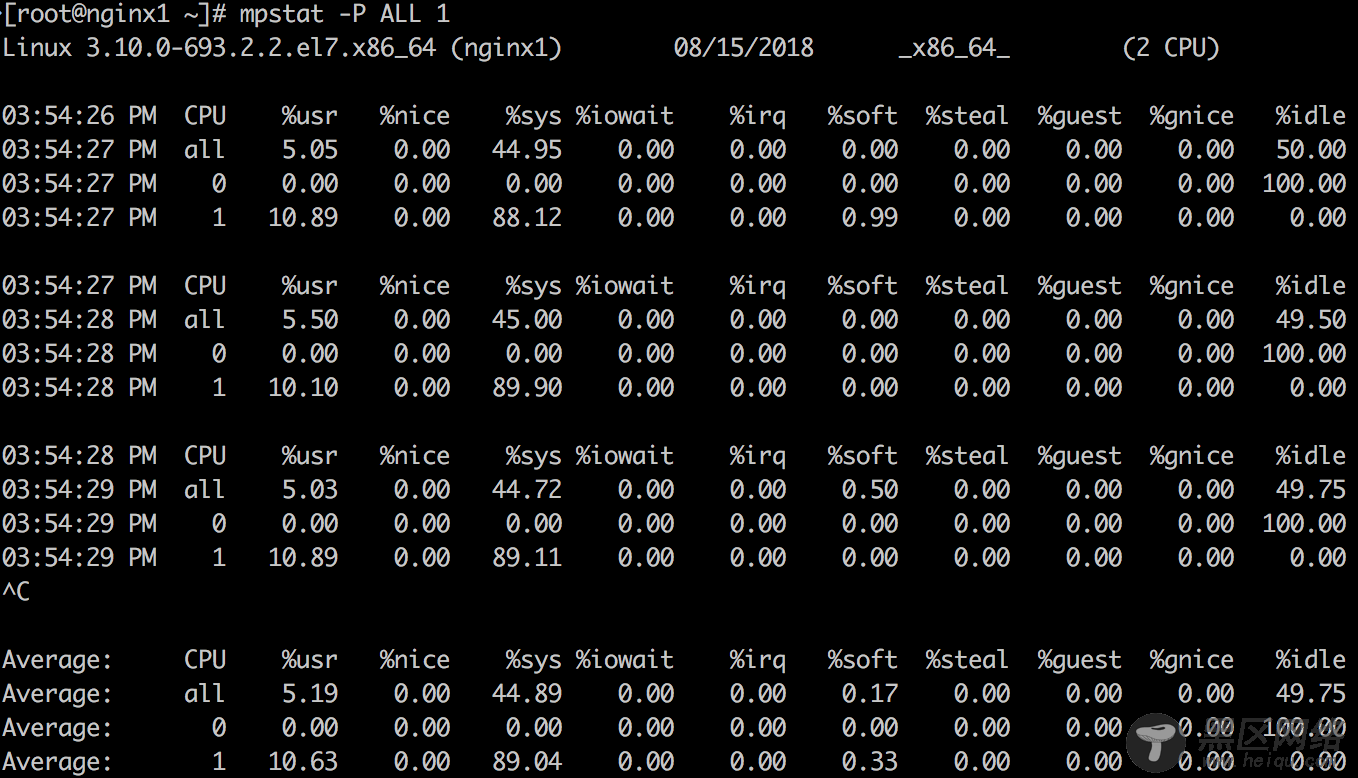
mpstat可以打印按照CPU的分解,可以用来检查不不均衡的情况。
上面示例结果可以印证vmstat中观察到的结论,并且可以看到服务器有2个CPU,其中CPU 1的使用率一直维持在100%,而CPU 0并没有什么负载。CPU 1的消耗主要在内核空间,而非用户空间。
5. pidstat 1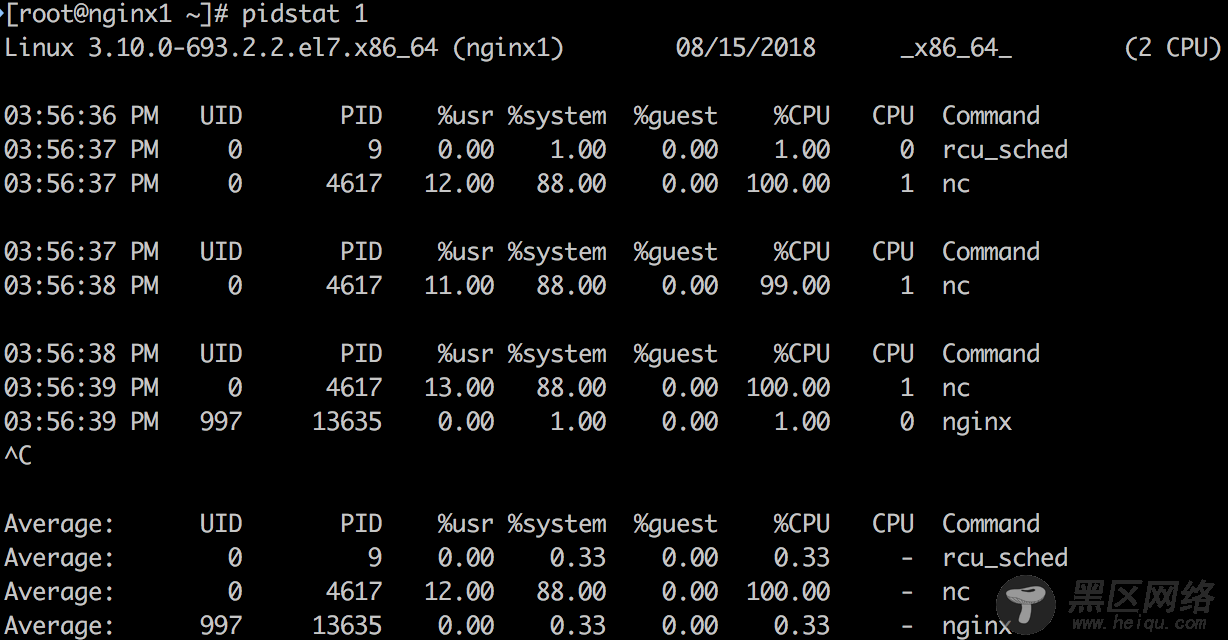
默认pidstat类似于top按照进程的打印方式,不过是以滚动打印的方式,和top的清屏方式不同。利用-p可以打出指定进程的信息,-p ALL可以打出所有进程的信息。如果没有指定任何进程默认相当于-p ALL,但是只打印活动进程的信息(统计非0的数据)。
pidstat不只可以打印进程的CPU信息,还可以打印内存,I/O等方面的信息,如下是比较有用的信息:
pidstat -d 1:看哪些进程有读写。
pidstat -r 1:看进程的page fault和内存使用。没有发生page fault的进程默认不会被打印出来,可以指定-p和进程号来打印查看内存。
pidstat -t: 利用-t查看线程信息,可以快速查看线程和期相关线程的关系。
pidstat -w:利用-w查看进程的context switch情况。输出:
cswch/s: 每秒发生的voluntary context switch数目 (voluntary cs:当进程被block在获取不到的资源时,主动发生的context switch)
nvcswch/s: 每秒发生的non voluntary context switch数目 (non vloluntary cs:进程执行一段时间用完了CPU分配的time slice,被强制从CPU上调度下来,这时发生的context switch)
上面示例中可以明确得看到是nc这个进程在消耗CPU 1 100%的CPU。因为测试系统里消耗CPU的进程比较少,所以一目了然,在生产系统中pidstat应该能输出更多正在消耗CPU的进程情况。
6. iostat -zx 1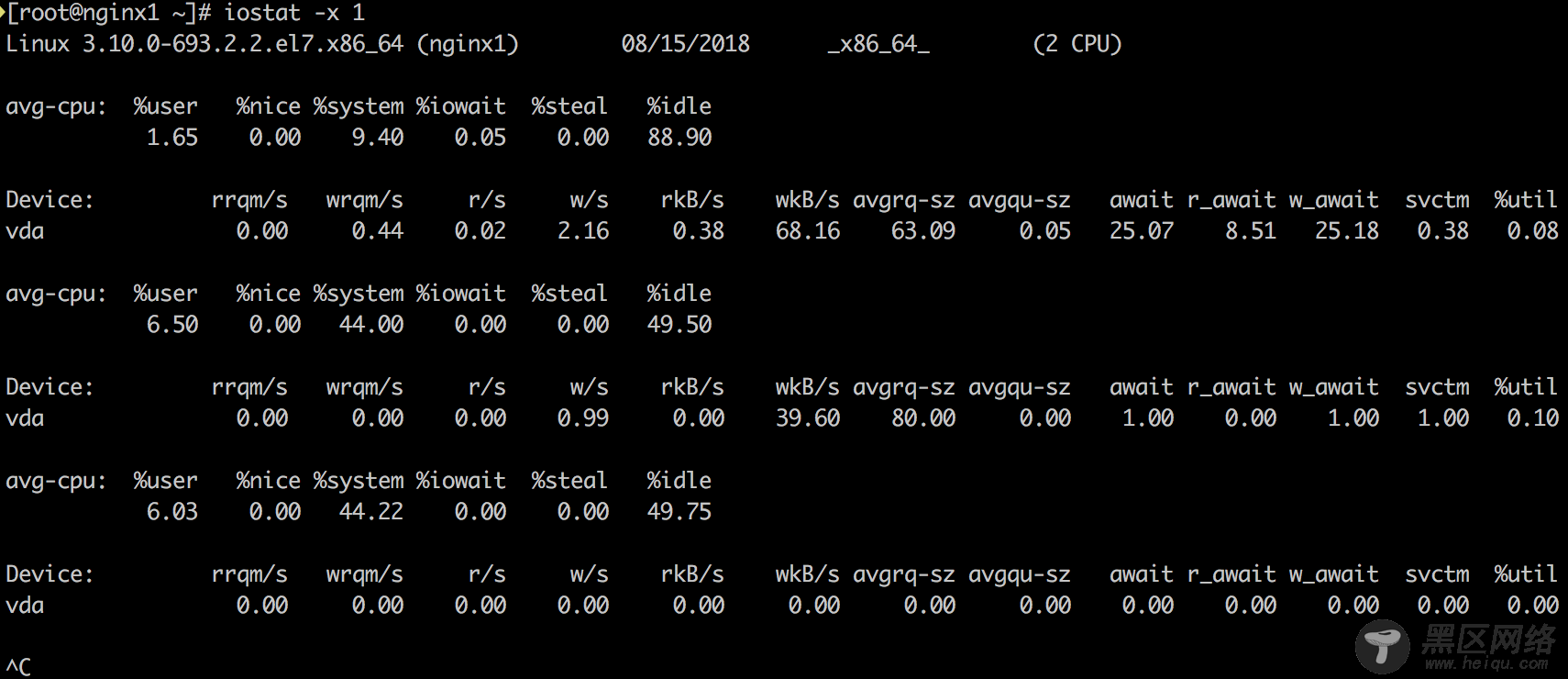
了解块设备(block device, 这里是disk)负载和性能的工具。主要看如下指标:
r/s, w/s, rkB/s, wkB/s:每秒完成的读请求次数(read requests, after merges),每秒完成的写请求次数(write requests completed, after merges),每秒读取的千字节数,每秒写入的千字节数。这些指标可以看出disk的负载情况。���个性能问题可能仅仅是因为disk的负载过大。
await:每个I/O平均所需的时间,单位为毫秒。await不仅包括硬盘设备处理I/O的时间,还包括了在kernel队列中等待的时间。要精确地知道块设备service一个I/O请求地时间,可供iostat读取地内核统计并没有体现,需要用如blktrace这样地跟踪工具来跟踪。对于blktrace来说,D2C的时间间隔代表硬件块设备地service time,Q2C代表整个I/O请求所消耗的时间,即iostat的await。