
虚拟机及Ubuntu安装
1. 下载并安装 VMware workstation 11
下载地址:https://my.vmware.com/web/vmware/info/slug/desktop_end_user_computing/vmware_workstation/11_0?wd=%20VMware%20workstation%2011%20&issp=1&f=3&ie=utf-8&tn=baiduhome_pg&inputT=1321&rsp=1
2. 下载Ubuntu 14.04,注意在虚拟机上安装之前需要解压!
3.在Vmware中新建虚拟机:虚拟机安装向导,标准,安装盘镜像文件:指向ubuntu 14.04解压的wubi.exe的路径。
4.虚拟机命名,注意保存路径,默认分配磁盘空间20G,虚拟磁盘拆分成多个文件。
虚拟机安装完成后自动启动安装
创建hadoop用户
如果你安装Ubuntu的时候不是用的hadoop用户,那么需要增加一个名为hadoop的用户,并将密码设置为hadoop。
创建用户
sudo useradd hadoop修改密码为hadoop,按提示输入两次密码
sudo passwd hadoop给hadoop用户创建目录,方可登陆
sudo mkdir /home/hadoop sudo chown hadoop /home/hadoop可考虑为 hadoop 用户增加管理员权限,方便部署,避免一些权限不足的问题:
sudo adduser hadoop sudo最后注销当前用户,使用hadoop用户进行登陆。
JDK1.6的安装及配置
1.通过火狐浏览器下载jdk-6u45-linux-x64.bin(以下操作在虚拟机中进行)
sudo cp/home/moweiyang01/Downloads/jdk-6u45-linux-x64.bin /home/hadoop/
sudo chomd u+x jdk-6u45-linux-x64.bin
运行jdk,在/home/hadoop$下:./ jdk-6u45-linux-x64.bin
mv jdk1.6.0_45 jdk 1.6
sudo gedit /etc/profile
加入以下Java的配置信息
export JAVA_HOME=/home/hadoop/jdk1.6
export JRE_HOME=/home/hadoop/jdk1.6/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
保存profile文件
在hadoop下运行 source /etc/profile
输入java -version检查java是否配置成功。
在 /etc/environment 中配置: sudo vim /etc/environment PATH=“/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games: /home/hadoop/jdk1.6/bin”
SSH的配置
输入命令: sudo apt-get install ssh
ssh localhost然后按提示输入密码hadoop,这样就登陆到本机了。但这样的登陆是需要密码的,需要配置成无密码登陆。
先退出刚才的ssh,然后生成ssh证书:
exit # 退出 ssh localhost cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost ssh-keygen -t rsa # 一直按回车就可以 cp id_rsa.pub authorized_keys安装Hadoop 2.5.2
下载后,解压到/usr/local/中。
sudo tar -zxvf ~/Downloads/hadoop-2.5.2.tar.gz -C /usr/local # 解压到/usr/local中 sudo mv /usr/local/hadoop-2.5.2/ /usr/local/hadoop # 将文件名改为hadoop sudo chown -R hadoop:hadoop /usr/local/hadoop # 修改文件权限Hadoop解压后即可使用。输入如下命令Hadoop检查是否可用,成功则会显示命令行的用法:
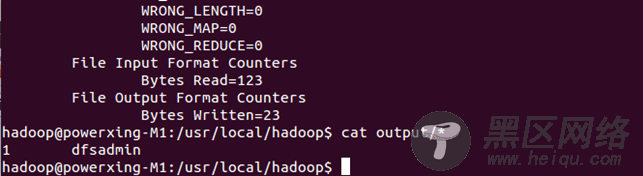
/usr/local/hadoop/bin/hadoop Hadoop单机配置Hadoop默认配置是以非分布式模式运行,即单Java进程,方便进行调试。可以执行附带的例子WordCount来感受下Hadoop的运行。例子将Hadoop的配置文件作为输入文件,统计符合正则表达式dfs[a-z.]+的单词的出现次数。
cd /usr/local/hadoop mkdir input cp etc/hadoop/*.xml input bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar grep input output 'dfs[a-z.]+' cat ./output/*执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词dfsadmin出现了1次
再次运行会提示出错,需要将./output删除。
rm -R ./output Hadoop伪分布式配置