用 Hadoop 进行分布式数据处理,第 2 部分: 进阶
安装和配置多节点集群
简介: 本 系列 的 用 Hadoop 进行分布式数据处理,第 1 部分:入门 展示了如何在一个单节点集群中使用 Hadoop。本文在此基础之上继续介绍一个更加高级的设置,即使用多个节点进行并行处理。展示了多节点集群所需的各种节点类型,并探讨了一个并行环境中的 MapReduce 功能。本文还深入探究了 Hadoop 的管理方面 — 同时基于命令行和 Web。
相关阅读:
用 Hadoop 进行分布式数据处理,第 1 部分:入门用 Hadoop 进行分布式数据处理,第 2 部分:进阶
用 Hadoop 进行分布式数据处理,第 3 部分:应用程序开发
Hadoop 分布式计算架构的真正实力在于其分布性。换句话说,向工作并行分布多个节点的能力使 Hadoop 能够应用于大型基础设施以及大量数据的处理。本文首先对一个分布式 Hadoop 架构进行分解,然后探讨分布式配置和使用。
根据 用 Hadoop 进行分布式数据处理,第 1 部分:入门,所有 Hadoop 守护进程都在同一个主机上运行。尽管不运用 Hadoop 的并行性,这个伪分布式配置提供一种简单的方式来以最少的设置测试 Hadoop 的功能。现在,让我们使用机器集群探讨一下 Hadoop 的并行性。
根据第 1 部分,Hadoop 配置定义了让所有 Hadoop 守护进程在一个节点上运行。因此,让我们首先看一下如何自然分布 Hadoop 来执行并行操作。在一个分布式 Hadoop 设置中,您有一个主节点和一些从节点(见图 1)。
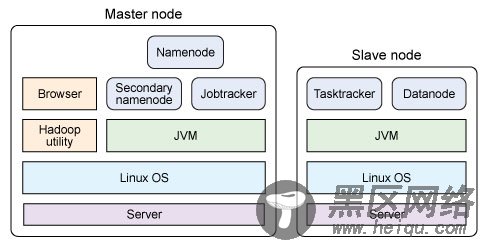
如图 1 所示,主节点包括名称节点、从属名称节点和 jobtracker 守护进程(即所谓的主守护进程)。此外,这是您为本演示管理集群所用的节点(使用 Hadoop 实用程序和浏览器)。从节点包括 tasktracker 和数据节点(从属守护进程)。两种设置的不同之处在于,主节点包括提供 Hadoop 集群管理和协调的守护进程,而从节点包括实现 Hadoop 文件系统(HDFS)存储功能和 MapReduce 功能(数据处理功能)的守护进程。
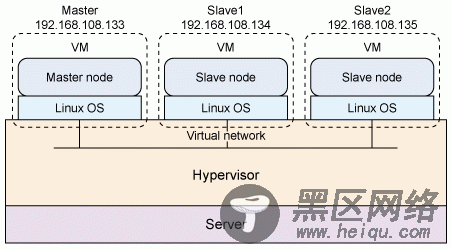
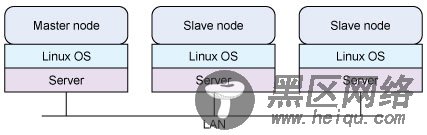
对于该演示,在一个 LAN 上创建一个主节点和两个从节点。设置如图 2 所示。现在,我们来探讨用于多节点分布的 Hadoop 的安装和配置。
为简化部署,要运用虚拟化技术,该技术有几个好处。尽管在该设置中使用虚拟化技术看不出性能优势,但是它可以创建一个 Hadoop 安装,然后为其他节点克隆该安装。为此,您的 Hadoop 集群应显示如下:在一个主机上的虚拟机监控程序上下文中将主从节点作为虚拟机(VM)运行(见图 3)。